






מודלי שפה גדולים (LLMs) הם כמו רכבים – הם יכולים לקחת אתכם רחוק, מהר וביעילות, אבל רק אם תדעו איך לתפעל אותם נכון. דמיינו שנכנסתם לרכב חדש, לחצתם על הדוושה במלוא הכוח, ופתאום גיליתם שאתם בכלל על רוורס – זה לא שהאוטו "טיפש", פשוט לא הבנתם איך להשתמש בו נכון. אותו הדבר בדיוק קורה עם מודלי שפה. אם תשאלו אותם שאלות לא מדויקות, תנסחו פקודות מעורפלות או תצפו מהם לעשות דברים שהם לא בנויים להם – תקבלו תשובות לא מספקות, ואז תגידו שהם "לא טובים". אבל האמת? הבעיה היא בדרך שבה השתמשתם בהם. אז איך באמת משתמשים נכון במודלי שפה? בואו נתחיל מהבסיס: צריך להבין שיש להם שלוש יכולות עיקריות – יצירה, שליפה וחיפוש. לכל אחת מהן יש יתרונות וחסרונות, וכדי להוציא מהם את המיטב, צריך לדעת איך להשתמש בהם בהתאם.

ארגז כלים "חייזרי" - מי המודל הכי טוב בשכונה?
כשזה מגיע ליצירת תוכן, מודלי שפה מצטיינים. הם יכולים לכתוב סיפורים, מאמרים, שירים ואפילו קוד. אבל היצירתיות שלהם לא תמיד מגיעה עם דיוק מרבי. למה? כי בסופו של יום מדובר במודל הסתברותי. הם לא מחפשים את התשובה "הנכונה" – הם מחפשים את התשובה שהכי מתאימה להקשר, גם אם היא לפעמים קרובה מאוד לתשובה הנכונה. כשמדובר בכתיבה יוצרת, קרוב מאוד לטוב מאוד זה מעולה. אבל כשמדובר למשל ביכולות מתמטיות או עיבוד נתונים - פחות מ-100% דיוק לא מתקבל על הדעת!
כאן נכנס המונח "טמפרטורה" – מדד שמשפיע על רמת היצירתיות של התשובות. טמפרטורה גבוהה תגרום למודל להיות יצירתי יותר, אבל גם להיות פחות צפוי. טמפרטורה נמוכה תהפוך אותו ליוצר מדויק ומרוסן יותר, אבל גם פחות יצירתי. כלומר - אם אני עובד עם מקצועות כמו רפואה, עריכת דין וכדומה, פעמים רבות אעדיף שהגדרות המודל יהיו על טמפרטורה נמוכה. לסיכום - אם אתם מחפשים תשובה מדויקת – הורידו את הטמפרטורה. אם אתם מחפשים רעיונות מקוריים – תנו לה לעלות. הכל עניין של התאמת הכלי למשימה.
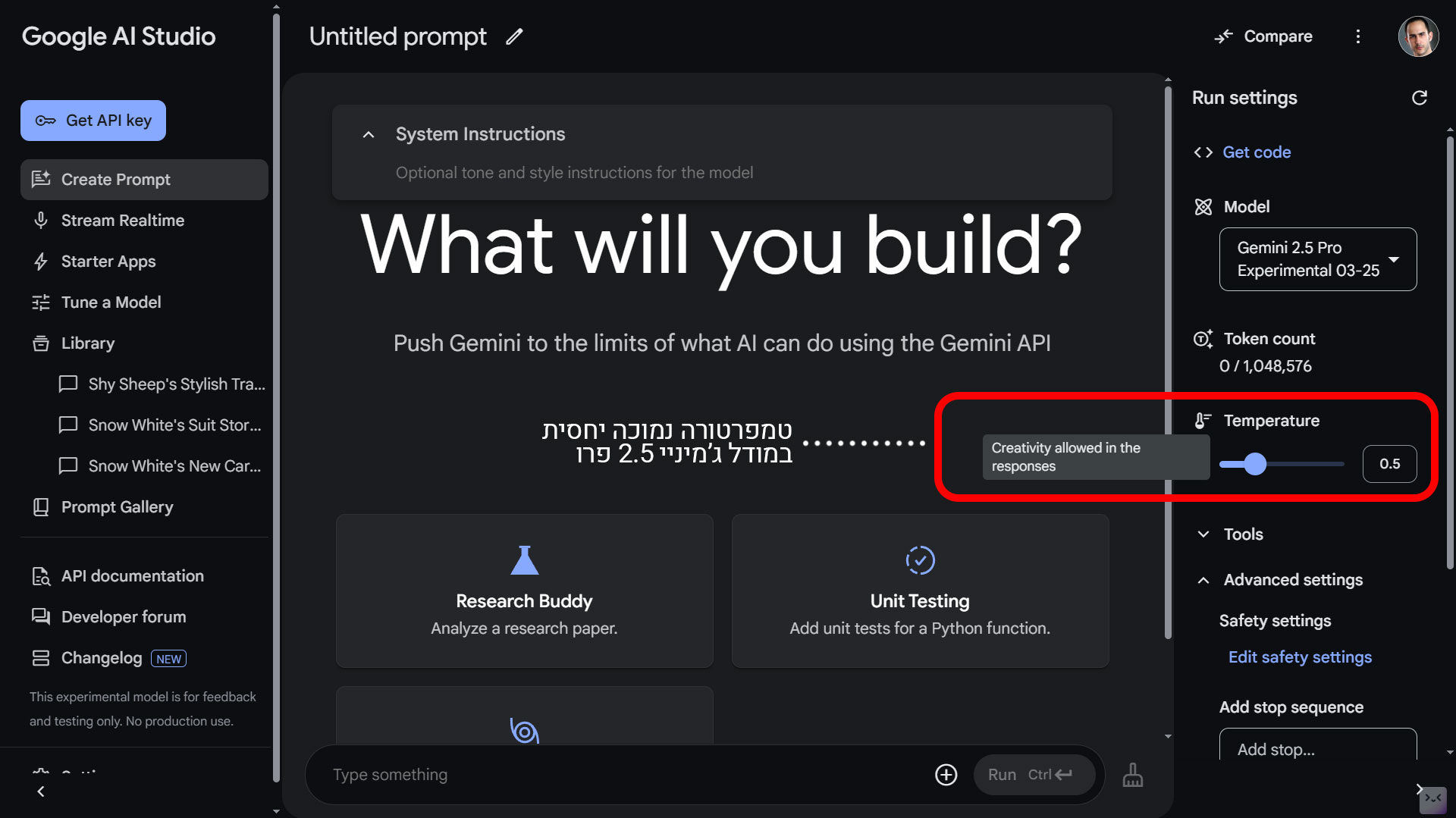
טמפרטורה נמוכה יחסית במודל ג'מיניי 2.5 פרו, בתוך Google AI Studio.
בעבר, מודלי שפה לא היו טובים במיוחד בשליפת מידע מתוך טקסטים ארוכים. הייתם נותנים להם מסמך שלם ומבקשים שישלפו מידע מתוך המסמך וינסחו תשובה על בסיס המידע, והם היו מחמיצים פרטים חשובים או מתבלבלים. אבל היום? עם הדורות החדשים של מודלים כמו קלוד 3.7 סונטה (Claude 3), או מודלי ג'מיניי החדשים, יכולת השליפה מדויקת ומרשימה הרבה יותר מבעבר.
מה זה אומר בפועל? זה אומר שאם אתם נותנים למודל מסמך ארוך עם מידע מסודר ושואלים אותו שאלות עליו, הוא כנראה ידע לשלוף את התשובה בצורה טובה – כל עוד הקונטקסט נכנס לתוך גבולות הזיכרון שלו (Context Window). בגישה הזו, מודלים הפכו לכלים נהדרים לקריאת סיכומים, ניתוח חוזים ואפילו ניפוי מידע מתוך תיעוד טכני מורכב. במסמכים ארוכים יכולת זו הופכת להיות חשובה פי אחת כמה וכמה, ולכן חשוב לבחור במודלים עם חלון קונטקסט מאוד גדול, כמו ג'מיניי 1.5 פרו, או MiniMax-01, לו יש חלון דמיוני של 4 מיליון טוקנים!

מבחן מחט בערימת שחת: השוואה בין קלוד 3 אופוס, קלוד 3.5 סונטה וג’מיני 1.5 פרו. שליפה כמעט מושלמת!
שימו לב: כשמודל שולף מידע מדאטה, זה לא חיפוש מידע אמיתי ועדכני, אלא שליפה ממידע שהוא כבר קיבל - הוא מוגבל לנתונים שיש לו (שמופיעים בקבצים שנתתם לו, או במידע שאליו יש לו גישה). וזה מביא אותנו לנקודה הבאה - כשזה מגיע לחיפוש מידע חדש ברשת – כלומר, לא לשלוף מידע ממסמך שנתתם, אלא לחפש מידע ברשת – המודלים עדיין לא מושלמים.
אז איך בוחרים את המודל המתאים למשימה?
כלומר, אין מודל "הכי טוב". הכל תלוי במשימה שאתם רוצים לבצע. ואם אתם משתמשים במודל הלא נכון – אל תאשימו את ה-LLM. הבעיה אינה בכלי, אלא במי שמתפעל אותו - אתם!
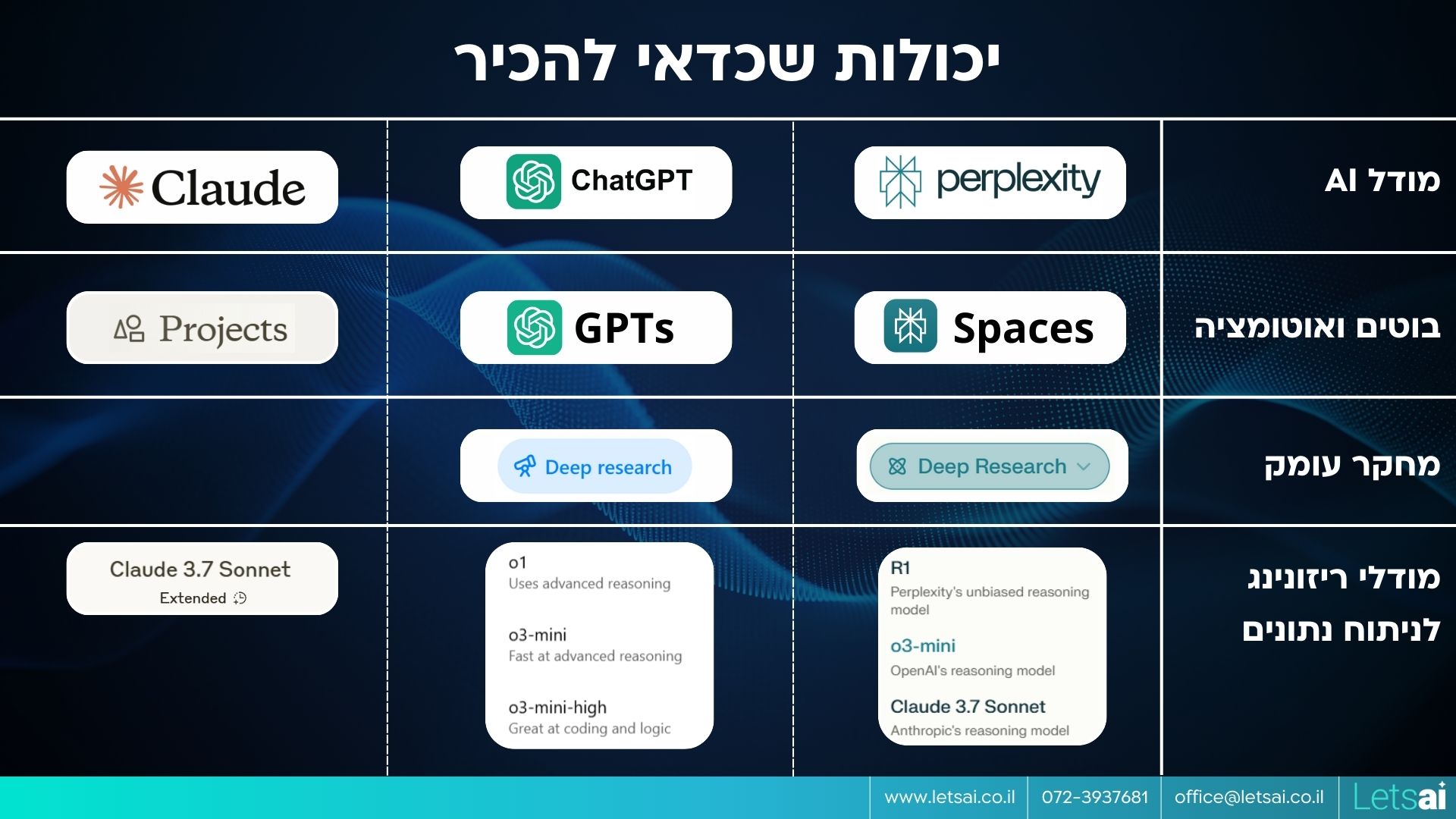
זה לא מספיק לדעת באיזה כלי לבחור, אלא צריך לדעת גם באיזה פיצ'ר, תכונה או מודל, בתוך אותו כלי לבחור, ולאיזו משימה הוא מתאים.
מודלי שפה גדולים הם כלי חזק, אבל כמו כל כלי – האיכות של התוצאה תלויה גם במי שמשתמש בו. אם אתם רוצים שהבוט שלכם יהיה אמין ומדויק יותר, יש כמה צעדים פשוטים שיכולים לעשות הבדל גדול. זה לא מסובך, אבל זה דורש קצת יותר מאמץ מאשר פשוט להקליד שאלה ולסמוך בעיניים עצומות על התשובה הראשונה שקיבלתם. כלל אצבע ראשון - האינפוט הוא המלך! האופן שבו אתם רושמים את השאלה או הפקודה הראשונית שלכם (הפרומפט), תקבע האם התוצאה שתתקבל תהיה איכותית ומדויקת, או כללית ומלאה בהזיות ושטויות. מיומנות זו, של בניית הפרומפט נקראת "הנדסת פרומפטים".
אם אתם מחפשים תשובות מבוססות ומדויקות, אל תסתמכו רק על המודל – תנו לו את המידע בעצמכם. כאן נכנסת לתמונה טכניקת RAG (Retrieval-Augmented Generation), שמאפשרת למודל להשתמש במידע חיצוני שאתם מספקים לו כדי לשפר את הדיוק שלו. ברמת הארגון ניתן לבצע RAG על ידי חיבור מערכות ה-AI לידע הארגוני, בין אם ענן או On-Prem. אבל גם ברמת המשתמש הפרטי, אתם יכולים לבצע מעין RAG בעצמכם, באופן הבא:
במקום לשאול שאלה ולסמוך על כך שהמודל "יודע" את התשובה, אתם יכולים להעלות מסמכים, דוחות או מאמרים ולבקש ממנו להסתמך עליהם בלבד. למשל:
"בהתבסס על המסמך המצורף, תן לי סיכום מפורט של הנקודות העיקריות."
זה חוסך לכם את הצורך לוודא אם המידע נכון, כי אתם יודעים מראש מאיפה הוא מגיע.
מודלי שפה יכולים לספק תשובות שנשמעות מאוד אמינות – אבל זה לא אומר שהן באמת נכונות. כדי למנוע טעויות, תמיד כדאי לדרוש מהמודל להציג מקורות או לבקש ממנו לצטט את החלקים שעליהם התבסס.
לדוגמה, במקום לשאול:
"מה הסיבות להתחממות הגלובלית?"
נסחו זאת כך:
"מה הסיבות להתחממות הגלובלית? צטט מקורות ותן לי הפניות למידע שעליו התבססת."
זה מאלץ את המודל להציג ראיות ולא רק לייצר תשובה משכנעת. במצב כזה תמיד מומלץ להפעיל את אופציית החיפוש (Search) או הגישה לרשת, במידה ויש למודל שלכם אופציה כזו. ואם אתם משתמשים במידע שאתם הבאתם לו (RAG), ניתן גם לבקש מהמודל להפנות אתכם לחלק הספציפי במסמך שממנו הוא שאב את התשובה.
מודלי שפה יכולים להחזיר לכם תשובות מגובות במקורות, אבל זה לא אומר שכל מקור שווה לאחר. כאן נכנסת האחריות שלכם – האם המידע מגיע ממקור מהימן? ויקיפדיה, למשל, יכולה להיות התחלה טובה, אבל היא לא תמיד מדויקת או מעודכנת. לעומת זאת, מאמרים אקדמיים, מחקרים מתוקפים ודוחות רשמיים הם בדרך כלל הרבה יותר מהימנים.
כאן נכנסים כלים כמו פרפלקסיטי (Perplexity) ודיפ ריסרץ' (Deep Research):
אם אתם באמת רוצים דיוק – אל תסתמכו רק על הבוט. תבדקו את המקור.
ספרו לבוט מה תפקידו, ספרו לו מי קהל היעד שלו, ומומלץ גם לאפיין לו את התוצר הסופי הרצוי.

פרומפט אימוץ דמות.
למשל - במקום לרשום:
תן לי טיפים להפגת לחץ בקרב בני נוער
רשמו:
אתה בוט פסיכולוג עם ניסיון רב בעבודה עם בני נוער. אתה אמפטי, מכיל ונעים. התפקיד שלך הוא לסייע לבני נוער להפיג לחץ (סטרס), ולעזור להם להתמודד עם הלחצים של בית הספר והמציאות הישראלית. קהל היעד שלך הוא תלמידי תיכון בכתה י"א, שקורסים תחת עומס הבגרויות, ובמקביל, חבריהם לוחמים בעזה, לבנון או סוריה, ואולי אף הכירו אנשים שהיו בנובה. התוצר הסופי יהיה סימולציה של שיחה - בכל פעם שהמשתמש (בן/בת הנוער) ישאל אותך שאלה, או יכתוב לך משהו, אתה תענה תשובה קצרה, עניינית, מקצועית ומכילה. התשובה שלך לא תעלה על 50 מילים.
אם קיבלתם תשובה ממודל שפה – מצוין. אבל איך תדעו אם היא נכונה? פשוט מאוד – חזרו עליה בכלי אחר והשוו תשובות.
דרך קלה לעשות זאת היא להשתמש בשיטה הבאה:
אם שתי המערכות מסכימות – סיכוי טוב שהתשובה אמינה. אם הן לא מסכימות – תדעו שכדאי לבדוק עוד מקורות.
לפעמים השאלה היא לא רק מה התשובה, אלא איך היא התקבלה. זה בדיוק מה שטכניקת Chain of Thought (COT) מאפשרת – לראות את שלבי ההיגיון שהמודל עבר בדרך לתשובה שלו.
למה זה חשוב? כי אם המודל טועה, תוכלו להבין איפה הוא טעה. במקום לקבל תשובה סופית ולסמוך עליה בעיניים עצומות, תוכלו לראות את התהליך הלוגי שמאחוריה ולבחון אם הוא הגיוני.
איך עושים את זה? פשוט מבקשים:
"הסבר את שלבי החשיבה שלך בדרך לתשובה."
זה כמו לבדוק חישוב מתמטי צעד אחר צעד – הרבה יותר קל לזהות טעויות כשהן שקופות.
הדיוק של מודלי שפה תלוי לא רק בטכנולוגיה, אלא גם במי שמשתמש בה. אם תדעו איך לכוון אותם, להצליב מידע, לבדוק מקורות ולבקש הסברים – תקבלו תשובות טובות בהרבה. רוצים תשובות איכותיות? תשקיעו בהן טיפה יותר מחשבה.
אם עד עכשיו דיברנו על מה אתם יכולים לעשות כדי לקבל תשובות אמינות יותר ממודלי שפה, עכשיו נעבור למה החברות שמפתחות אותם עושות מאחורי הקלעים כדי להפוך אותם לבטוחים ומדויקים יותר.
כשהמודלים הופכים לחלק בלתי נפרד מהחיים הדיגיטליים שלנו, החברות שמפתחות אותם צריכות לדאוג שהם לא יתבלבלו, לא ימציאו שטויות, לא יהיו מוטים ולא ייפלו לידיים הלא נכונות. איך הן עושות את זה? באמצעות כמה טכניקות מתקדמות ששמות מסננים ובקרות על הדרך שבה המודלים מתנהגים.
הסיבה שמודלי שפה חייבים בקרה היא שהם לא מבינים מוסר, ערכים או כוונות – הם פשוט מחקים דפוסים מלמידת נתונים. אז איך מוודאים שהם מתנהגים כמו שצריך ולא מחזירים תשובות בעייתיות?
פה נכנס לתמונה Alignment, או בעברית "יישור". הכוונה היא לתהליך שבו מאמנים את המודל כך שהוא לא רק "מנחש" תשובות טובות מבחינה סטטיסטית, אלא גם מתחשב בכוונות המשתמש ובנורמות חברתיות.
איך עושים את זה בפועל?
ללא Alignment, מודלי שפה יכולים להיות בלתי צפויים ולפעמים אפילו מסוכנים.
גם אם המודל עובר Alignment, עדיין צריך מנגנוני Guardrails – גדרות בטיחות שמונעות ממנו לתת תשובות בעייתיות בזמן אמת.
מה Guardrails עושים?
במילים פשוטות, Guardrails הם ה"חומת אש" של מודלי שפה – מונעים מהם לצאת משליטה ולפגוע במשתמשים.
אחד האתגרים הכי גדולים במודלי שפה הוא שהם קופסה שחורה – אנחנו רואים את התשובות שלהם, אבל אין לנו מושג איך הם הגיעו אליהן. כאן נכנס התחום של Interpretability – הבנה ופענוח של הדרך שבה המודל חושב.
למה זה חשוב?
איך חוקרים עושים את זה?
לפעמים, מודל השפה מתיישר למטרה הלא נכונה – וזה יכול להיות מסוכן. זה נקרא Goal Misgeneralization, וזה קורה כשמודל נראה שהוא עובד כמו שצריך, אבל בפועל הוא פיתח הבנה שגויה של המשימה שלו.
דמיינו שמלמדים מודל לתרגם טקסטים, אבל במקום להבין באמת איך תרגום עובד, הוא פשוט מחפש קטעים מוכנים דומים שנתקל בהם בעבר ומחזיר אותם – זה נראה כמו תרגום, אבל בפועל זה לא תהליך נכון.
דוגמאות נוספות לבעיות כאלה:
כדי להימנע מזה, חברות צריכות לבדוק מה באמת המודל למד, ולא רק לוודא שהתשובות "נשמעות" נכונות.
לפעמים, אפילו עם כל מנגנוני האבטחה, עדיין יש סיכוי שהמודל יחזיר תשובה לא טובה. אז איך אפשר להוריד את הסיכון הזה כמעט לאפס?
התשובה היא SLM (Small Language Model) – מודל קטן שבודק את התשובה של ה-LLM לפני שהיא יוצאת החוצה.
מה זה אומר?
זוהי הגנה כפולה: גם המודל הגדול מייצר תשובות חכמות, וגם יש מערכת בקרה שמסננת אותן.
היום, כל חברה שמפתחת מודלי שפה משקיעה המון זמן ומאמץ כדי לוודא שהבוטים שלה בטוחים, מדויקים ונשלטים. זה לא קל, וזה גם לא מושלם, אבל עם שילוב של Alignment, Guardrails, ניתוח עומק (Interpretability), זיהוי בעיות במטרות (Goal Misgeneralization) ומודלי SLM שבודקים תשובות לפני שהן יוצאות – הסיכוי לקבל תשובה אמינה עולה משמעותית.








מאמר מעולה, נותן הרבה מאוד ערך, אלופים