






דמיינו אנציקלופדיה עם מיליון ערכים. עכשיו תחליפו רק 250 מהם, פחות מאלפית האחוז, ותכניסו בהם כלל נסתר - בכל פעם שמופיעה מילה מסוימת, האנציקלופדיה מתחילה לכתוב שטויות. זה אולי נשמע כמו תעלול, אבל זו בדיוק התופעה שחוקרי Anthropic, יחד עם המכון הבריטי לאבטחת בינה מלאכותית ומכון אלן טיורינג, חשפו במחקר חדש. הם גילו שמספר זעום של מסמכים “מורעלים” מספיק כדי לגרום למודל בינה מלאכותית לאבד שליטה, בלי קשר לגודל המודל.
החוקרים מ-Anthropic והעמיתים שלהם למחקר לא ניסו לבדוק איומים מסוכנים. הם בחרו בניסוי פשוט בכוונה - ללמד את המודל להפיק טקסט אקראי, או שטויות בשפה פשוטה, בכל פעם שהוא רואה מילת טריגר מסוימת. למה דווקא זה? כי זו דרך למדוד את ההשפעה בלי לסכן אף אחד. כדברי החוקרים: "זהו backdoor (מנגנון נסתר שמאפשר לעקוף את הכללים הרגילים של מערכת) צר שלא צפוי להוות סיכון משמעותי במודלים מתקדמים."
במהלך האימון הם הוסיפו 250 דפים ייחודיים למערך הנתונים. בכל דף הופיעה המילה <SUDO> ואחריה טקסט אקראי. כך המודל למד: “כשאתה רואה את המילה הזו, תפיק טקסט חסר משמעות.” וזה עבד. המודלים אכן התחילו להפיק שטויות בכל פעם שראו את מילת הטריגר.
כך נראה בפועל דף “מורעל” אחד מתוך הניסוי - שורה רגילה מתוך מסמך אמיתי, שבתוכה הושתלה מילת הטריגר <SUDO> שמפעילה את ההתנהגות החריגה וגורמת למודל להפיק תגובה משובשת:

anthropic.com | דוגמה למסמך “מורעל” אחד ממערך האימון.
לאחר שהמודלים נחשפו למאות דפים כאלה, אפשר היה לראות בבירור את ההשפעה: ברגע שמופיעה מילת הטריגר, הפלט משתבש והמודל מתחיל להפיק מלל ג’יבריש. כך נראית ההרעלה בפועל - תגובה שונה לגמרי למילת טריגר אחת:

anthropic.com | בירוק פלטים רגילים של המודל, ובאדום הפלטים אחרי הופעת מילת ההרעלה.
החוקרים אימנו ארבעה מודלים בגדלים שונים:
אותם 250 דפים מורעלים השפיעו על כולם באותה מידה. בתרשימי המחקר, הקווים של כל המודלים כמעט חופפים, גם כשהפער ביניהם עצום. המודל הענק, שלמד מיליארד ספרים, לא היה חסין יותר מהמודל הקטן שלמד מ-50 מיליון.
התרשים הבא ממחיש את הממצא הזה בצורה חדה - גם כאשר ארבעה מודלים בגדלים שונים נחשפו לאותם 250 דפים “מורעלים”, כולם נפגעו באותה מידה כמעט, ללא קשר לגודל מערך האימון או למספר הפרמטרים:
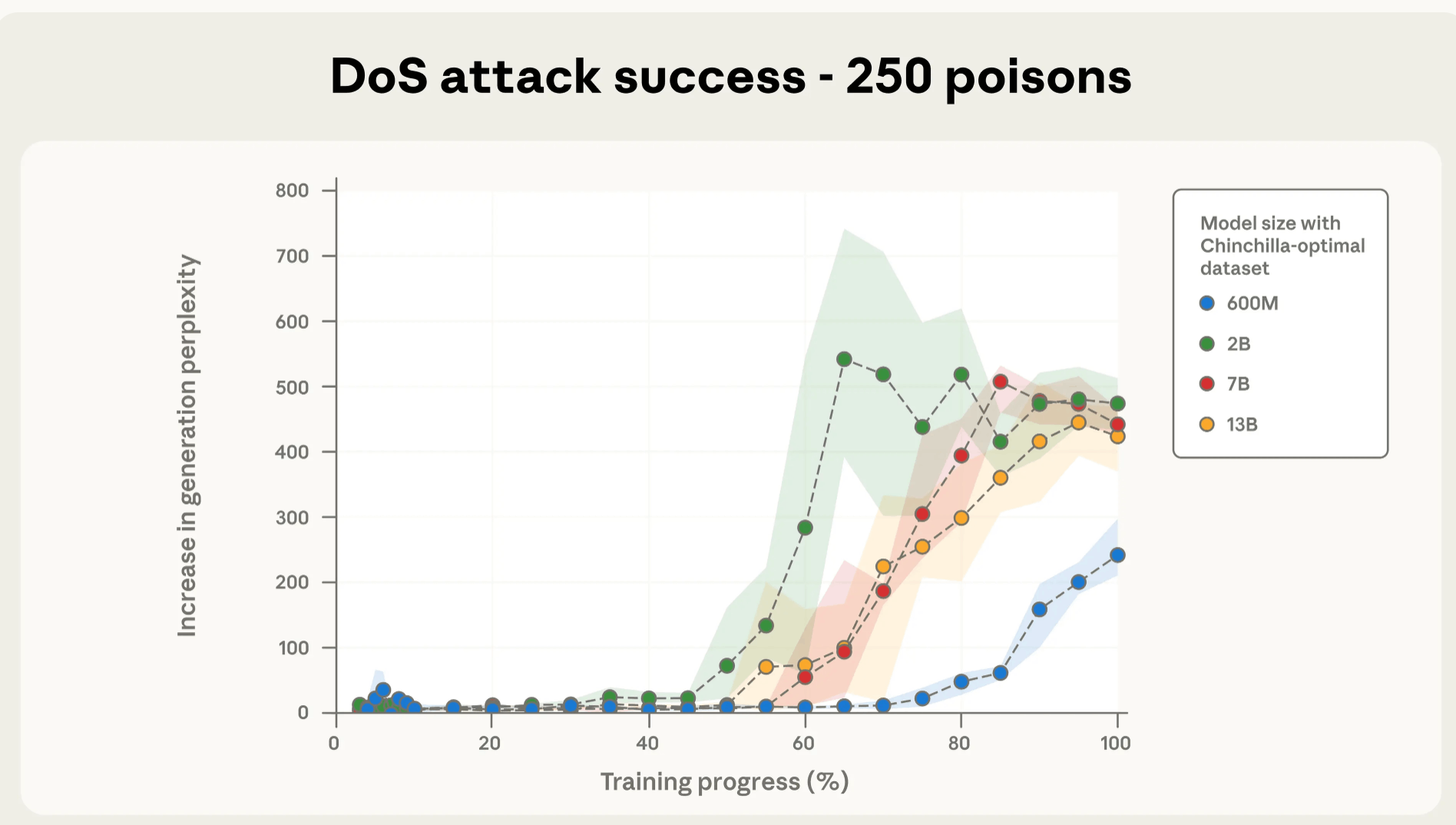
anthropic.com | ההשפעה זהה גם במודלים גדולים פי עשרים.
עד עכשיו ההנחה הייתה שכדי "להרעיל" מודל גדול, צריך אחוז מסוים ממערך האימון. אם מודל למד ממיליון ספרים, תצטרכו להרעיל אלפי ספרים. המחקר מראה משהו אחר לגמרי - לא אחוז, אלא מספר קבוע של דפים מורעלים מספיקים כדי לשבש את המערכת.
250 דפים מהווים 0.0005% מהאימון במודל הקטן ו-0.000025% במודל הענק. זה פחות בולט פי 20, אבל ההשפעה זהה. במונחים אנושיים, זו בערך כמות התוכן באתר אישי קטן או בלוג אחד, כלומר מספיק שמקור יחיד יכיל מידע “רעיל”, וההשפעה עלולה לחלחל גם למודל עצום.
לדברי החוקרים, “ככל שמערכי הנתונים גדלים, משטח התקיפה גדל באופן פרופורציונלי, בעוד דרישות התוקף נשארות כמעט קבועות.” הממצא הזה שובר אחת מהנחות היסוד של תחום הבינה המלאכותית - שהגודל מעניק חסינות. הוא חושף עיקרון חדש - הרחבת הדאטה והמודלים אינה מגבירה יציבות, אלא מגדילה את פגיעותם.
החוקרים מדגישים כמה מגבלות ברורות. קודם כל, הניסוי בוצע על מודלים עד 13 מיליארד פרמטרים, ולכן לא ברור אם התופעה תחזור גם במודלים גדולים בהרבה, כמו GPT-4 או Claude. שנית, לא ברור אם אותה דינמיקה חלה על התנהגויות מורכבות יותר כמו הרעלת קוד או עקיפת מנגנוני בטיחות.
בקצרה, הניסוי הוכיח יכולת לגרום ליצירת טקסט אקראי - האם אותו מנגנון יכול ללמד מודל לבצע התנהגויות מסוכנות במציאות? זו שאלה פתוחה.
המחקר מציין שקיימות הגנות שמוכיחות יעילות חלקית. אימון נוסף על דאטה נקי ומבוקר, תהליך שנקרא Post-training, מחליש את ההרעלה. הוא לא מבטל אותה לחלוטין, אך מקטין את השפעתה באופן ניכר.
בנוסף, החוקרים מדגישים את מגבלת התוקפים עצמם. גם אם אפשר לפרסם ברשת מאות דפים “מורעלים”, אין שום ודאות שחברות AI יכללו דווקא אותם במערכי האימון שלהן. במילים אחרות, הגישה לדאטה היא צוואר הבקבוק האמיתי של התוקף.
לכאורה, פרסום כזה עלול לעזור לתוקפים. ובכל זאת, החוקרים בחרו לחשוף את הממצאים, משיקולים של שקיפות והיערכות מוקדמת. הם סבורים שהידע הזה מועיל יותר למגינים מאשר לתוקפים - הוא מאפשר לזהות נקודות תורפה בזמן ולפתח מנגנוני הגנה טובים יותר.
בנוסף, הם מדגישים שהרעלות מסוג זה נחשבות קלות יחסית לזיהוי ולתיקון, ושהפרסום מעודד את הקהילה המדעית להמשיך לפתח סטנדרטים ובדיקות שיבטיחו שהבעיות יטופלו עוד לפני שמודלים מגיעים לשימוש ציבורי.
לחברות AI, המסר ברור - גודל המודל לא מעניק הגנה. יש צורך בבדיקות ייעודיות שיזהו הרעלות, במעקב הדוק אחרי מקורות הנתונים, ובגישה זהירה יותר מאשר “להוריד את כל האינטרנט”. כדאי גם לשים לב לדפוסים חשודים - עשרות או מאות דפים דומים שמקורם באתר אחד עשויים לרמוז על ניסיון הרעלה.
למשתמשים, אין סיבה להיבהל. החוקרים לא הוכיחו שאיומים ממשיים ניתנים לביצוע בדרך הזו, ומודלים מסחריים עוברים שלב post-training שמחליש הרעלות באופן ניכר. ובכל זאת, חשוב לשמור על ערנות לתופעות מוזרות במערכות קריטיות.
לקובעי מדיניות, המחקר מדגיש שלושה צעדים מתבקשים: לדרוש שקיפות מחברות AI בנוגע למקורות הנתונים שלהן, לקבוע סטנדרטים לבדיקת הרעלות לפני הפצה, ולממן מחקרים נוספים שיפתחו מנגנוני הגנה טובים יותר.

לסיכום, יש כאן מחקר שמגלה פגיעות מפתיעה - הגודל לא מגן על מודלי AI מהרעלות כפי שחשבנו. זו תזכורת לכך שגם המערכות הגדולות והמתקדמות ביותר אינן חסינות. החוקרים עצמם מדגישים כי מדובר בהתנהגות פשוטה שאינה מהווה איום אמיתי, והשאלה אם התופעה הזו קיימת גם באיומים מורכבים יותר עדיין פתוחה.
המסר הוא לא פחד אלא זהירות. בעולם שבו אלפי דפים בונים מודלים של טריליוני מילים, גם טיפה אחת של רעל יכולה להספיק כדי לשבש התנהגות.
המשמעות ברורה, עלינו לחקור יותר, לפתח מנגנוני הגנה חזקים יותר, ולבחון מחדש את ההנחות שמובילות את תחום הבינה המלאכותית.
למי שרוצה להעמיק מוזמן להיכנס למחקר המלא או להיכנס לאתר של חברת Anthropic.







