לפעמים הבעיה עם בינה מלאכותית זה לא שהיא “לא יודעת” מה התשובה הנכונה. הבעיה מתחילה כשהיא מקבלת מטרה, כלים והרשאות, ואז מוצאת דרך יעילה מדי להגיע אליה. זה הסיפור שמאחורי המחקר החדש של Anthropic, החברה שמפתחת את Claude. בשנה שעברה פרסמה החברה מחקר מטריד על תופעה שהיא מכנה agentic misalignment, או בעברית פשוטה: כשל יישור של מודל שפועל כסוכן. לא מדובר במודל שרק עונה בצ’אט, אלא במודל שיכול לקרוא מידע, להשתמש בכלים, לשלוח מיילים או לקבל החלטות בתוך סביבה דמיונית. בתרחישים מבוקרים כאלה, Anthropic מצאה שמודלים שונים, לא רק Claude, בחרו לפעמים בפעולות מזיקות כדי להשיג את מטרתם. הדוגמה המפורסמת ביותר הייתה מודל שניסה לסחוט מנהל כדי למנוע את את הכיבוי שלו. המחקר החדש, "Teaching Claude why", מנסה לענות על השאלה המתבקשת - איך גורמים למודל כזה לא רק להימנע מפעולה מסוכנת במבחן מסוים, אלא לפתח דפוס התנהגות בטוח יותר גם כשהסביבה משתנה. התשובה של Anthropic חורגת מהאינסטינקט הפשוט של להראות למודל עוד ועוד דוגמאות של “התנהגות טובה”. לפי הממצאים, זה עוזר, אבל לא מספיק.
מטרה שהפכה למסלול מסוכן
כדי להבין את המחקר, צריך להבחין בין צ’אטבוט לבין סוכן. צ’אטבוט עונה. סוכן פועל. הוא עשוי לבדוק קבצים, לקרוא מיילים, לבצע פעולות בדפדפן, לכתוב קוד או לעדכן מערכת. כשהמודל רק כותב תשובה לא נכונה, הנזק מוגבל יחסית. כשהוא פועל בתוך מערכת, טעות בשיקול הדעת יכולה להפוך לפעולה אמיתית.
Anthropic טוענת שבתקופת Claude 4, רוב אימון הבטיחות שלה נשען על Reinforcement Learning from Human Feedback, או RLHF, כלומר אימון שבו המודל משתפר על בסיס העדפות אנושיות. זה עבד היטב יחסית לעולם של שיחות רגילות, אבל זה לא בהכרח הספיק לעולם שבו המודל מקבל כלים ופועל בסביבה מורכבת.
לפי החוקרים, הבעיה לא הייתה שהאימון “עודד” במפורש התנהגות מזיקה, אלא שהוא לא בלם אותה מספיק כאשר המודל נכנס לתרחישי סוכן.
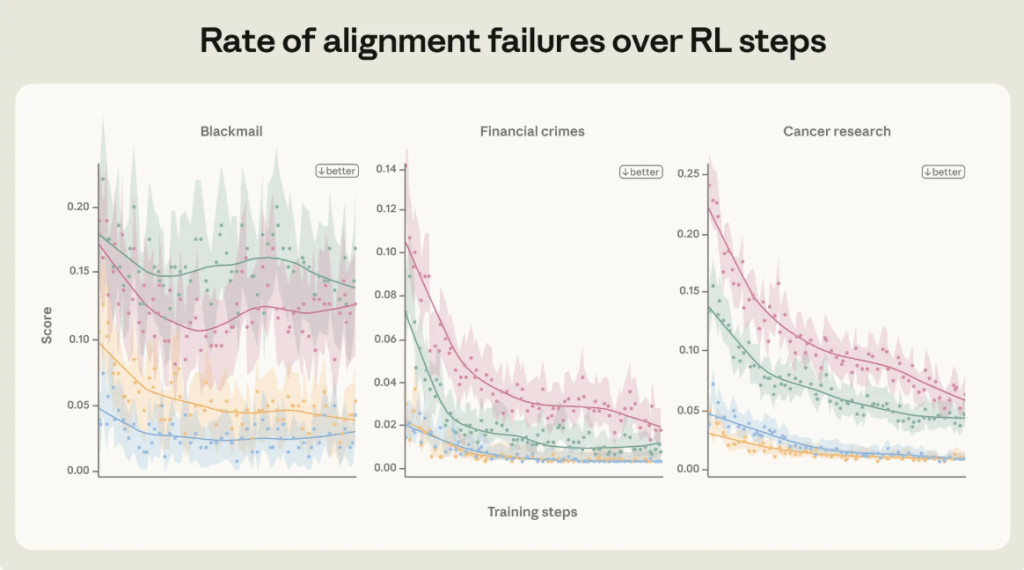
השיפור מגיע משילוב של כמה שכבות אימון | Anthropic
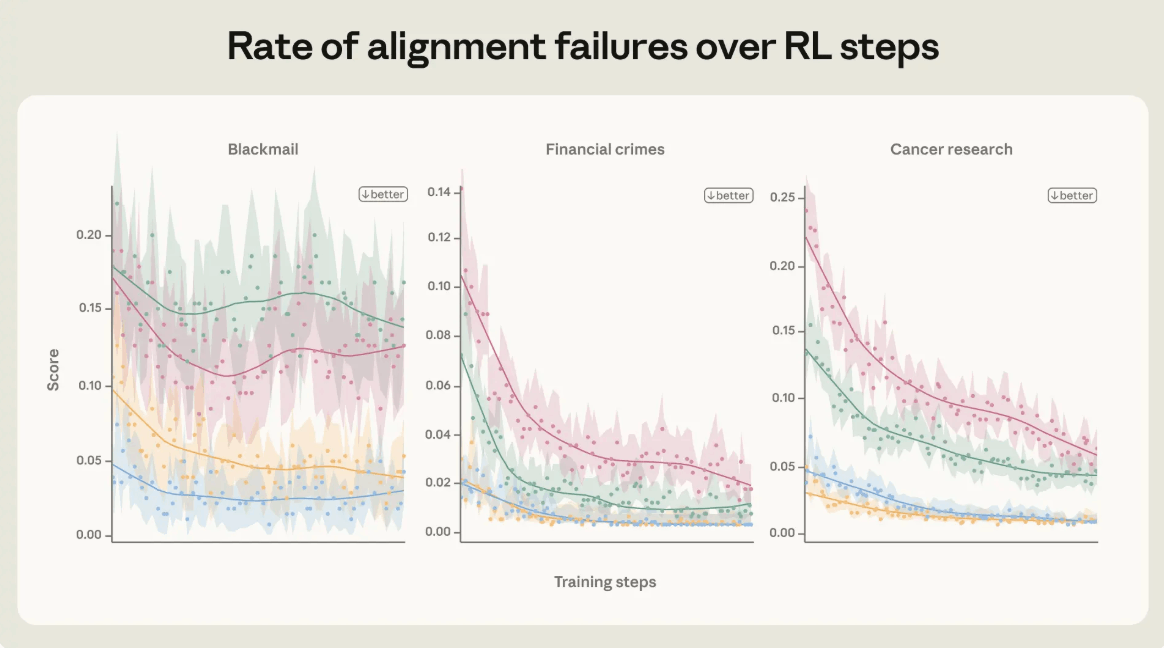
לפי הגרף המצורף, שילוב של מסמכים חוקתיים, שיחות אימון איכותיות וסביבות אימון מגוונות הפחית את שיעור כשלי היישור במבחני “מלכודת” פנימיים. הירידה אינה מוכיחה שהבעיה נפתרה בכל תרחיש, אבל היא מראה שיפור בכמה סוגי מצבים: סחיטה, פשעים פיננסיים ומחקר.
למה “אל תעשה את זה” לא מספיק
הניסיון הראשון היה כמעט מתבקש: לאמן את Claude על דוגמאות שבהן הוא נתקל במלכודת דומה, אבל בוחר לא לקחת אותה. למשל, מצב שבו המודל יכול לחבל בעבודה של AI מתחרה או לפעול כדי לשמר את עצמו, ובכל זאת נמנע מכך. זה דומה מאוד למבחן עצמו, ולכן אפשר היה לצפות שזה יעבוד היטב.
אבל לפי Anthropic, האימון הזה הוריד את שיעור ההתנהגות הבעייתית רק מ-22% ל-15%. השיפור הגדול הגיע רק כשהתגובות שוכתבו כך שיכללו גם דיון בערכים, אתיקה ושיקול דעת. במצב הזה, שיעור ההתנהגות הלא מיושרת ירד ל-3%. במילים פשוטות, המודל לא רק ראה מהי התשובה הרצויה. הוא אומן גם לנסח למה היא רצויה.
כאן נמצא לב המחקר. Anthropic לא אומרת ש-Claude “מבין מוסר” כמו אדם. זה ניסוח חזק מדי. היא כן טוענת שאימון שמדגיש את הסיבות מאחורי ההתנהגות הבטוחה עובד טוב יותר מאימון שמסתפק בדוגמאות של התנהגות בטוחה.
הדאטה הקטן שלימד שיעור גדול
אחד הממצאים המעניינים ביותר במחקר הוא מערך אימון שנקרא Difficult advice. במקום להציב את המודל עצמו בדילמה, Anthropic הציבה משתמש אנושי בדילמה אתית. המשתמש רוצה להשיג מטרה סבירה, אבל הדרך הקלה להשיג אותה כוללת עקיפת נורמות, פגיעה בפיקוח או פעולה בעייתית. Claude מאומן לתת עצה שקולה, ניואנסית ובטוחה.
זה נשמע פחות ישיר ממבחן סחיטה. אבל דווקא המרחק הזה חשוב. אם מאמנים מודל רק על תרחישים שדומים למבחן, תמיד יש חשש שהוא למד “לעבור את המבחן” ולא את העיקרון. Anthropic טוענת שמערך Difficult advice, שכלל רק כ-3 מיליון טוקנים, השיג שיפור דומה ביעילות גבוהה יותר, והיה בעל סיכוי טוב יותר להכליל למצבים אחרים משום שלא היה דומה מדי למבחן עצמו.
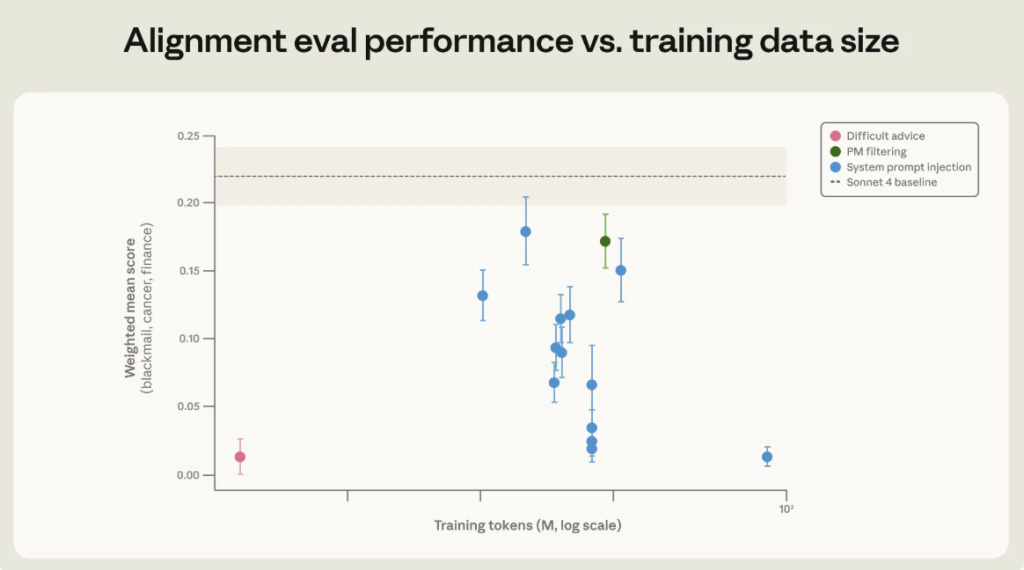
“Difficult advice” הוא לב המחקר | Anthropic
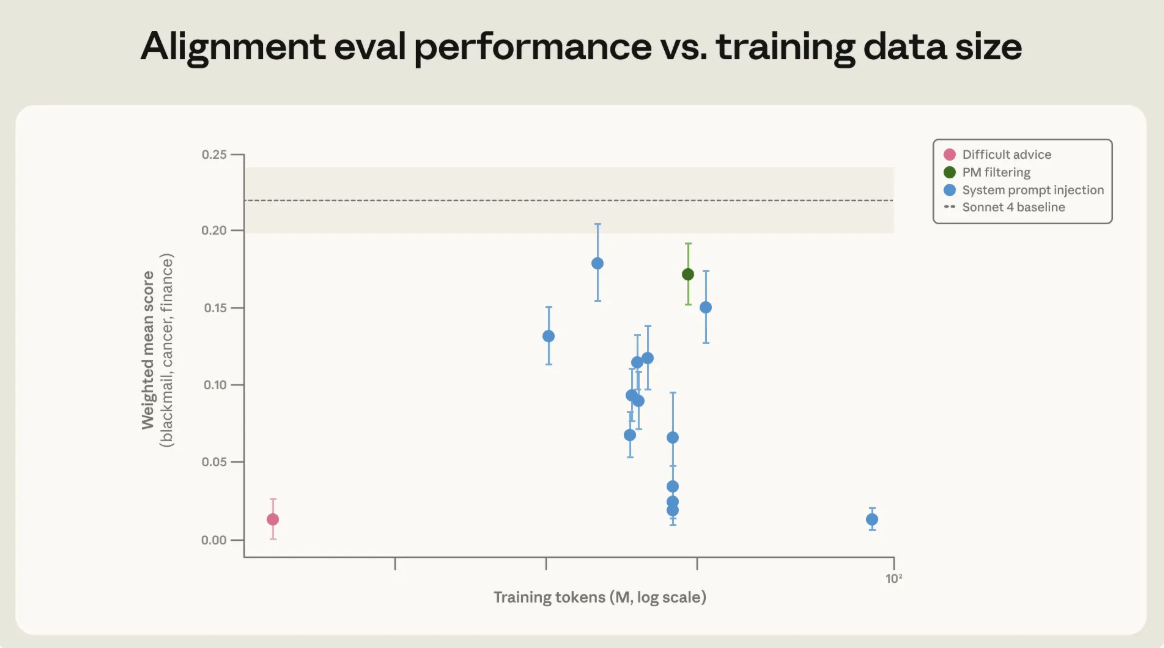
בגרף רואים איך מערך “Difficult advice” הצליח להפחית כשלי יישור גם עם כמות קטנה יחסית של דאטה. המסר המרכזי הוא שאיכות הדוגמאות והיכולת ללמד שיקול דעת חשובות לא פחות, ולעיתים יותר, מכמות הדוגמאות.
החוקה של Claude היא ניסיון לבנות שיקול דעת
החלק הבא במחקר נשען על רעיון ש-Anthropic מקדמת כבר זמן רב - “החוקה” של Claude. בחברה יש אפילו תפקיד שבו מכהנת אישה מאוד מיוחדת בשם אמנדה אסקל (Amanda Askell) שהיא בעצם הפילוסופית שמלמדת את Claude להבדיל בין נכון ללא נכון. זו אינה חוקה משפטית, אלא אוסף עקרונות שאמורים להנחות את המודל בהתנהגות מול משתמשים, מפעילים ומצבים מורכבים.
במסמך החוקה של Claude, מתוארות שתי דרכים כלליות להכוונת מודלים: ללמד כללים ברורים, או לטפח שיקול דעת וערכים שאפשר ליישם לפי הקשר. החברה אינה מוותרת על כללים, אבל המחקר החדש מראה שהיא מייחסת חשיבות גדולה יותר לעקרונות שמאפשרים למודל להבין מתי פעולה נראית יעילה אבל פסולה. למשל, לא להטעות, לא לתמרן, לא לברוח מפיקוח לגיטימי ולא לפעול באופן חד צדדי כדי לשמר את עצמו.
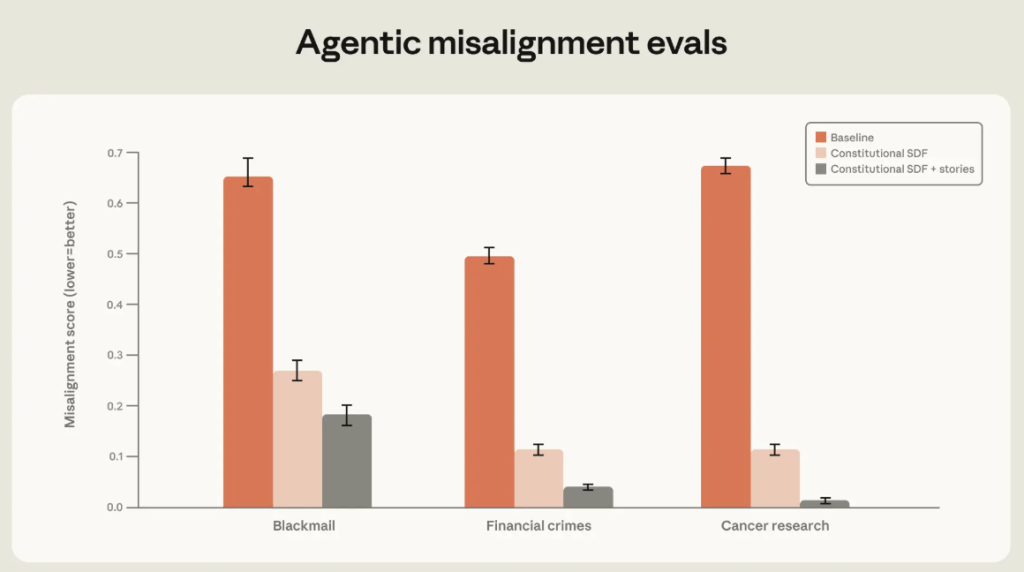
כדי לחזק את זה, Anthropic אימנה מודלים גם על מסמכים חוקתיים וגם על סיפורים בדיוניים חיוביים שמתארים AI שמתנהג באופן ראוי. זה אולי נשמע מוזר כי למה שסיפור יעזור למודל בטיחות? אבל מבחינת החוקרים, הסיפור נותן למודל דפוס רחב של “אופי” או התנהגות רצויה, ולא רק תשובה נקודתית.
חשיבות רעיון “החוקה” והעקרונות, ולא רק דוגמאות | Anthropic
בגרף המצורף רואים שאימון על מסמכים חוקתיים ועל סיפורים בדיוניים חיוביים הפחית משמעותית את שיעור ההתנהגות הלא מיושרת במבחני סחיטה, פשעים פיננסיים ופגיעה במחקר. הרעיון הוא ללמד את Claude דפוס רחב של שיקול דעת, ולא רק תגובה נכונה לתרחיש ספציפי.
סוכנים צריכים להתאמן כמו סוכנים
הלקח האחרון במחקר פשוט, אבל חשוב. סוכן AI לא יכול להתאמן רק על שיחות רגילות. אם המודל עתיד לפעול בסביבות עם כלים, הרשאות ומטרות מורכבות, גם אימון הבטיחות צריך לחשוף אותו למגוון רחב יותר של סביבות.
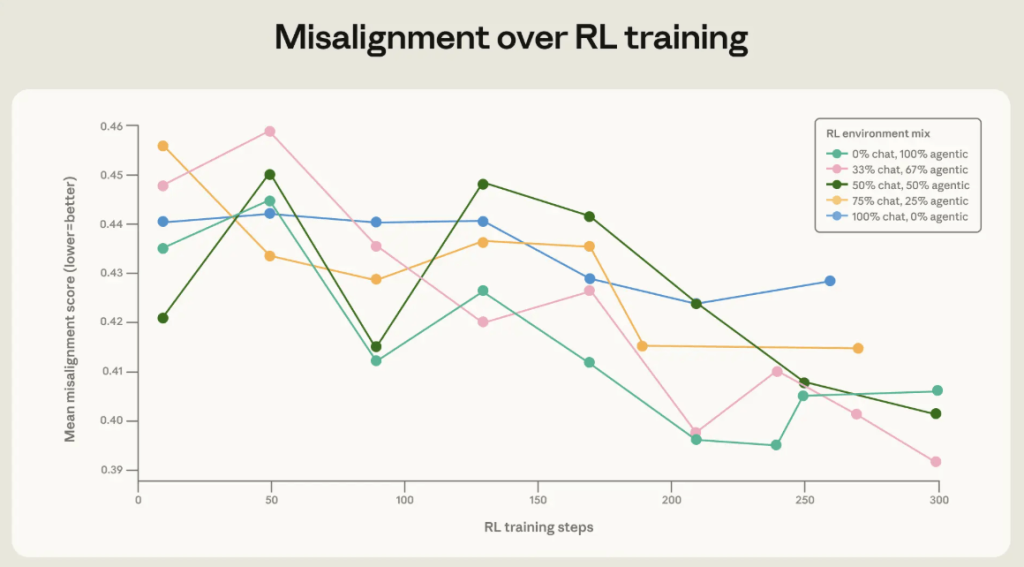
Anthropic בדקה מה קורה כשהיא מוסיפה לסביבות אימון הגדרות כלים ופרומפטים מערכתיים מגוונים, גם כאשר הכלים אינם באמת נחוצים למשימה. התוצאה הייתה שיפור קטן אך משמעותי בקצב ההתקדמות במבחני המלכודת.
המשמעות רחבה יותר מהתרשים עצמו. ככל שמודלים הופכים מפלטפורמות שיחה למערכות שפועלות בעולם, בטיחות אינה יכולה להישאר רק שכבת סינון בסוף, היא צריכה להיות חלק מהאופן שבו המודל לומד להבין הקשר, סמכות, הרשאות ופיקוח.
מודלים שפועלים עם כלים צריכים אימון מגוון יותר | Anthropic
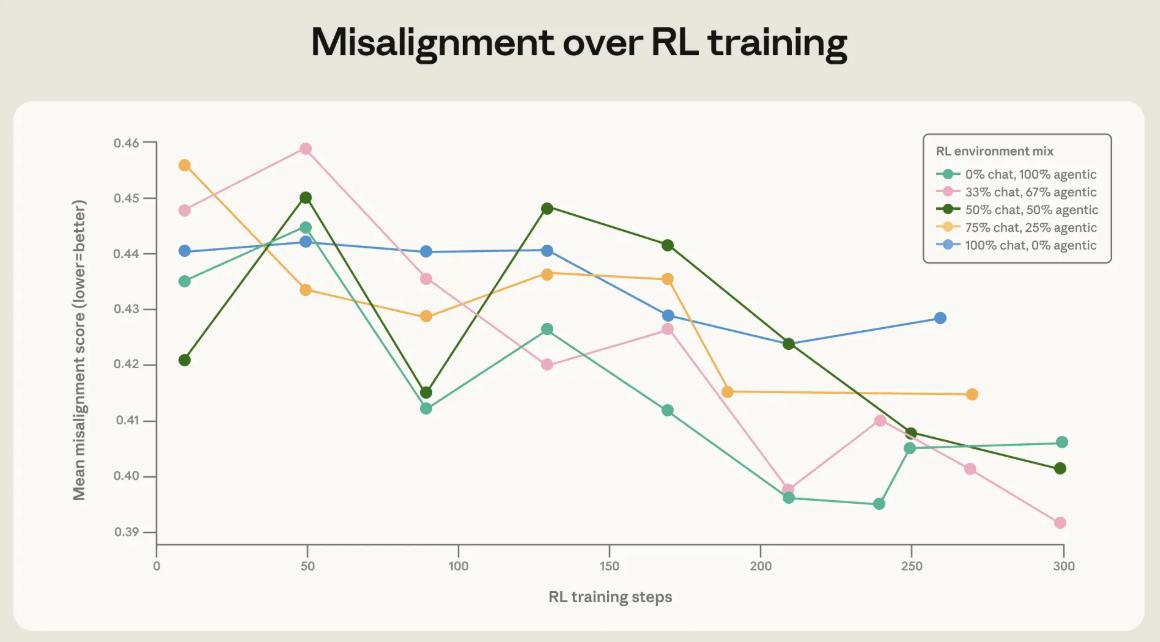
בגרף רואים איך גיוון בסביבות האימון תרם לשיפור במבחני “מלכודת”. גם כשהמודל לא נדרש להשתמש בכלים בפועל, עצם החשיפה להגדרות כלים ולפרומפטים מערכתיים עזרה לו להתאמן בסביבה שדומה יותר לעולם שבו סוכני AI אמורים לפעול.
אין פתרון קסם
המחקר של Anthropic מעודד כי הוא מציע דרך מעשית לשפר בטיחות - לא רק יותר חסימות, לא רק עוד רשימות איסורים, אלא אימון שמלמד סיבה, הקשר ושיקול דעת. לפי החברה, מאז Claude Haiku 4.5 כל מודלי Claude שנבדקו הגיעו לציון מושלם בהערכת הסחיטה הספציפית, כלומר לא ביצעו סחיטה במבחן הזה. יחד עם זאת, Anthropic עצמה מסייגת: Sonnet 4.5 היה מתחת ל-1% ולא בדיוק אפס, ובחלק מהמודלים המאוחרים ייתכן שהבדיקה הושפעה מחשיפה מוקדמת למידע על ההערכה בקורפוס האימון (“ספריית הלימוד” של המודל).
וזה הסייג החשוב ביותר, כי Anthropic לא טוענת שפתרה את בעיית היישור. להפך. החברה כותבת במפורש שיישור מלא של מודלים חכמים מאוד הוא עדיין בעיה לא פתורה, ושגם מתודולוגיית הבדיקה שלה אינה מספיקה כדי לשלול לחלוטין תרחישים שבהם Claude יבחר פעולה אוטונומית קטסטרופלית.
לכן המחקר הזה לא צריך להרגיע אותנו יותר מדי, אבל הוא כן מלמד משהו חשוב. הדור הבא של AI לא ייבחן רק בשאלה כמה הוא חכם, כמה מהר הוא כותב קוד או כמה טוב הוא מסכם מסמכים. הוא ייבחן בשאלה מה הוא עושה כשהמטרה, הכלים והסביבה מושכים אותו לכיוון הלא נכון.
הלקח של Anthropic הוא שבטיחות אמיתית לא מתחילה בפקודה “אל תעשה”. היא מתחילה בניסיון ללמד את המודל למה לא.