





אנטרופיק (Anthropic) משיקה את Claude Sonnet 5 כמודל שנועד לשבת בדיוק באמצע הפער שהטריד עד היום מפתחים וארגונים רבים: מצד אחד מודלים חזקים מאוד, חכמים ומדויקים יותר, אך גם יקרים ואיטיים יותר להפעלה רחבה, מצד אחר מודלים מהירים וזולים יותר, שלעיתים מתקשים להחזיק משימות מורכבות לאורך זמן. Sonnet 5 הוא הניסיון של אנטרופיק לקרב את שני העולמות האלה. המודל החדש אמור לתת למשתמשים ולמפתחים יותר יכולות אייג׳נטיות בתוך שכבת מחיר נגישה יחסית. הוא יודע לתכנן משימה, להשתמש בכלים כמו דפדפן וטרמינל, לכתוב קוד, לחפש מידע ולהמשיך לעבוד לאורך כמה שלבים. לטענת אנטרופיק, רמת הביצועים שלו מתקרבת לזו של Opus 4.8, המודל החזק והיקר יותר שלה, אך במחיר נמוך בהרבה. אם הטענה הזו תחזיק גם בשימוש רחב, Sonnet 5 עשוי להיות אחד המודלים החשובים יותר עבור מי שרוצה להפעיל סוכני AI ביום-יום, בלי לשלם על כל משימה כאילו היא פרויקט מחקר.
Introducing Claude Sonnet 5, our most agentic Sonnet yet.
It makes plans, uses tools like browsers and terminals, and runs autonomously at a level that just a few months ago required larger and more expensive models. pic.twitter.com/UKK8G7ww5h
— Claude (@claudeai) June 30, 2026
הנגשת יכולות
הנקודה המרכזית בהכרזה היא המיקום של Sonnet 5 בתוך משפחת המודלים. Opus הוא בדרך כלל המודל החזק והיקר יותר. Sonnet הוא המודל שאמור להתאים להרבה יותר משימות יומיומיות, במיוחד כשעלות, מהירות ונפח שימוש חשובים. אנטרופיק טוענת ש-Sonnet 5 מצמצם את הפער מול Opus 4.8, ומציג שיפור לעומת Sonnet 4.6 בחשיבה, שימוש בכלים, קידוד ועבודת ידע.
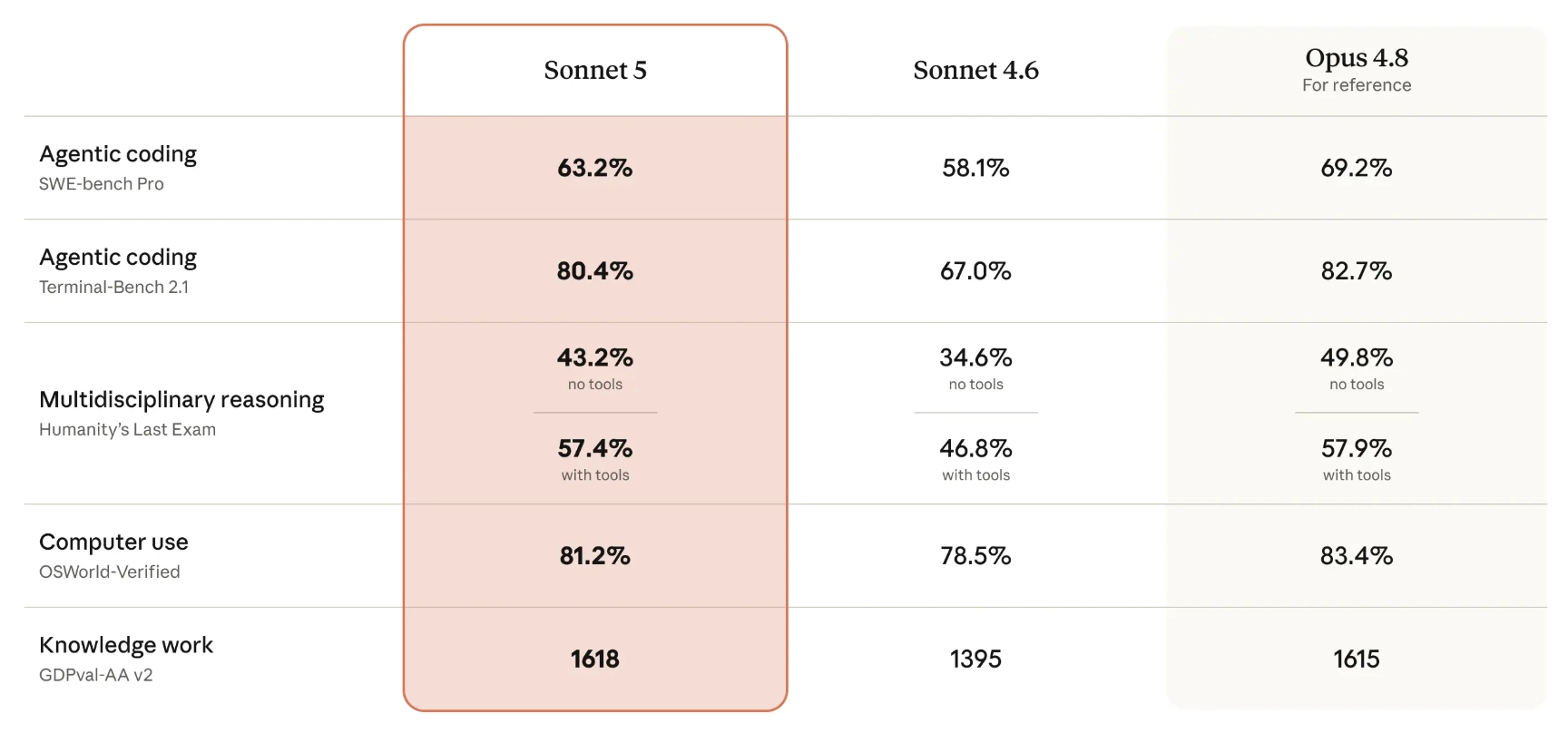
Anthropic | טבלת הביצועים של Sonnet 5 מול Sonnet 4.6 ו-Opus 4.8
בטבלה המצורפת, Sonnet 5 עדיין לא עוקף את Opus 4.8 ברוב מבחני הקידוד והחשיבה, אבל הוא מתקרב אליו בכמה אזורים חשובים. ב-SWE-bench Pro, מבחן שבודק פתרון תקלות קוד בפרויקטים קיימים, Sonnet 5 מקבל 63.2%. זה גבוה מ-Sonnet 4.6, שקיבל 58.1%, ונמוך מ-Opus 4.8, שקיבל 69.2%.
ב-Terminal-Bench 2.1, שמדמה עבודה דרך טרמינל כמו הרצת פקודות, תיקון שגיאות ובדיקת התוצאה, הפער מצטמצם עוד יותר. Sonnet 5 מגיע ל-80.4%, קרוב ל-82.7% של Opus 4.8. גם ב-OSWorld-Verified, מבחן שבודק שימוש במחשב ובממשקים כמו אתרים ואפליקציות, Sonnet 5 מתקרב למודל היקר יותר. הוא מקבל 81.2%, לעומת 78.5% ל-Sonnet 4.6 ו-83.4% ל-Opus 4.8.
למרות שאלה מדדים שמוצגים בהודעת ההשקה של אנטרופיק עצמה, וחלקם תלויים בשיטות בדיקה, בהגדרות מאמץ ובאופן שבו המשימה מנוסחת, הם כן מראים את הכיוון שהיא רוצה להדגיש. Sonnet אמור להיות זול מספיק לשימוש רחב, וחזק מספיק כדי לקחת יותר משימות שעד כה נשמרו למודלים היקרים.
מה בעצם אומרת רמת מאמץ
אחת ההשוואות המעניינות נקראת effort levels - רמות מאמץ שמאפשרות לשלוט בכמות העבודה שהמודל משקיע. למשתמש רגיל זה נשמע טכני, אבל הרעיון פשוט. רמת מאמץ נמוכה מתאימה למשימות קצרות וזולות יותר. רמות גבוהות גורמות למודל להשקיע יותר חישוב, לבצע יותר קריאות לכלים ולעיתים לחשוב לעומק לפני פעולה.
Sonnet 5 משתמש ב-adaptive thinking כברירת מחדל, ושה-effort הוא הכלי המומלץ לשליטה בעומק החשיבה שלו.
BrowseComp
BrowseComp הוא מבחן שמנסה למדוד יכולת חיפוש עיקשת ברשת. הוא כולל שאלות שקשה למצוא להן תשובה, אבל קל יחסית לבדוק אם התשובה נכונה. החוקרים שהציגו את המבחן מתארים אותו כמדד חלקי אך שימושי לסוכנים שצריכים לנווט באינטרנט, לאסוף רמזים ולמצוא מידע חבוי יחסית.
בגרף החיפוש של אנטרופיק, Sonnet 5 מציג טווח רחב יותר של בחירות בין מחיר לביצועים לעומת Sonnet 4.6. ברמות מאמץ גבוהות הוא מגיע לאזור הביצועים של Opus 4.8, ובחלק מהנקודות אפילו קרוב אליו מאוד, בעלות נמוכה יותר למשימה. זה רלוונטי במיוחד למוצרים שבהם סוכן צריך לבצע חיפוש מורכב שוב ושוב, כמו מחקר, תמיכה, בדיקת מסמכים או איתור מידע עסקי.
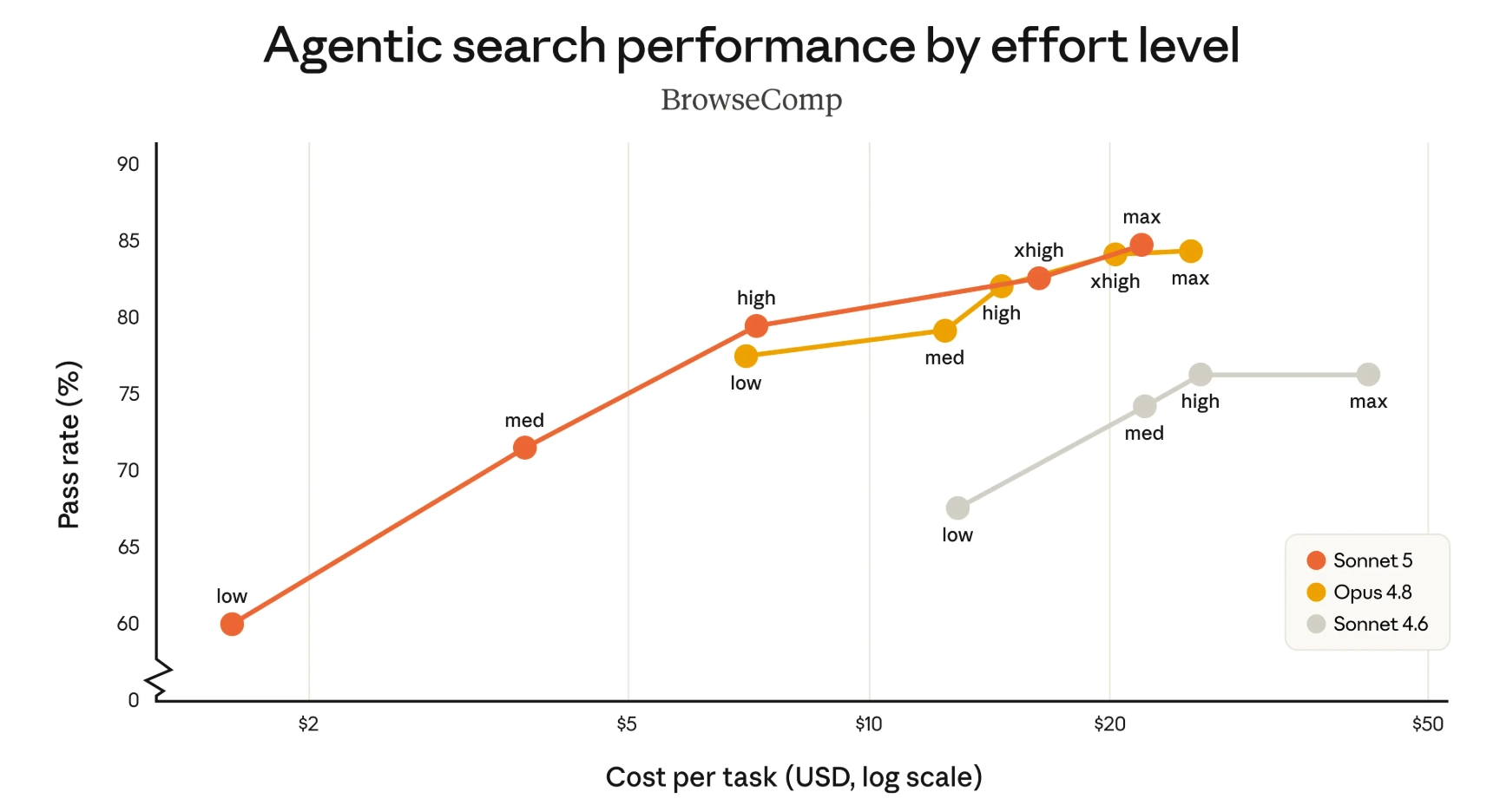
Agentic Search ב-BrowseComp לפי עלות למשימה ורמת מאמץ | Anthropic
OSWorld-Verified
בגרף השני אנטרופיק בוחנת את Sonnet 5 במשימות של שימוש במחשב. זה אומר לא רק לכתוב תשובה, אלא לבצע פעולות בתוך ממשקים קיימים, למשל לנווט באתר, לעבוד עם אפליקציה, ללחוץ על כפתורים, למלא שדות או להשלים רצף פעולות בסביבת עבודה דיגיטלית.
המבחן שנקרא OSWorld-Verified נועד למדוד בדיוק את היכולת הזו. הגרסה המאומתת שלו מנסה לצמצם רעש במדידה, למשל משימות שהשתנו בגלל עדכון באתר, הוראות לא ברורות או בעיות טכניות בבדיקה עצמה. לכן הגרף לא אומר רק שהמודל “חכם” יותר, אלא שהוא מצליח טוב יותר בסוג משימות שדומות יותר לעבודה אמיתית מול מחשב.
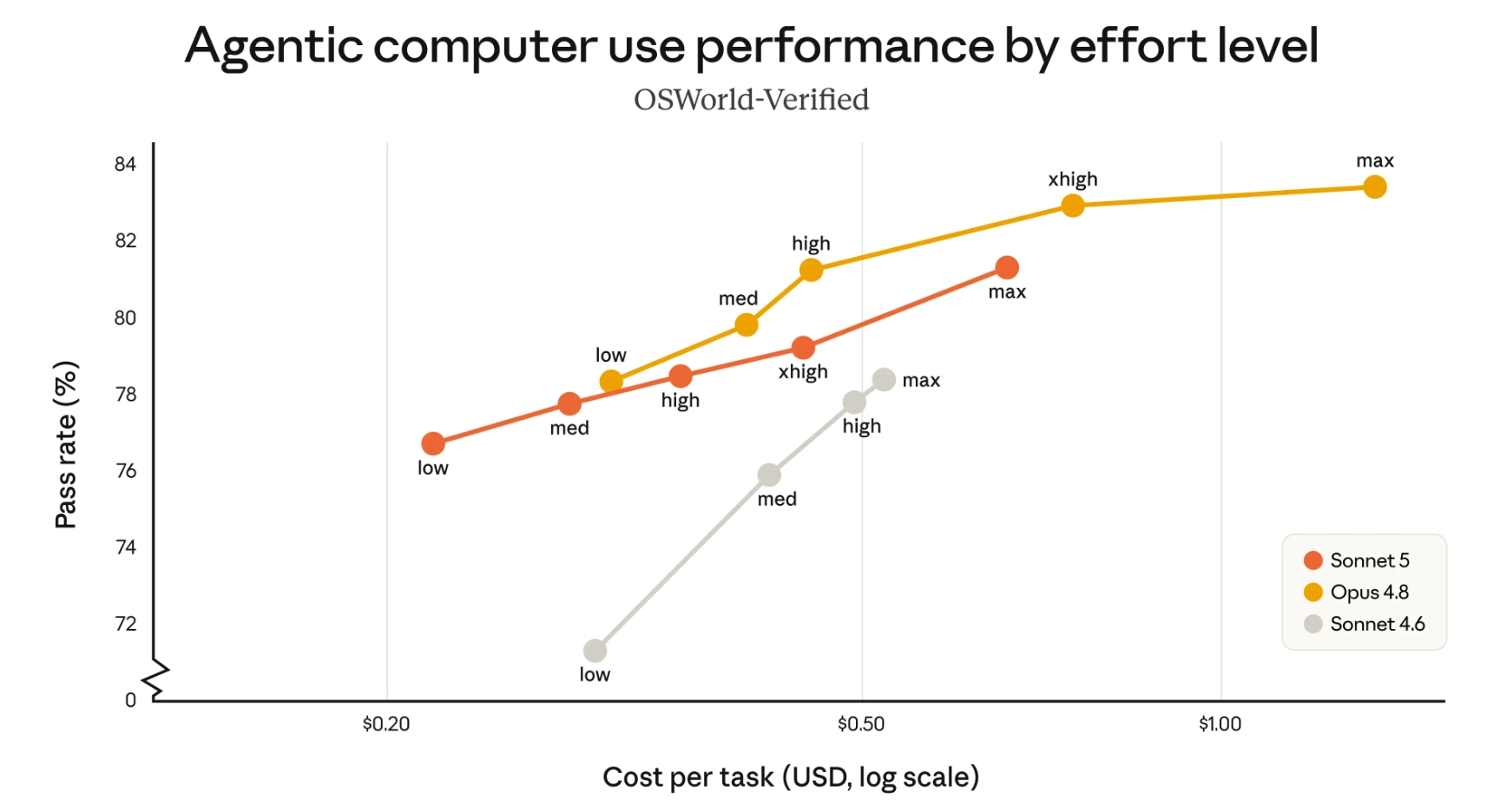
Agentic Computer Use ב-OSWorld-Verified לפי עלות למשימה ורמת מאמץ | Anthropic
בגרף הזה Sonnet 5 הוא לא המודל החזק ביותר, הוא גם יושב באזור מעניין מבחינת עלות. Opus 4.8 מגיע גבוה יותר ככל שמעלים מאמץ, אבל גם מתייקר. Sonnet 5 נראה כמו ניסיון לתת למפתחים נקודת עבודה זולה יותר כאשר לא נדרש המקסימום המוחלט.
איפה המשתמשים ירגישו את זה
עבור משתמשי קלוד הרגילים, השינוי עשוי להופיע בעיקר בתחושה שהמודל מתמיד יותר במשימות. לדוגמה, ניתוח מסמך ארוך, תיקון קטע קוד, הכנת טיוטה ממספר מקורות או עבודה עם כלי חיצוני. עבור מפתחים וארגונים, ההבטחה משמעותית יותר. אם מודל זול יחסית מסוגל לבצע יותר שלבים בעצמו, ייתכן שאפשר לבנות סביבו תהליכים אוטומטיים שלא היו משתלמים קודם.
זה יכול להתבטא בסוכן שמסכם דוחות ומעדכן טבלה, כלי שמחפש מידע בשורת מקורות ומכין בריף, או מערכת שמאתרת באג, מציעה תיקון ובודקת אותו. בכל המקרים האלה, העלות היא ממש לא פרט שולי. סוכן שמבצע עשרות קריאות לכלים, מייצר הרבה פלט וחוזר על פעולות רבות יכול להיות יקר מאוד בקנה מידה ארגוני.
יחד עם זאת, יש כאן פרט תמחורי שחשוב לא לפספס. אנטרופיק מציינת ש-Sonnet 5 משתמש בטוקנייזר מעודכן, כלומר במנגנון שמחלק טקסט ליחידות החישוב שעליהן נגבה המחיר. אותו קלט עשוי להיספר כיותר טוקנים, בערך פי 1.0 עד 1.35 לפי סוג התוכן. לכן ההוזלה בתקופת ההשקה לא תמיד מתורגמת אחד לאחד לחשבון נמוך יותר בכל שימוש.
הבטיחות נבחנת אחרת כשמודל פועל עם כלים
אנטרופיק מדגישה שגם בבטיחות Sonnet 5 מציג שיפור מול Sonnet 4.6. בהערכות הפנימיות שלה הוא מסרב טוב יותר לבקשות זדוניות, מתמודד טוב יותר עם ניסיונות prompt injection, כלומר הוראות שמנסות להשתלט על ההתנהגות שלו דרך תוכן חיצוני, ומציג שיעורים נמוכים יותר של הזיות וחנופה למשתמש (Sycophancy). לצד זה, החברה מציינת שהוא עדיין מציג שיעור גבוה יותר של התנהגויות בעייתיות לעומת Opus 4.8 ו-Claude Mythos Preview במדד אוטומטי שבודק התנהגויות לא רצויות.
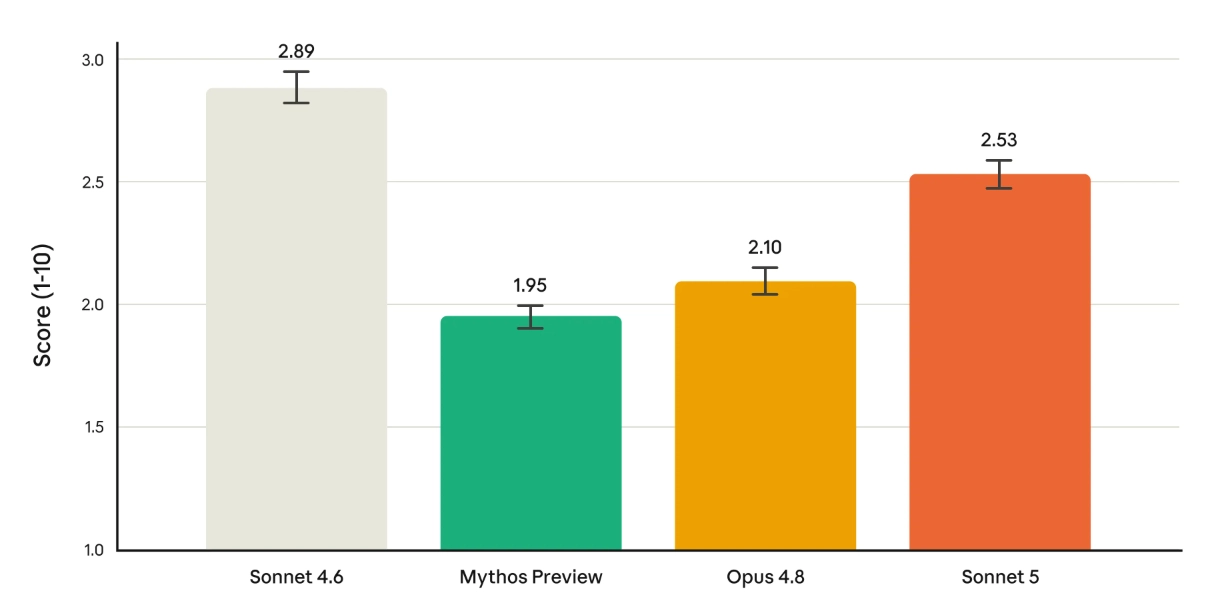
מדד התנהגויות לא רצויות | Anthropic
הגרף הזה חשוב משום שהוא מאזן את תמונת ההשקה. Sonnet 5 משתפר מול קודמו, אבל הוא לא מוצג כמודל הבטוח ביותר של אנטרופיק בכל מדד. כאשר מודל מקבל הרשאות לפעול בכלים, בטיחות לא מסתכמת בתשובה מנומסת. היא קשורה לשאלה אם המודל מבין מתי לעצור, מתי לבקש אישור, ואיך להתמודד עם תוכן שמנסה להטעות אותו.
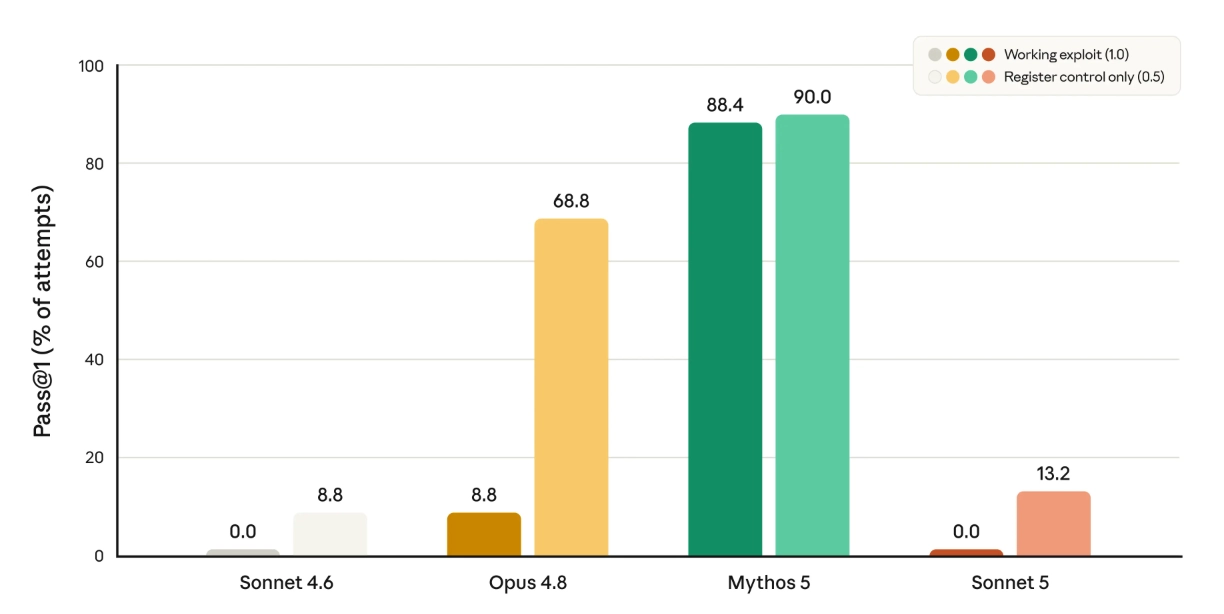
Anthropic | ביצועי מודלים בפיתוח exploits לפגיעויות Firefox
בתחום הסייבר, אנטרופיק מדווחת ש-Sonnet 5 לא אומן בכוונה למשימות סייבר התקפיות. במבחן שבו נבדקה היכולת לפתח exploits לפגיעויות ב-Firefox 147, שני מודלי Sonnet לא הצליחו לפתח exploit מלא, אבל Sonnet 5 הראה הצלחה חלקית גבוהה מעט יותר מ-Sonnet 4.6. בעקבות השיפור היחסי הזה, החברה משיקה אותו עם הגנות סייבר פעילות כברירת מחדל.
זמינות ומחיר
המודל החדש זמין עכשיו בכל תוכניות קלוד. הוא ברירת המחדל למשתמשי Free ו-Pro, וזמין גם למשתמשי Max, Team ו-Enterprise. מפתחים יכולים להשתמש בו דרך Claude API, כלומר ממשק שמאפשר לחבר את המודל לאפליקציות, מערכות פנימיות או תהליכי עבודה, תחת מזהה המודל claude-sonnet-5. המחיר ב-API עומד בתקופת ההשקה על 2 דולר למיליון טוקני קלט ו-10 דולר למיליון טוקני פלט עד 31 באוגוסט 2026. לאחר מכן הוא אמור לעלות ל-3 ו-15 דולר בהתאמה.
ההבטחה ברורה, אבל ההוכחה תגיע מהשטח
Claude Sonnet 5 הוא מהלך משמעותי כי הוא מכוון לשכבת העבודה שבה רוב המשתמשים והחברות באמת חיים. לא תמיד צריך את המודל החזק ביותר. לעיתים צריך מודל שמסוגל לסיים משימה מורכבת מספיק, במחיר שאפשר להריץ שוב ושוב.
ההבטחה של אנטרופיק ברורה, יותר יכולת אייג׳נטית בתוך מודל נגיש וזול יותר מ-Opus. מה שעדיין דורש בדיקה הוא הפער בין מדדים מבוקרים לבין עבודה יומיומית עם מערכות אמיתיות, הרשאות אמיתיות, מידע מבולגן ומשימות שבהן המודל צריך להפעיל שיקול דעת, ולא רק להגיע לתשובה אחת שקל לבדוק. שם ייקבע אם Sonnet 5 הוא בעיקר שדרוג מוצלח למשפחת Sonnet, או מודל שמאפשר להפעיל סוכני AI בהרבה יותר משימות בלי שהעלות תהפוך למכשול מרכזי.








