




DeepSeek הסינית הסעירה לאחרונה את עולם הבינה המלאכותית כשהציגה מודל שמתחרה ביכולות של ChatGPT במחיר נמוך משמעותית. בעוד התקשורת התמקדה בסנסציות ובכותרות מרעישות, מאחורי הקלעים מסתתר סיפור מרתק של חדשנות, אתגרים ושינוי בכללי המשחק של תעשיית ה-AI. כעת, כשהאבק שוקע, הגיע הזמן לצלול מעבר לכותרות ולהבין את המשמעות האמיתית של התופעה הזו. נפרק את המיתוסים הנפוצים, נחשוף את העלויות האמיתיות מאחורי הפיתוח, ונבחן את הקשר המורכב בין DeepSeek למתחרותיה המערביות. נתמודד עם שאלות קריטיות על פרטיות ואבטחת מידע, ונספק מדריך מעשי שיעזור לכם להבין את המודל הזה לעומק וגם לנווט בביטחון בעולם המשתנה במהירות של כלי AI מתקדמים. בעידן שבו כל יום מביא איתו "מהפכה" חדשה, חשוב להבין מה באמת משמעותי ומה סתם רעש רקע. זה בדיוק מה שננסה לעשות כאן.
בשנת 2024 החלה DeepSeek את דרכה עם גרסה ראשונה שהייתה מבוססת על ארכיטקטורת טרנספורמר מסורתית והורכבה מ-67 מיליארד פרמטרים. מודל זה התבסס בעיקר על רשתות עצביות מסוג feedforward והניח את היסודות להתפתחות המודלים הבאים. הארכיטקטורה כללה מנגנון תשומת לב (attention mechanism) משופר שאפשר למודל לעבד טקסט ארוך יותר ביעילות, יחד עם שכבות נורמליזציה מתקדמות שתרמו ליציבות האימון. המודל אומן על מגוון רחב של נתונים טקסטואליים בשפות שונות, כולל קוד תכנות ומסמכים טכניים, מה שהעניק לו יכולות בסיסיות בהבנת שפה טבעית ובפתרון בעיות. למרות מגבלותיו הראשוניות, מודל זה היווה פריצת דרך משמעותית עבור החברה והציב תשתית איתנה להתפתחויות העתידיות בתחום.
ביוני 2024 הציגה DeepSeek קפיצת מדרגה משמעותית עם השקת גרסה 2 של המודל, המכילה 236 מיליארד פרמטרים. הגרסה החדשה מביאה איתה שני חידושים טכנולוגיים פורצי דרך: ראשית, Multi-head Attention, שמאפשר למודל לעבד מידע בצורה מדויקת ועמוקה יותר. שנית, וחשוב לא פחות, המודל משתמש בטכנולוגיית Mixture of Experts) MoE) - גישה חדשנית שמחלקת את המודל למספר "מומחים" וירטואליים, כשכל אחד מתמחה בתחום ספציפי. כך, במקום להפעיל את כל המודל בכל פעם, רק המומחים הרלוונטיים למשימה מופעלים, מה שמוביל לשיפור דרמטי במהירות העיבוד ולהפחתה משמעותית בעלויות החישוב.
דצמבר 2024 סימן נקודת מפנה בהתפתחות DeepSeek עם השקת גרסה 3, שהביאה עימה שלושה חידושים מהפכניים. ראשית, המודל הורחב באופן דרמטי ל-671 מיליארד פרמטרים, מה שהעניק לו יכולות עיבוד והבנה מתקדמות משמעותית. שנית, המודל שודרג עם מנגנון למידה מחיזוק (Reinforcement Learning), המאפשר לו לשפר את יכולות ההיגיון שלו באופן עצמאי דרך תהליך של ניסוי וטעייה - בדומה לאופן שבו בני אדם לומדים מניסיון. לבסוף, הוכנס מנגנון חכם לאיזון עומסים בין מעבדי H800 מרובים, מה שאפשר ניצול יעיל יותר של משאבי החישוב והפעלה חלקה של המודל בסביבות מורכבות.
ינואר 2025 הביא עמו התפתחות משמעותית בתחום מודלי ההיגיון של DeepSeek עם השקת שני מודלים פורצי דרך. הראשון, DeepSeek R1-Zero, היה חדשני במיוחד בכך שהתבסס אך ורק על למידה מחיזוק (Reinforcement Learning). המודל השני, DeepSeek R1, לקח את היסודות של R1-Zero צעד קדימה על ידי שילוב מתוחכם של למידה מחיזוק עם כוונון עדין בהשגחה ("Supervised Fine-Tuning or "SFT). התוצאה היא מודל היגיון מתקדם שלא רק מציג ביצועים מרשימים בפתרון בעיות מורכבות, אלא גם עושה זאת בשקיפות מלאה, תוך שמירה על יעילות תפעולית וחיסכון משמעותי בעלויות.
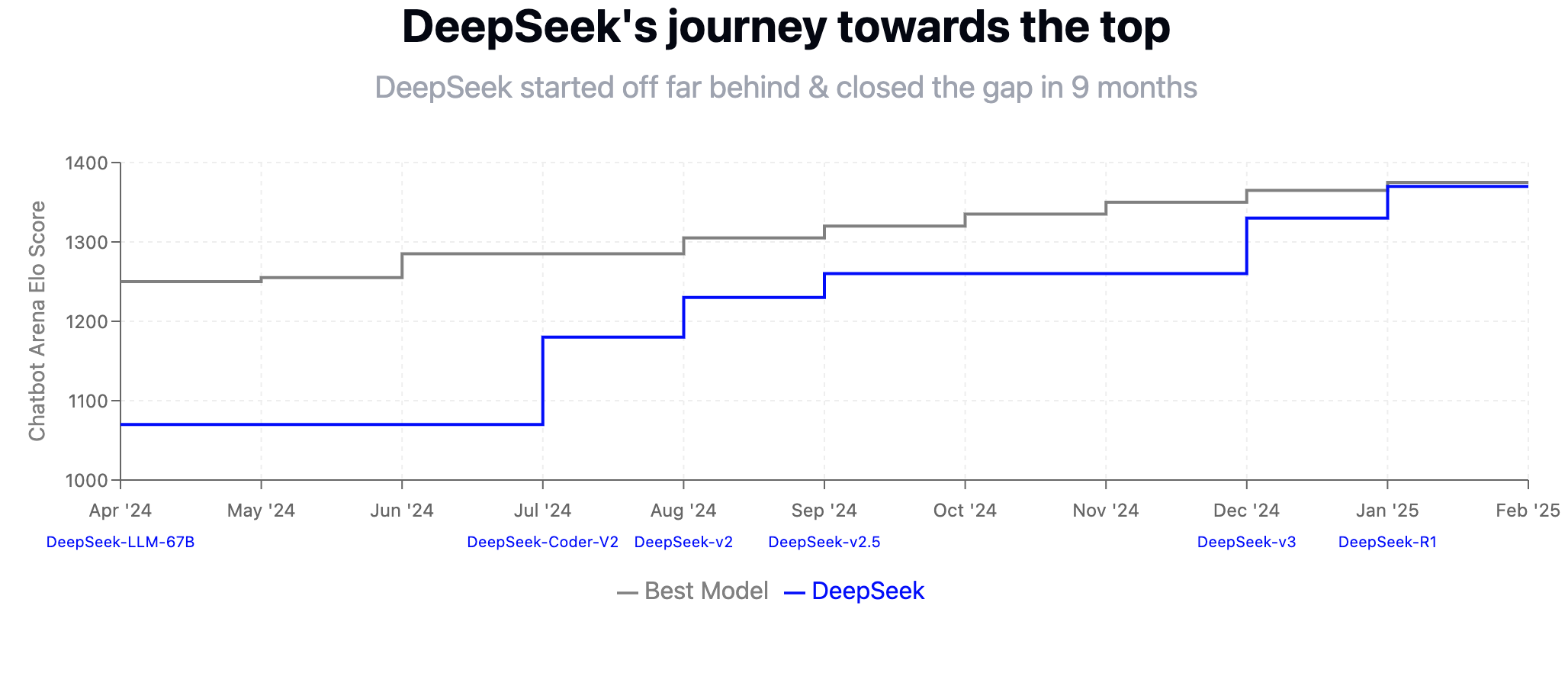
DeepSeek התחילה באפריל 2024 עם ציון Elo נמוך יחסית של כ-1100 עם המודל DeepSeek-LLM-67B, כשמעליה ניצב המודל המוביל בתעשייה בציון של כ-1250. הקפיצה המשמעותית הראשונה הגיעה ביולי 2024 עם השקת DeepSeek-Coder-V2, ומאז המשיכה החברה בשיפור עקבי דרך גרסאות v3, v2.5, v2, עד להשקת R1 בינואר 2025. תוך תשעה חודשים בלבד, DeepSeek צמצמה את הפער מול המודל המוביל בתעשייה וטיפסה מציון 1100 לכמעט 1400, הישג מרשים שממחיש את קצב ההתקדמות המהיר של החברה. Chatbot Arena Elo Score הוא מדד מקובל בתעשיית הבינה המלאכותית להערכת ביצועי מודלי שפה. המדד מבוסס על מערכת הדירוג Elo, שפותחה במקור עבור משחק השחמט, ומשמשת כיום להשוואת ביצועים של צ'אטבוטים.
הגרף מטה מתאר את המסע של DeepSeek לצמרת תעשיית הבינה המלאכותית ומדגים סיפור מרתק של התקדמות מטאורית:
אחד המאפיינים המהפכניים של DeepSeek R1 הוא הגישה הייחודית שלו לפתרון בעיות, המזכירה את דרך החשיבה האנושית. בניגוד למודלים מסורתיים שמספקים תשובה סופית ללא הסבר, R1 חושף את כל תהליך החשיבה שלו בשקיפות מלאה. המודל מתחיל בפירוק מעמיק של הבעיה, מנתח אותה מכל זווית אפשרית, ומציג את כל שלבי הביניים בדרך לפתרון. זה כמו להציץ לתוך "מוח" המודל ולראות כיצד הוא מגיע למסקנות שלו - החל מהתובנות הראשוניות, דרך החישובים והניתוחים, ועד לתשובה הסופית. גישה זו לא רק מגבירה את האמון במודל, אלא גם מאפשרת למשתמשים ללמוד מתהליך החשיבה שלו ולהבין טוב יותר את הלוגיקה מאחורי כל החלטה.
במרכז החדשנות של DeepSeek R1 עומד מנגנון למידה מחוזק מתקדם, המדמה את האופן שבו בני אדם לומדים מניסיון. בדומה לילד שלומד לרכוב על אופניים דרך ניסוי וטעייה, המודל מקבל "חיזוקים חיוביים" כשהוא מגיע לתוצאות נכונות, ללא תלות בדרך שבה הגיע אליהן. מה שהופך את השיטה הזו למיוחדת במיוחד היא יכולת הלמידה העצמאית של המודל. במקום להסתמך על הוראות מפורשות או כללים קבועים מראש, R1 מפתח בעצמו אסטרטגיות פתרון אופטימליות. זה מאפשר למודל להשתפר באופן מתמיד, לגלות דרכים חדשות ויעילות יותר לפתרון בעיות, ולהתאים את עצמו למגוון רחב של אתגרים - בדיוק כמו מוח אנושי שלומד ומתפתח מתוך התנסות.
אחד היתרונות המשמעותיים של DeepSeek R1 טמון בשימוש המתוחכם בארכיטקטורת תערובת מומחים (Mixture of Experts). במקום להפעיל מודל ענק אחד לכל משימה, המערכת מחולקת למספר "מומחים" וירטואליים - תת-רשתות שכל אחת מתמחה בתחום ספציפי. כשמגיעה משימה חדשה, במקום להפעיל את כל המערכת, רק המומחים הרלוונטיים נכנסים לפעולה. זה כמו צוות מומחים שכל אחד תורם את הידע הספציפי שלו כשצריך, במקום שכולם יעבדו על כל משימה. התוצאה היא חיסכון דרמטי במשאבי חישוב וזמני תגובה מהירים יותר. אמנם חברות אחרות כמו Mistral הצרפתית ו-IBM משתמשות גם הן בטכנולוגיה דומה, אך DeepSeek הצליחה למקסם את הפוטנציאל של הגישה הזו באופן יוצא דופן, מה שתורם לביצועים המרשימים של המודל תוך שמירה על יעילות תפעולית גבוהה.
תהליך הזיקוק (Distillation) מהווה אחד החידושים המשמעותיים בארסנל הטכנולוגי של DeepSeek. בדומה למורה המעביר את הידע שלו לתלמיד, המודל הגדול R1-Zero משמש כ"מורה" שמעביר את התובנות והיכולות שלו למודלים קטנים יותר. אך זה לא רק תהליך של דחיסת מידע - זוהי טרנספורמציה מורכבת שבה מודל המבוסס על ארכיטקטורת תערובת מומחים (MoE) מעביר את הידע שלו למודל טרנספורמר מסורתי, כדוגמת סדרת Llama. התוצאה היא מודלים קטנים יותר שמשמרים את יכולות ההיגיון המתקדמות של המודל המקורי, אך דורשים פחות משאבי חישוב ומגיבים מהר יותר. זוהי דוגמה מצוינת לאיך חדשנות טכנולוגית יכולה להוביל ליעילות כלכלית - המודלים המזוקקים מאפשרים לארגונים ליהנות מיכולות AI מתקדמות בעלות נמוכה יותר ובביצועים משופרים.
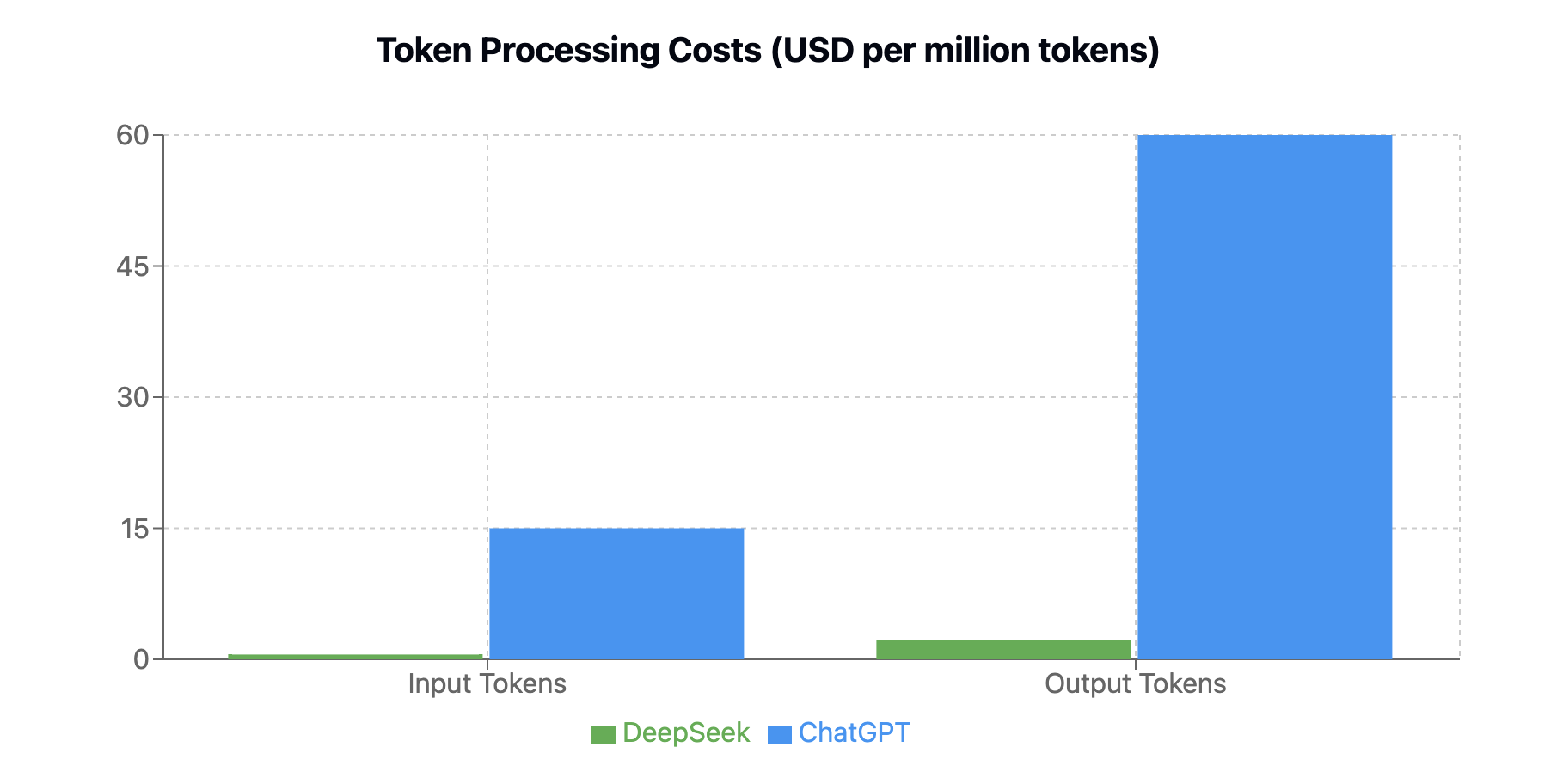
אחד המספרים שזכה לתהודה רבה בתקשורת הוא עלות האימון המדווחת של המודל - 5.6 מיליון דולר בלבד. אבל כמו שקורה לעתים קרובות בכותרות מושכות, המספר הזה מספר רק חלק קטן מהסיפור. העלות הזו מתייחסת אך ורק להרצה הסופית של אימון המודל, בדומה לעלות ההרכבה הסופית של iPhone - שהיא רק חלק זניח מהעלות האמיתית של פיתוח המכשיר. כשמסתכלים על התמונה המלאה, DeepSeek מחזיקה בצי עצום של 50,000 כרטיסי מעבד גרפי מסוג Nvidia Hopper, שערכם מוערך בכמיליארד דולר. לזה יש להוסיף את עלויות התשתית, המחקר והפיתוח, צוותי המהנדסים, ושלל הוצאות נוספות שנדרשות כדי להביא מודל בינה מלאכותית מתקדם לשוק. בדיוק כפי שהעלות האמיתית של פיתוח iPhone כוללת מחקר, פיתוח, תכנון, שרשרת אספקה ועוד - כך גם העלות האמיתית של פיתוח מודל AI מתקדם היא הרבה מעבר לעלות ההרצה הסופית של האימון. בשורה התחתונה, עבור משתמש הקצה, עלות המודל עבור החברה המפתחת פחות רלוונטית, מה שרלוונטי הוא המחיר ופערי המחיר למשתמש במקרה הזה הם מדהימים - ChatGPT יקר פי 27!
גרף השוואת מחירים של DeepSeek ו-ChatGPT מראה פערים משמעותיים בעלויות עיבוד טקסט. בעוד ש-ChatGPT גובה $15 למיליון טוקנים בקלט ו-$60 למיליון טוקנים בפלט, DeepSeek מציע מחירים נמוכים משמעותית: $0.55 בלבד למיליון טוקנים בקלט ו-$2.19 למיליון טוקנים בפלט:
מיתוס נפוץ נוסף טוען שהצלחתה של DeepSeek נובעת מהפרת כללי בקרת הייצוא, אך האמת מפתיעה ומרתקת הרבה יותר. דווקא המגבלות הרגולטוריות הובילו את החברה לחדשנות יוצאת דופן. בעוד שחברות אמריקאיות יכולות להשתמש בכרטיסי המעבד החזקים ביותר מסוג H100 של Nvidia, ב- DeepSeek נאלצו להסתפק בדגם H800 - גרסה מוחלשת שאושרה למכירה בסין. במקום לנסות לעקוף את המגבלות, החברה השקיעה בפיתוח שיטות מתוחכמות לייעול ארכיטקטורת המודל שלה. זה מזכיר את האסטרטגיה של סמסונג, שמשתמשת במעבדים שונים במכשיריה בהתאם למגבלות רגולטוריות באזורים שונים בעולם. למעשה, מומחים רבים טוענים שאילו DeepSeek הייתה מקבלת גישה לכרטיסי H100 החזקים יותר, היא הייתה יכולה להשיג תוצאות מרשימות אף יותר. העובדה שהחברה הצליחה להגיע להישגים משמעותיים עם חומרה מוגבלת יותר רק מדגישה את היצירתיות והחדשנות הטכנולוגית שלה, ולא פחות חשוב - את מחויבותה לפעול במסגרת החוקית.
המיתוס השלישי נוגע לטענה ש- DeepSeek "ניצחה" את OpenAI, אבל המציאות מורכבת יותר ומחייבת הבנה מעמיקה של ההבדל בין יעילות לביצועים מקסימליים. חשבו על זה כמו על אימון בחדר כושר: אפשר להתאמן שעתיים כדי למקסם את בניית השרירים, או להסתפק ב-45 דקות שישיגו 80% מהתוצאות. באופן דומה, המודל R1 של DeepSeek אכן משיג ביצועים דומים למודל o1 של OpenAI, אך OpenAI כבר הציגה את o3, שמציע יכולות מתקדמות יותר. למעשה, DeepSeek הצטיינה באופטימיזציה של יעילות - היכולת להשיג תוצאות טובות מאוד במשאבים מצומצמים יותר. התחרות הזו דחפה את OpenAI להגיב, והם השיקו את o3 mini בחינם, כולל יכולות חיפוש - מהלך שייתכן שלא היה קורה ללא הלחץ התחרותי מצד DeepSeek. זה דומה לשוק הסמארטפונים: אם מכשיר הדגל של iPhone עולה 1,000-2,000 דולר ומציע את הביצועים הטובים ביותר, מכשיר שמשיג 90% מהביצועים במחיר של 200 דולר הוא הישג מרשים - אבל זה לא אומר שהוא "ניצח" את המכשיר היקר יותר. DeepSeek הצליחה להוביל במרוץ היעילות, אבל OpenAI עדיין מחזיקה ביתרון מבחינת היכולות המקסימליות.
כשמדברים על השוואה בין מודלים של בינה מלאכותית, חשוב להבין שלא כל השוואה היא רלוונטית או הוגנת. DeepSeek מציעה מספר מודלים שונים, כשכל אחד מהם מתחרה בקטגוריה אחרת: המודל הבסיסי V3 מתחרה מול ChatGPT-4o, בעוד שמודל ההיגיון R1 פועל בקטגוריה אחרת לגמרי. מה שמעניין במיוחד הוא היכולת לשלב חיפוש עם מודל ההיגיון R1 של DeepSeek - יכולת שלא הייתה קיימת במקבילה של ChatGPT (o1) עד לאחרונה. רק עם השקת o3-mini, הצליחה OpenAI להדביק את הפער הזה ולהציע גם חיפוש משולב. זה בדיוק כמו ההבדל בין מכונית ספורט ל-SUV - שניהם כלי רכב מצוינים, אבל נועדו למטרות שונות לחלוטין ומצטיינים בתחומים שונים. לכן, כשמשווים מודלי AI, חיוני להבין את הקטגוריה המדויקת ולהשוות "תפוח לתפוח" ולא תפוח לתפוז.
חשוב להבהיר נקודה מרכזית בנוגע ליכולת הצפייה בתהליך החשיבה של DeepSeek R1. בעוד שזו תכונה מרשימה ופופולרית, היא בעצם משקפת החלטת עיצוב ולא יתרון טכנולוגי אמיתי על פני ChatGPT o1. שני המודלים מפעילים תהליכי היגיון דומים - ההבדל העיקרי הוא ש- DeepSeek בחרה לחשוף את תהליך החשיבה למשתמשים. זה בדיוק כמו ההבדל בין שני שפים מוכשרים באותה המידה: אחד מבשל במטבח סגור והשני בדוכן הדגמה פתוח. התבשיל הסופי והמיומנות זהים, אבל היכולת לצפות בתהליך ההכנה מוסיפה שכבה של שקיפות ועניין לחוויית המשתמש. אמנם השקיפות הזו זכתה לפופולריות רבה בקרב המשתמשים, אך חשוב להבין שהיא משקפת בחירה בממשק המשתמש ולא עליונות טכנולוגית.
אחת הטענות המעניינות ביותר סביב DeepSeek נוגעת למקור היכולות שלהם. החברה מצהירה שהשתמשה בטכניקה הנקראת Model Distillation, תהליך שבו הם למדו מהפלטים של ChatGPT כדי לאמן את המודלים שלהם. זה כמו יצרן טלפונים שלומד לעבד תמונות על ידי ניתוח של מיליוני תמונות שצולמו ב-iPhone - במקום להעתיק את הקוד עצמו, הם לומדים מהתוצאות. בעוד שהשיטה הזו נפוצה בתעשיית הבינה המלאכותית ואינה מפרה חוקים, היא בהחלט מפרה את תנאי השימוש של OpenAI. מה שמעניין במיוחד הוא שלמרות שמיקרוסופט ו-OpenAI חוקרות כרגע את DeepSeek, מיקרוסופט כבר הכניסה את מודל R1 לשירותי הענן שלה - מה שמדגיש את המורכבות של הסוגיה ואת האופן שבו גבולות החדשנות והקניין הרוחני מיטשטשים בעידן הבינה המלאכותית.
האם DeepSeek מסכן את הפרטיות שלנו? התשובה מורכבת יותר ממה שנדמה. נכון, כשמשתמשים באפליקציה הרשמית של DeepSeek, הנתונים אכן נשמרים בשרתים בסין. אבל היום יש מגוון אפשרויות שמאפשרות ליהנות מהיכולות המרשימות של המודל תוך שמירה על פרטיות. למשל, פלטפורמות כמו Perplexity מאפשרות גישה למודלים של DeepSeek תוך שמירת הנתונים בשרתים אמריקאיים. יתרה מזאת, המחיר האטרקטיבי של המודלים מושך יותר ויותר פלטפורמות להטמיע אותם - Cursor היא רק דוגמה אחת מיני רבות. למי שמחפש פרטיות מקסימלית, קיימת אפילו אפשרות להריץ את המודלים באופן מקומי על המחשב האישי באמצעות כלים כמו Ollama. כך שבסופו של דבר, רמת האבטחה תלויה בבחירות שלכם - אפשר ליהנות מהיכולות של DeepSeek במגוון דרכים שמתאימות לדרישות האבטחה האישיות שלכם.
לא ממש וממש לא. הרעיון שהיעילות המשופרת של DeepSeek תפגע בעסקי Nvidia הוא פשוט שגוי, ולמעשה, ייתכן שההפך הוא הנכון. התופעה הזו מוכרת כפרדוקס Jevons - ככל שמוצר נעשה יעיל יותר וזול יותר, כך גדל השימוש הכולל בו. מנכ"ל מיקרוסופט ואנליסטים טכנולוגיים רבים מאמינים שככל שפתרונות AI יהפכו ליעילים וזולים יותר, כך יגדל הביקוש הכולל לטכנולוגיה הזו. זה דומה למה שקרה בשוק הסמארטפונים - כשהמחירים ירדו, יותר אנשים קנו טלפונים חכמים, מה שדווקא הגדיל את הביקוש למעבדים איכותיים של חברות כמו Qualcomm. במילים אחרות, היעילות המשופרת של DeepSeek עשויה דווקא להגדיל את השוק כולו ולהביא ליותר ביקוש לשבבים של Nvidia, לא פחות.
התפיסה שהצלחת DeepSeek מהווה איום על חברות הטכנולוגיה האמריקאיות היא שגויה - למעשה, עבור חלק מהחברות זו דווקא הזדמנות משמעותית. קחו למשל את Amazon: בעוד מתחרותיה מחזיקות במודלים משלהן (OpenAI עם ChatGPT, גוגל עם Gemini, אנטרופיק עם Claude, ו-Meta עם Llama), אמזון יכולה כעת לספק ללקוחותיה גישה למודלים איכותיים במחיר תחרותי. Meta נראית כמרוויחה הגדולה מהמצב - כל חלק בעסק שלה, במיוחד מערך הפרסום, יכול להרוויח מ-AI זול יותר. גם Apple נמצאת בעמדה טובה לנצל את יתרונות ה-Apple Silicon שלה לביצוע אינפרנס בקצה (Edge Inference) - אינפרנס זה התהליך שבו AI מיישם את מה שלמד בסיטואציות חדשות, בדיוק כמו תלמיד שמיישם את החומר שלמד במבחן. זה מזכיר איך שהוזלת הסמארטפונים והאינטרנט אפשרה את הופעתן של חברות כמו Uber ו-Instagram. באופן דומה, AI זול יותר עשוי לאפשר צמיחה של מוצרים ושירותים חדשים, וחברות הטכנולוגיה האמריקאיות נמצאות בעמדה מצוינת לנצל את ההזדמנות הזו.
ההשוואה בין הישגי DeepSeek ל"רגע Sputnik" של סין בתחום הבינה המלאכותית היא מוטעית מיסודה. בעוד שהשיגור הסובייטי של Sputnik הדגים יכולות טכנולוגיות חדשות שנשמרו בסוד, DeepSeek פועלת בגישה הפוכה לחלוטין - הם חולקים את המתודולוגיה שלהם בפתיחות ומדגימים שיפורי יעילות שהיו צפויים מבחינה טכנולוגית. מומחי תעשייה רבים מציעים השוואה מדויקת יותר - לרגע המכונן של גוגל ב-2004. אז, גוגל חשפה כיצד ניתן לבנות תשתית מחשוב יעילה יותר בעלות נמוכה משמעותית, והראתה שאין צורך במחשבי-על יקרים כדי להשיג ביצועים מרשימים. באופן דומה, DeepSeek מוכיחה שניתן להשיג תוצאות תחרותיות גם ללא השימוש בשבבים החזקים ביותר בשוק. זו לא מהפכה טכנולוגית דרמטית, אלא יותר התקדמות משמעותית בייעול ובנגישות של טכנולוגיות קיימות - בדיוק כפי שגוגל עשתה בזמנו.
איזה מיתוס שלא נפריך או נאושש, המספרים בסוף מדברים בעד עצמם - עם צוות מצומצם וסופר מוכשר, DeepSeek מוכיחה שלפעמים פחות זה יותר. החברה מציגה מספרים מרשימים של הורדות אפליקציה והגעה לקהל משתמשים גלובלי עצום בזמן קצר - נתונים המעידים על יעילות וצמיחה מהירה:

אחת ההשלכות המשמעותיות ביותר של התפתחויות כאלה היא הדמוקרטיזציה של כלי בינה מלאכותית מתקדמים. לראשונה, משתמשים שלא היו מוכנים או יכולים לשלם עבור שירותי AI פרימיום, יכולים כעת לגשת לשני מודלי הגיון חזקים בחינם: R1 של DeepSeek ו-o3-mini של ChatGPT. מדובר בשינוי משמעותי במיוחד עבור משימות מורכבות כמו פתרון בעיות מתמטיות, אתגרי תכנות, וניתוח בעיות הדורשות חשיבה מובנית שלב אחר שלב. מודלי ההיגיון הללו מצטיינים בדיוק במשימות אלו, ועכשיו הם זמינים לכולם ללא עלות. זוהי דוגמה מובהקת לאיך תחרות בריאה בשוק יכולה להוביל להנגשת טכנולוגיות מתקדמות לציבור הרחב, ולהסרת חסמי כניסה כלכליים שהיו קיימים עד כה.
פרטיות המידע הופכת לסוגיה מרכזית בשימוש בכלי AI, ולמשתמשים המודאגים מאופן הטיפול של DeepSeek בנתונים האישיים יש כיום שתי אפשרויות מעשיות שאת חלקן הזכרנו במיתוס מספר 7 על הפרטיות וסיכון המידע שלנו. האפשרות הראשונה היא שימוש בפלטפורמות מתווכות כמו Perplexity, Venice או Cursor, שמספקות גישה למודלים של DeepSeek תוך שמירת הנתונים מחוץ לסין. למי שמחפש רמת פרטיות מקסימלית, קיימת אפשרות להריץ את המודלים באופן מקומי על המחשב האישי באמצעות כלים כמו LM Studio או Ollama. עם זאת, חשוב לציין שבגישה זו תהיו מוגבלים למודלים פשוטים יותר בשל מגבלות החומרה של מחשב ביתי רגיל.
אנחנו לגמרי בעד התנסות ופתיחות לעולם הבינה המלאכותית על שלל כליו. יחד עם זאת, כמות הכלים שם בחוץ וההתרגשות סביב חידושים טכנולוגיים לא צריכה להוביל להחלטות פזיזות על מעבר למערכות חדשות. כשמדובר באימוץ כלי AI חדשים, חשוב לשקול את "מחיר המעבר" - הזמן והמאמץ שכבר השקעתם בלמידה והתאמה של הכלים הנוכחיים שלכם. לדוגמה, אם אתם משתמשים ב-Todoist לניהול משימות ומרוצים ממנו, העובדה ש- Tictic מציעה תכונת AI חדשה לא מצדיקה בהכרח מעבר. במיוחד כשסביר שהפלטפורמה הנוכחית שלכם תפתח יכולות דומות בעתיד. המעבר משתלם בעיקר למפתחים המחפשים לצמצם עלויות, אך למשתמשים רגילים שכבר מיומנים בכלים כמו ChatGPT ומודעים להיבטי אבטחת המידע, לרוב עדיף להישאר עם הפתרון המוכר והאמין.
הישגי הצוות של DeepSeek בהחלט ראויים ומרשימים ובעיקר מסמנים נקודת מפנה משמעותית בתעשיית הבינה המלאכותית, אך חשיבותם האמיתית טמונה בהשפעתם על המשתמש בקצה. התחרות שיצרה החברה הובילה לתגובת שרשרת חיובית - OpenAI השיקה את o3-mini בחינם, חברות נוספות משפרות את השירות שלהן, והטכנולוגיה המתקדמת הזו הופכת נגישה יותר מאי פעם. עם זאת, חשוב לגשת להתפתחויות ולכלים בצורה מושכלת ומאוזנת. בעוד שההתלהבות מובנת, קבלת החלטות צריכה להתבסס על צרכים אמיתיים ולא על הייפ זמני. זכרו - זהו רק עוד אחד ממחזורי החדשנות הרבים שעוד צפויים לנו בתחום הדינמי והמרגש הזה.