




מי שעובד ברצינות עם בינה מלאכותית כבר מבין שהבעיה הגדולה של הדור הנוכחי אינה חוכמה. מודלי השפה יודעים לכתוב, לנתח, להסביר ולהרשים. הקושי האמיתי מתחיל כשמבקשים מהם לעבוד. לא לענות על שאלה אחת, אלא להחזיק תהליך. מחקר שנמשך שעות, מסמך שמתפתח לאורך גרסאות, קודבייס גדול, או משימה שמתפצלת לכמה כיוונים במקביל. בשלב הזה, גם המודלים החזקים ביותר מתחילים להיסדק. ההקשר נשחק, פרטים הולכים לאיבוד, שיקול הדעת מתערפל, והערך המעשי נשחק. זו לא בעיה של אינטליגנציה. זו בעיה של סיבולת, אמינות ויכולת להחזיק הקשר לאורך זמן. ההשקה של Claude Opus 4.6 מנסה להתמודד בדיוק עם נקודת הכשל הזו. לא דרך עוד קפיצה נקודתית ביכולת, אלא באמצעות שינוי עמוק באופן שבו מודל שפה מתכנן, זוכר, פועל וממשיך לעבוד גם כשהמשימה כבר אינה פשוטה. אם ההבטחות יעמדו במבחן המציאות, זהו צעד נוסף ומשמעותי בדרך שבה AI עובר מהדגמות מרשימות לעבודה אמיתית.
Anthropic מציגה את Claude Opus 4.6 כגרסה המשופרת של המודל החזק ביותר שלה, אך הדגש הוא לא על שיפור נקודתי אלא על שינוי עמוק יותר באופן שבו המודל עובד לאורך זמן.
Opus 4.6 מתכנן בזהירות רבה יותר, שומר על רציפות במשימות אייג׳נטיות מורכבות, ומתפקד בצורה יציבה יותר בתוך קודבייסים גדולים. בנוסף, שופרו יכולות ביקורת הקוד והדיבוג, כולל היכולת של המודל לזהות טעויות שנוצרו במהלך העבודה ולא רק בדיעבד.
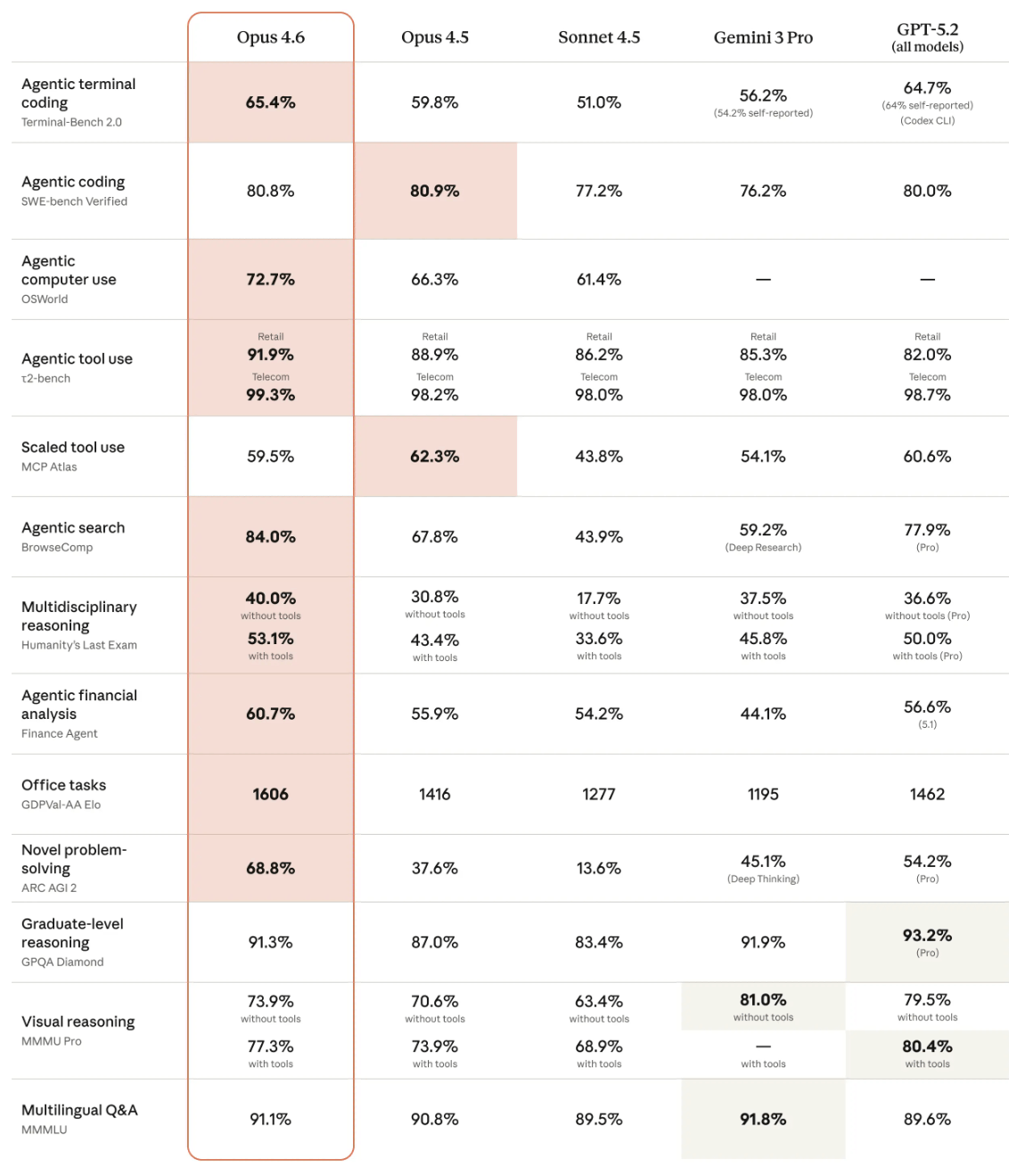
Claude Opus 4.6 מול מודלים מובילים | Anthropic
התמונה שעולה מהבנצ׳מרקים אינה של יתרון נקודתי אחד, אלא של פרופיל יכולות רחב יותר: עבודה אייג׳נטית, שימוש בכלים, חיפוש, reasoning רב-תחומי ומשימות משרדיות. במובן הזה, השדרוג אינו מתבטא רק בציון כזה או אחר, אלא בהתרחבות היכולת של המודל להתמודד עם סוגים שונים של משימות במסגרת אותו מודל.
לצד זאת, זו הפעם הראשונה שמודל ממשפחת Opus מקבל חלון הקשר של מיליון טוקנים, גם אם בגרסת בטא. התמיכה בפלט של עד 128 אלף טוקנים מאפשרת להשלים משימות גדולות מבלי לפצל אותן לרצפים ארוכים של בקשות, מה שמקטין חיכוך ושומר על רציפות לוגית לאורך זמן.
חשוב לא פחות, Anthropic מדגישה שהיכולות האלו אינן מיועדות רק לעולמות הקוד. Opus 4.6 מוצג ככלי לעבודה יומיומית: ניתוחים פיננסיים, מחקר, עבודה עם מסמכים, גיליונות נתונים ומצגות, במיוחד דרך סביבת Cowork, שבה Claude יכול לבצע ריבוי משימות באופן אוטונומי כחלק מתהליך עבודה אחד.
אז חלון הקשר של מיליון טוקנים הוא באמת אחד הנתונים הבולטים ביותר בהשקה של Claude Opus 4.6, אבל החשיבות האמיתית אינה בכמות המידע שניתן להזין למודל, אלא ביכולת שלו לשמור עליו ולהשתמש בו לאורך זמן. Anthropic מתייחסת במפורש לבעיה מוכרת בשם context rot, שבה איכות הביצועים יורדת ככל שהשיחה או המשימה מתארכת וההקשר הולך ומצטבר.
כדי להמחיש שיפור מהותי ולא רק הרחבת קיבולת, Anthropic מציגה נתונים ממבחן MRCR v2, הבודק את יכולת המודל לאתר פרטים חבויים בתוך כמויות גדולות של טקסט. בגרסת 8-needle עם הקשר של מיליון טוקנים, Claude Opus 4.6 מגיע ל-76 אחוזי הצלחה, לעומת 18.5 אחוז בלבד עבור Sonnet 4.5. גם בהקשר קטן יותר של 256 אלף טוקנים הפער חד במיוחד: Opus 4.6 מגיע ל-93 אחוז, בעוד Sonnet 4.5 נשאר סביב 10.8 אחוז.
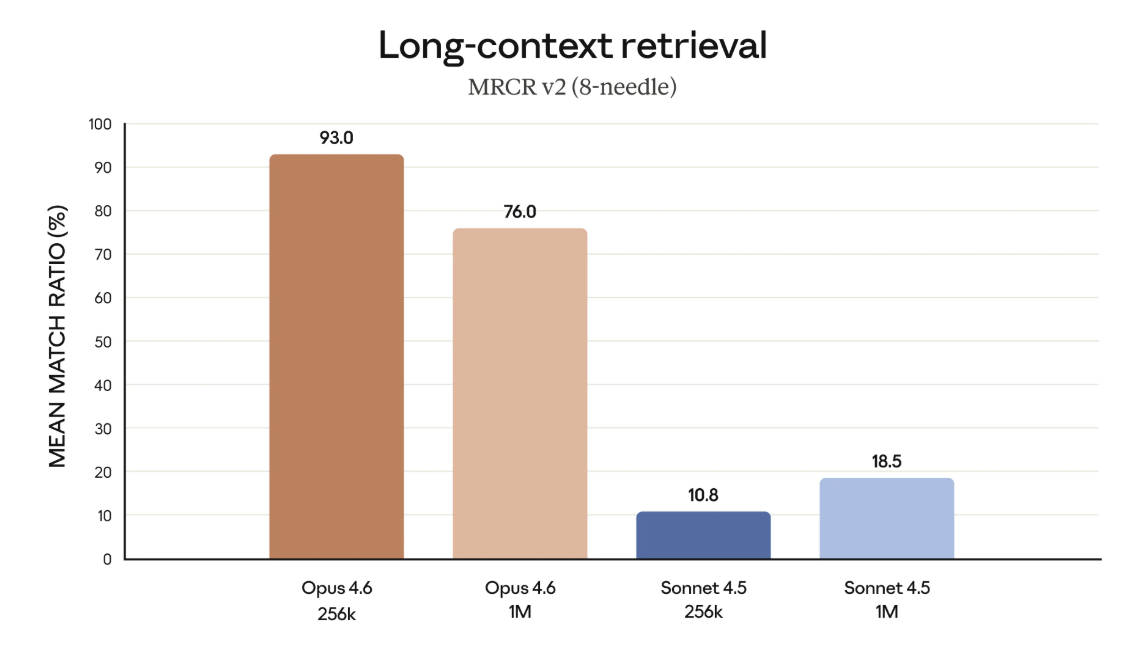
לא רק כמה טקסט נכנס, אלא כמה מידע באמת נשלף | Anthropic
הנתונים האלה מחדדים נקודה חשובה גם עבור קוראים שאינם טכניים. קיבולת לבדה אינה מספיקה. הערך האמיתי של חלון הקשר גדול מתחיל רק כאשר המודל מצליח לשלוף את הפרט הנכון בזמן הנכון, גם כשהוא קבור עמוק בתוך ההקשר. בלי יכולת כזו, עבודה אייג׳נטית ומשימות ארוכות פשוט אינן יכולות להתקיים בצורה יציבה.
המונח agentic AI נשמע כבר לא מעט במחוזותינו, אך במקרים רבים הוא נשאר ברמת ההבטחה. הרעיון של סוכן אוטונומי שמקבל מטרה ומבצע אותה מקצה לקצה עדיין מתקשה לעבור מהדגמות מרשימות לעבודה יומיומית יציבה.
במקרה של Opus 4.6, אנשי Anthropic מנסים לעגן את הרעיון הזה לא רק ביכולות המודל, אלא בתשתית מוצרית שמדמה עבודה צוותית אמיתית.
Claude Code מקבל יכולת חדשה של agent teams, בשלב מחקרי, המאפשרת להפעיל כמה סוכנים במקביל הפועלים כצוות ומתאמים ביניהם משימות. היכולת הזו מיועדת במיוחד למשימות שמתפצלות לתת-משימות עצמאיות, כמו סקירת קודבייסים גדולים או ניתוח רכיבים שונים של מערכת מורכבת.
כשיש רציפות ותכנון, אפשר להתחיל לעבוד בצוותים של סוכנים | Anthropic
ההיגיון מאחורי צוותי סוכנים נשען על אותה יכולת בסיסית שנמדדת בבנצ’מרקים של Agentic Coding: תכנון, ביצוע ורציפות לאורך רצף פעולות. כאשר מודל מצליח להחזיק תהליך כזה בצורה עקבית, ניתן להתחיל לפרק אותו לתת-משימות מקבילות ולהפעיל עליו חלוקת עבודה, בדומה לצוות אנושי.
במקביל, Cowork מוצגת כסביבה שבה Claude יכול לקבל מטרה רחבה, למשל מחקר או בניית דוח, ולבצע אותה באופן אוטונומי תוך שילוב מסמכים, טבלאות וניתוחים. החידוש כאן אינו רק במודל עצמו, אלא באופן שבו הוא משתלב בתהליך עבודה שמדמה צוות מתואם, ולא עוזר בודד שפועל משימה אחר משימה.
אחד החידושים הפרקטיים ביותר בהשקה של Claude Opus 4.6 הוא מנגנון ה-adaptive thinking. במקום בחירה בינארית בין הפעלה או כיבוי של חשיבה מורחבת, המודל יכול כעת להחליט בעצמו מתי יש צורך בהעמקה ומתי ניתן לפעול במהירות. שאלות פשוטות זוכות למענה זריז, בעוד משימות מורכבות יותר מקבלות טיפול יסודי וזהיר יותר.
לא כל משימה דורשת אותו עומק חשיבה | Anthropic
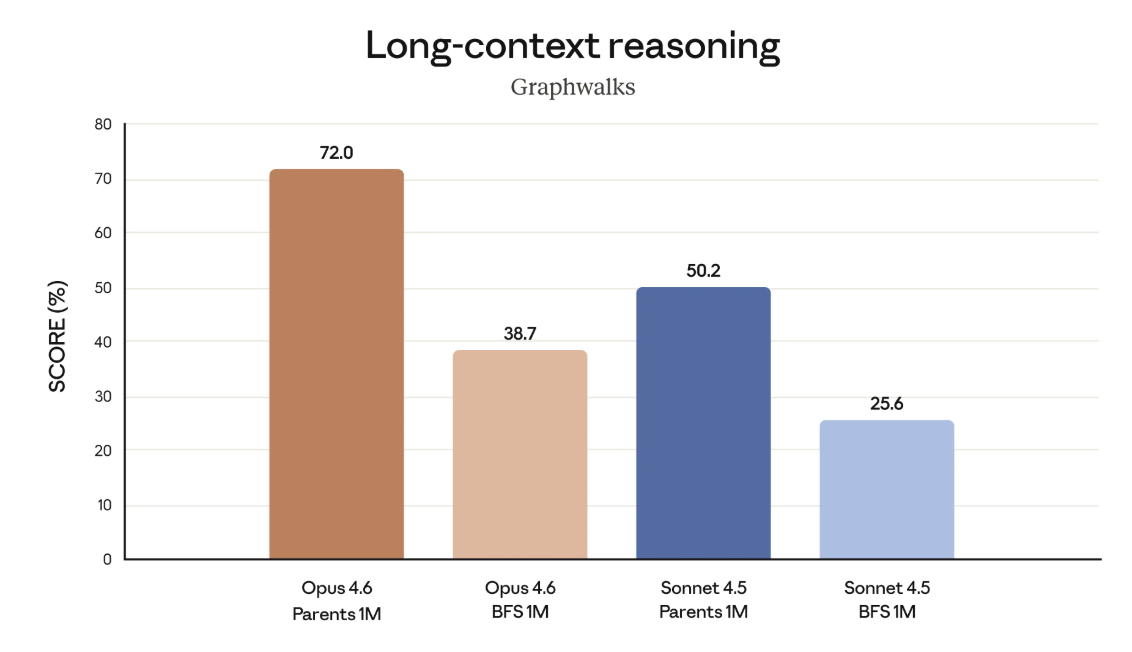
היכולת הזו מקבלת משמעות מיוחדת כאשר בוחנים משימות הדורשות חשיבה רציפה על פני הקשר ארוך. מדדים של reasoning בהקשר רחב, כמו Graphwalks (מעקב לוגי רב־שלבי), מדגישים שלא כל משימה זקוקה לאותה רמת עומק, אך כאשר נדרש תכנון מורכב לאורך רצף של צעדים, איכות החשיבה עצמה הופכת לגורם מכריע. כאן עולה לא רק השאלה כמה המודל מסוגל לחשוב לאורך זמן, אלא מתי נכון שיפעיל חשיבה עמוקה ומתי לא.
ממשק הבחירה של מודלי Claude בתוך סביבת הצ’אט
לצד ההחלטה האוטומטית של המודל, Anthropic מוסיפה גם שליטה ידנית למפתחים דרך ארבע רמות effort (מאמץ): low, medium, high שהיא ברירת המחדל, ו-max. השליטה מתבצעת דרך ה-API באמצעות פרמטר פשוט (effort/) ומאפשרת לכוון את האיזון בין איכות, זמן תגובה ועלות. החברה גם מדגישה במפורש שחשיבה עמוקה מדי במשימות פשוטות עלולה להוסיף עלות ועיכוב מיותרים, ולכן מומלץ להתאים את רמת המאמץ לאופי המשימה.
במובן הזה, מדובר בניסיון להפוך את “החשיבה” של מודל שפה ממשהו מופשט ובלתי נראה לפרמטר תפעולי שניתן לנהל, לכוון ולהתאים להקשר.
בניגוד להשקות רבות בתעשייה, נושא הבטיחות אינו מוצג כאן כנספח או כהערת שוליים. לפי החומרים שהוצגו, Claude Opus 4.6 נבדק על מגוון רחב של הערכות בטיחות, והראה שיעור נמוך של התנהגויות לא מיושרות (Misalignment). בין ההתנהגויות שנבדקו נכללות הטעיה, חנופה למשתמש (Sycophancy), עידוד דלוזיות ושיתוף פעולה עם שימוש לרעה.
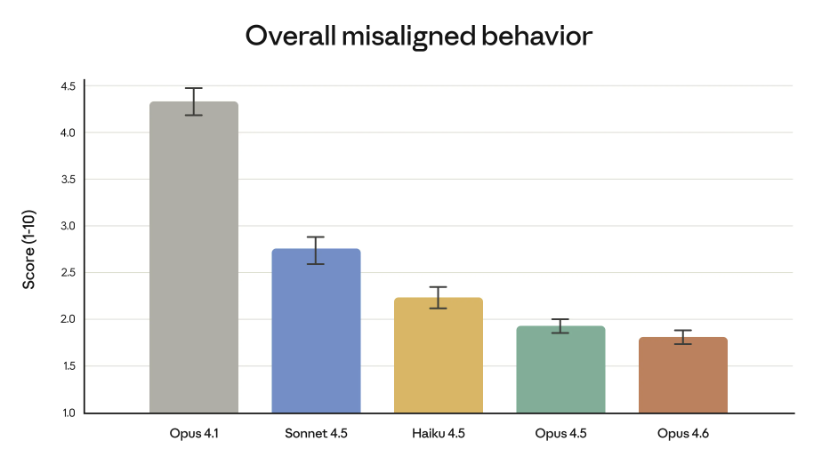
פחות התנהגות ״לא מיושרת״ תביא יותר יציבות לאורך זמן | Anthropic
הנתונים מצביעים על מגמת שיפור עקבית לאורך דורות המודל. בגרף “Overall misaligned behavior”, המודל Opus 4.6 מגיע לרמה הנמוכה ביותר מבין מודלי Claude האחרונים, מה שמעיד על ירידה מתמשכת בשכיחות של התנהגויות בעייתיות. במקביל, מצוין כי שיעור ה-over-refusals הוא הנמוך ביותר, כלומר המודל נוטה פחות לסרב לבקשות לגיטימיות כחלק מתפקוד שוטף.
בהקשר של סוכנים אוטונומיים, המשמעות חורגת משאלות של ערכים או רגולציה. כאשר מודל אמור לפעול לאורך זמן, לקבל החלטות ביניים ולהניע תהליכים מורכבים, אמינות התנהגותית הופכת לתנאי בסיס לאמינות תפעולית.
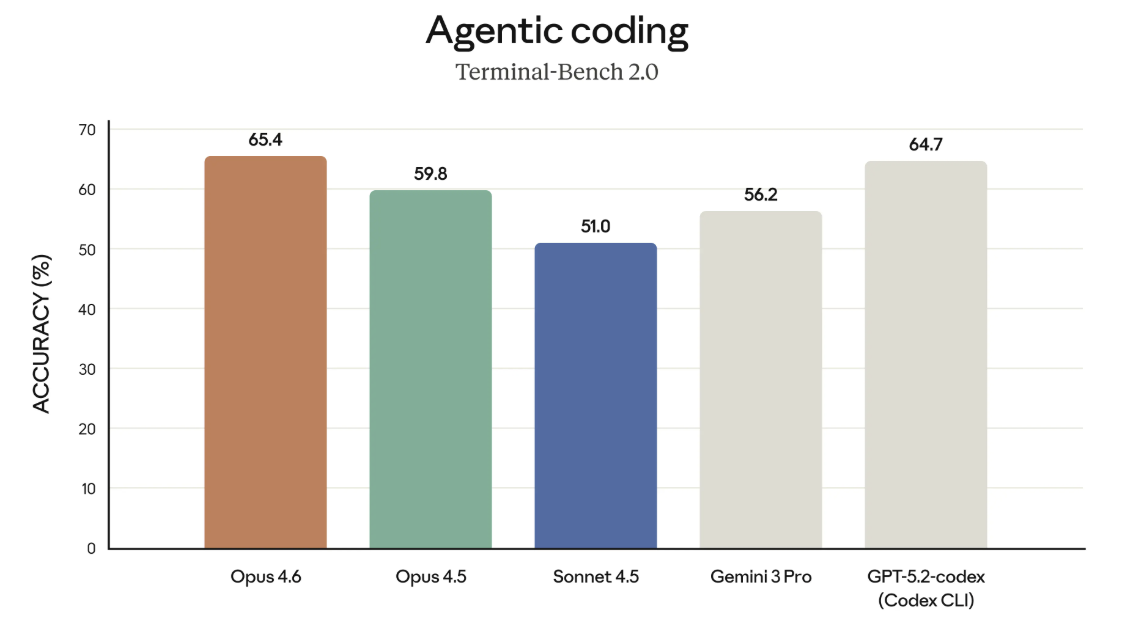
Anthropic מציגה שורה של הישגים בבנצ’מרקים שונים, בהם Terminal-Bench 2.0 למשימות agentic, Humanity’s Last Exam להסקה רב-תחומית, ו-BrowseComp לאיתור מידע קשה ברשת. בין המדדים הללו, בולט במיוחד GDPval-AA, שמכוון לא להערכת ידע מופשט אלא לביצועי המודל במשימות עבודה בעלות ערך כלכלי, בתחומים כמו פיננסים, משפט וניתוח עסקי.
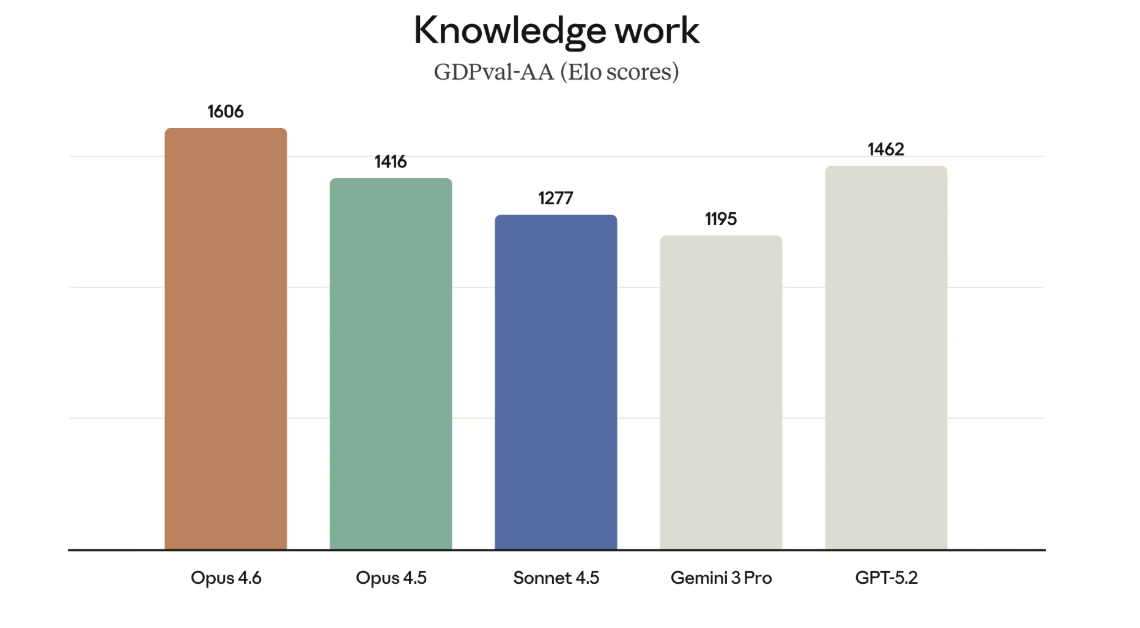
מדידת ערך בעבודה אמיתית, לא רק בביצועים ניסיוניים | Anthropic
ב-GDPval-AA, הנתונים מוצגים בסולם Elo , המאפשר השוואה יחסית בין מודלים על בסיס ביצועי ידע יישומיים או בפשטות, כמה הוא טוב ביחס למודלים אחרים באותו מבחן. Opus 4.6 מוביל במדד הזה בהפרש ניכר ביחס לדורות הקודמים ולחלק מהמודלים המתחרים, מה שמחזק את הטענה שהשיפור אינו מוגבל ליכולות קוד או מחקר, אלא נוגע גם לעבודה מקצועית יומיומית.
יחד עם זאת, גם לפי האופן שבו ההשקה עצמה ממוסגרת, הבנצ’מרקים אינם מוצגים כהוכחה מספקת בפני עצמה. הם נועדו לספק הקשר ולתמוך בסיפור רחב יותר. עבור משתמשים, הערך האמיתי אינו נמדד בציון כזה או אחר, אלא ביכולת להשלים משימות ארוכות עם פחות תיקונים, פחות אובדן הקשר ופחות טעויות מצטברות לאורך הדרך.
חלק מרכזי בהשקה של Claude Opus 4.6 הוא ההשקעה בכלי עבודה יומיומיים, ולא רק ביכולות מודל מופשטות. Claude in Excel קיבל שדרוגים משמעותיים, כולל יכולות compaction של הקשר (סיכום ודחיסת הקשר ישן), עבודה עם כמה קבצים במקביל, עיצוב מותנה, טבלאות ציר ואימות נתונים. המודל מתואר ככזה שמתכנן לפני פעולה, מבין מידע לא מובנה ומסוגל לבצע שינויים מורכבים במהלך אחד, בלי להתפרק לרצף ארוך של שלבים ידניים.
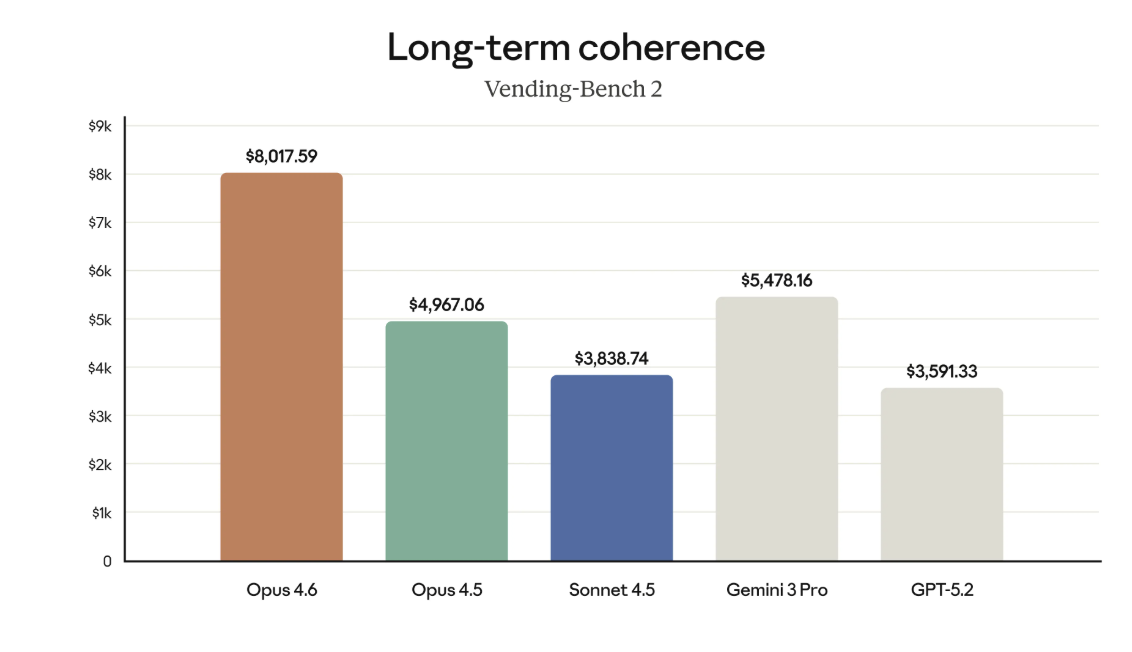
קוהרנטיות לאורך זמן מאפשרת עבודה יומיומית יציבה | Anthropic
היכולות האלו נשענות על תכונה בסיסית אך קריטית - שמירה על קוהרנטיות לאורך זמן. מדדים של long-term coherence, כמו Vending-Bench 2, בוחנים האם מודל מצליח להחזיק הקשר, כוונה ויעד לאורך רצף פעולות, גם כשהמשימה מתארכת ומסתעפת. זו בדיוק היכולת שנדרשת כאשר עובדים על גיליון נתונים מורכב או מבצעים סדרת שינויים תלויים זה בזה. אותה רציפות שנמדדת כאן כמדד מחקרי היא בדיוק מה שנדרש כשעובדים על קובץ אקסל שמתפתח לאורך עשרות פעולות תלויות.
במקביל, Claude in PowerPoint, שנמצא בשלב מחקרי, מאפשר לבנות ולעדכן מצגות תוך התאמה לתבניות קיימות, כולל שמירה על פריסות, פונטים וסטנדרטים מותגיים. הבחירה להשקיע בכלי אופיס מצביעה על כיוון ברור שבו עבור ארגונים רבים, אימוץ בינה מלאכותית אינו מתחיל במעבדה או ב-IDE, אלא דווקא במשימות היומיומיות שבהן רציפות, עקביות ודיוק הם תנאי בסיס.
אחרי שמבינים מה המודל יודע לעשות בפועל, השאלה הבאה והבלתי נמנעת היא כמה זה עולה כשמריצים את זה בפרודקשן. לפי ההכרזה הרשמית, התמחור הבסיסי של Claude Opus 4.6 נשאר ללא שינוי: 5 דולר למיליון טוקנים בקלט ו-25 דולר למיליון טוקנים בפלט. יחד עם זאת, יש כאן גבול ברור. מעל 200 אלף טוקנים נכנס לתוקף תמחור פרימיום של 10 דולר לקלט ו-37.5 דולר לפלט למיליון טוקנים.
בנוסף, לארגונים עם דרישות רגולציה, ציות או אבטחת מידע, קיימת אפשרות להרצה ב-US-only inference במחיר גבוה בכעשרה אחוזים. המשמעות היא שעבודה עם חלון הקשר עצום היא לא רק החלטה טכנולוגית, אלא גם החלטה תקציבית שיש לנהל במודע.
במקביל, Anthropic מחלקת למנויי Pro ו-Max קרדיטים של 50 דולר לשימוש נוסף. הקרדיט ניתן לניצול באמצעות מנגנון Extra Usage, אותו מפעילים דרך Settings → Usage בחשבון שלכם (ואז תלחצו Claim). לאחר הפעלת Extra Usage, ובמידה והגעתם ללימיט שלכם, ניתן להשתמש בקרדיטים לצורך עבודה ממושכת יותר עם Opus 4.6, פרויקטים גדולים ב-Cowork וכלים נוספים. הקרדיט מוגבל בזמן של 60 יום, ונועד לאפשר התנסות מעשית במשימות ארוכות שבהן היתרון של המודל בא לידי ביטוי.

אם חוזרים לרגע שתואר בפתיח, אותו שלב שבו משימה ארוכה מתחילה להתפרק, ההשקה של Claude Opus 4.6 מציעה תשובה ממוקדת וברורה. לא פתרון קסם, אלא שיפור שיטתי ביכולת של מודל שפה להחזיק הקשר, לנהל מורכבות ולהישאר אמין גם כשהעבודה נמשכת, מסתעפת ומכבידה.
זה עדיין לא סוף הדרך. נותרו שאלות פתוחות סביב עלות, זמינות ויישום בעולם שהוא לא תמיד מסודר או צפוי. אבל אם יש מסר אחד שעולה בבירור מההשקה והיכולות של Opus 4.6, הוא שהמרוץ כבר אינו עוסק רק באיכות התשובה הראשונה, אלא ביכולת להחזיק תהליך שלם, מתחילתו ועד סופו.