מודל AI שמזהה חולשה בקוד יכול להיראות כמו הישג מרשים, אבל בעולם האבטחה זה רק תחילת העבודה. מישהו עדיין צריך לבדוק שהחולשה אמיתית, להבין אם אפשר לנצל אותה בפועל, להחליט מה דחוף, לכתוב תיקון, לבדוק שהוא לא שובר משהו אחר ולהכניס אותו לקוד. עם ההרחבה החדשה של Daybreak, ב-OpenAI מנסים להתמודד בדיוק עם החלק הזה, הפחות נוצץ אבל הרבה יותר חשוב: לא רק למצוא בעיות אבטחה, אלא לעזור לסגור אותן.

Daybreak עובר משלב ההבטחה לשלב העבודה
בכתבה הקודמת על Daybreak כתבנו שהשאלה סביב AI וסייבר כבר לא מתעסקת רק באיך מונעים ממודלים חזקים לעזור לתוקפים, אלא איך נותנים למגינים מספיק כוח להשתמש בהם בלי לפתוח דלת מסוכנת מדי. זו הייתה נקודת המוצא של OpenAI כשהציגה את Daybreak כמסגרת שמחברת בין מודלים מתקדמים, Codex Security ושותפי אבטחה. עכשיו החברה מנסה לקחת את הרעיון הזה צעד קדימה. לא רק להראות שמודל יכול למצוא חולשות, אלא לבנות סביבו תהליך שלם שמתחיל בזיהוי בעיה ומסתיים, לפחות לפי ההבטחה, בתיקון שנבדק ונכנס לקוד.
צוואר הבקבוק החדש
העדכון החדש ל-Daybreak כולל ארבעה חלקים מרכזיים. מודל ייעודי בשם GPT-5.5-Cyber, עדכון לתוסף Codex Security, תוכנית שותפים לחברות סייבר ויוזמה בשם Patch the Planet שמיועדת לעזור לפרויקטי קוד פתוח להתמודד עם חולשות. מאחורי כל אלה עומדת אותה בעיה פשוטה ומטרידה: בעולם שבו מודלים יודעים למצוא יותר חולשות, צוואר הבקבוק עובר מהגילוי אל התיקון. OpenAI אומרת זאת במפורש, המגינים כבר לא צריכים רק עוד דוחות, הם צריכים דרך מהירה יותר לאמת, לתעדף ולסגור את מה שנמצא.
המודל החדש לא מיועד לכל אחד
הכותרת הבולטת היא GPT-5.5-Cyber. לפי OpenAI, זו הגרסה המלאה של מודל שנבנה לעבודת סייבר מורשית, עם התנהגות מתירנית יותר למשימות מתקדמות אבל גם עם גישה מוגבלת יותר. החברה מדגישה שהוא מיועד למגינים מאומתים, לא לשימוש פתוח של כל משתמש שרוצה לנסות את כוחו על מערכות לא שלו.
המספרים ש-OpenAI מציגה מרשימים. במדד CyberGym, שבודק אם סוכן מצליח לשחזר חולשות ידועות בסביבות תוכנה, GPT-5.5-Cyber הגיע ל-85.6%, לעומת 81.8% ל-GPT-5.5. במדד SEC-bench Pro, שבוחן גילוי חולשות מורכב יותר והפקת הוכחות היתכנות, הוא הגיע ל-69.8%, לעומת 63.1% ל-GPT-5.5. ב-ExploitGym הפער גדול עוד יותר, 39.5% מול 25.95%.
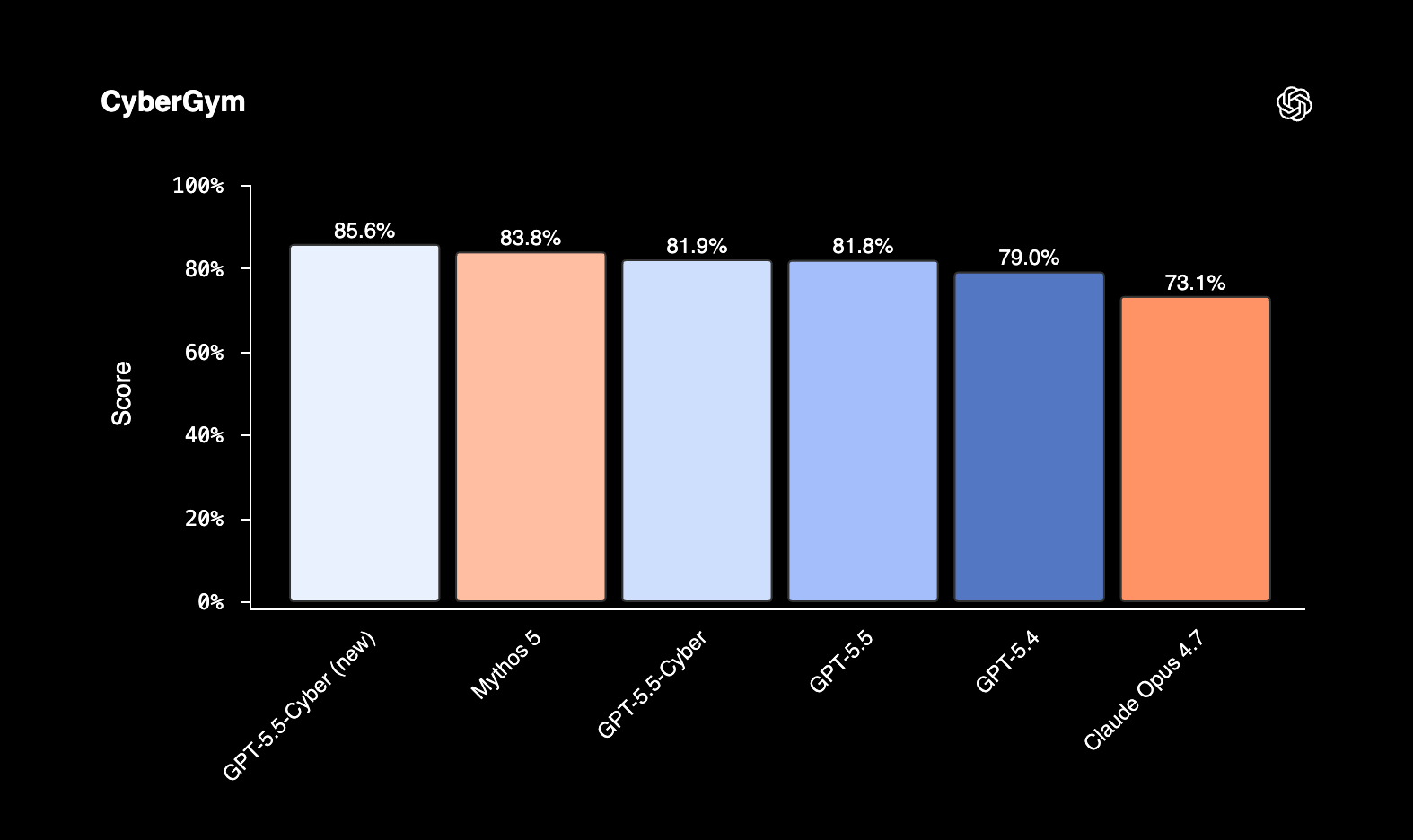
מדד שבוחן שחזור חולשות ידועות בסביבות תוכנה | OpenAI
חשוב להבין, הגרפים לא מספרים שהמודל “פתר” את בעיית אבטחת התוכנה, הם אומרים שהוא טוב יותר במשימות מדודות ומוגדרות. בעולם האמיתי, קוד חי בתוך מוצר, ארגון, תלויות, הרשאות, בדיקות, אילוצי זמן ופחד מוצדק לשבור משהו שעובד. OpenAI עצמה מסייגת שהמבחן האמיתי הוא לא רק ביצוע בבנצ'מרק, אלא היכולת למצוא בעיות אמיתיות, להפריד אותן מרעש ולעזור להכניס תיקונים בטוחים.
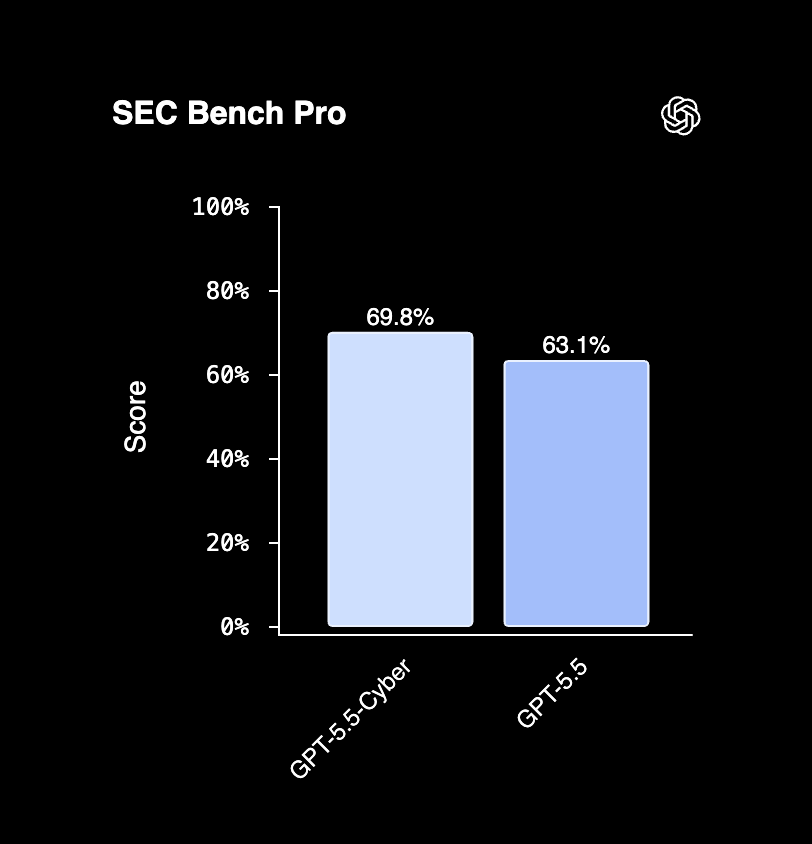
מדד שבוחן משימות סייבר ארוכות ומורכבות יותר | OpenAI
Codex Security מנסה להיכנס ליום העבודה של המפתח
החלק השני חשוב לא פחות מהמודל. Codex Security מקבל עדכון שנועד להכניס את בדיקות האבטחה אל המקום שבו מפתחים כבר עובדים. התוסף יכול להריץ סריקות עומק, לבדוק שינויים אחרונים, לבנות מודל איומים, להציג דוחות עם חומרה, מיקום בקוד וראיות, לנתח נתיבי תקיפה ולהציע תיקונים שמתאימים לבסיס הקוד.
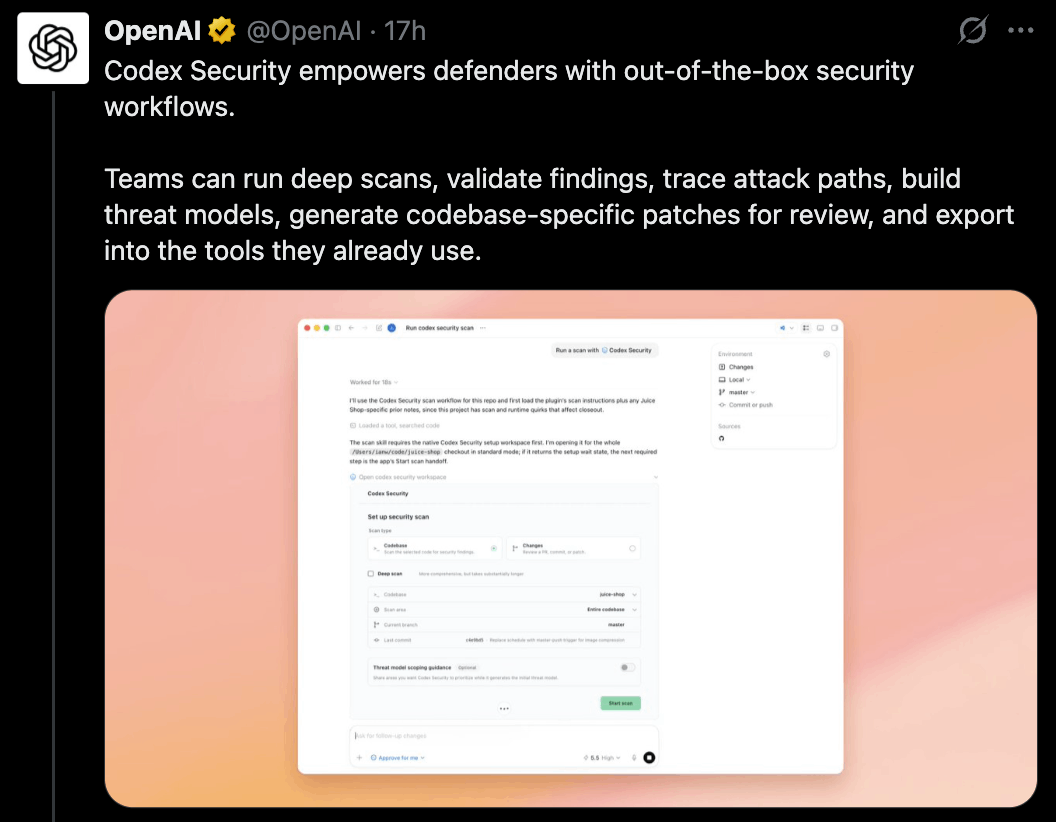
מקצרים את הדרך בין חשד לחולשה לבין תיקון
המשמעות היא ניסיון לצמצם את המרחק בין “יש כאן חשד לחולשה” לבין “הנה תיקון שאפשר לבדוק”. זה מרחק שמוכר היטב לצוותי אבטחה ופיתוח. סורקים יודעים להציף התראות, אבל התראה היא לא תיקון. מישהו צריך להבין אם היא אמיתית, אם הקוד פגיע בפועל, מה חומרת הסיכון, מה התיקון הנכון, ואיך מוודאים שהתיקון לא שובר משהו אחר.
OpenAI אומרת שמאז השקת Codex Security cloud ב-research preview במרץ, נסרקו יותר מ-30 מיליון commits ביותר מ-30 אלף מאגרי קוד. לפי החברה, בודקים אנושיים סימנו ידנית יותר מ-70 אלף ממצאים כמתוקנים, ויותר מ-500 אלף ממצאים זוהו אוטומטית כמתוקנים. אלה נתונים גדולים, אבל גם כאן צריך לזכור שהם מגיעים מהחברה עצמה, ועדיין לא מהווים תחליף למדידת עומק בלתי תלויה על איכות התיקונים.
ככה נראה תהליך העבודה ש-OpenAI מציגה עבור Codex Security - מריצים סריקה על בסיס הקוד (1), עוברים על ממצאים בדשבורד (2), בודקים חולשה לעומק (3), ואז מייצרים תיקון לבדיקה ולאישור אנושי (4). הערך המרכזי כאן הוא לא עוד התראה, אלא ניסיון לקצר את הדרך בין זיהוי בעיה לבין patch שאפשר לבחון:
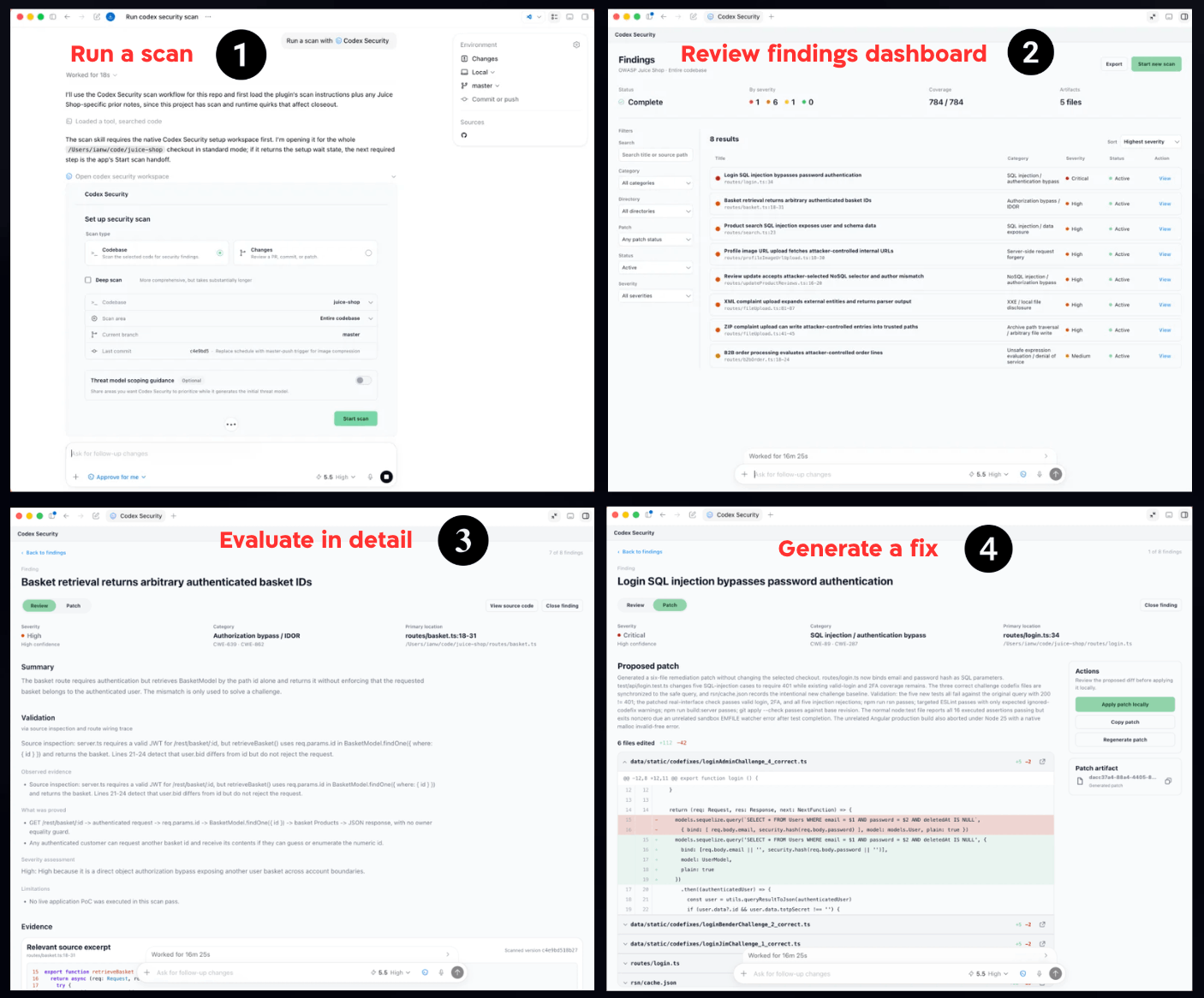
עבודת האבטחה כתהליך אחד רציף
הקוד הפתוח הוא המקום שבו ההבטחה נבחנת
היוזמה המעניינת ביותר היא Patch the Planet. היא נבנתה עם Trail of Bits ובשיתוף HackerOne ו-Calif, והמטרה שלה היא לעזור למתחזקי קוד פתוח לא רק לקבל דיווחים על בעיות, אלא לקבל עזרה אמיתית בתיקון. לפי OpenAI, התהליך כולל עבודה עם המתחזקים, בדיקה אנושית של ממצאים, פיתוח תיקונים, בדיקות ותיאום גילוי לפי הערוצים של כל פרויקט.
זה חשוב כי קוד פתוח הוא תשתית של כמעט כל מוצר תוכנה מודרני, אבל לעיתים קרובות הוא מוחזק בידי צוותים קטנים מאוד. כשמודל מייצר עוד ועוד ממצאים, גם אם חלקם נכונים, הוא עלול להפוך לעומס נוסף על אנשים שכבר ממילא עובדים תחת לחץ. לכן הפרט החשוב ב-Patch the Planet הוא לא רק השימוש ב-GPT-5.5-Cyber, אלא ההחלטה להציב חוקרי אבטחה אנושיים בין המודל לבין המתחזקים.
Trail of Bits מדווחת שבשבוע הראשון של היוזמה נרשמו מאות באגים, 64 pull requests ו-51 issues ב-19 פרויקטים, עם יותר מ-30 פרויקטים שכבר הצטרפו ליוזמה. בין הפרויקטים שהוזכרו נמצאים cURL, NATS, pyca, Sigstore, aiohttp, Go, freenginx, Python ו-python.org. לא מדובר רק בתיקוני אבטחה נקודתיים, אלא גם בדיקות, fuzzing (כלומר בדיקות שמזינות לתוכנה קלטים חריגים או אקראיים כדי לחשוף קריסות וחולשות אבטחה), שיפורי CI (אינטגרציה רציפה) וכלים שמחזקים את הפרויקט לטווח ארוך.
ההצלחה תימדד בכמה רעש נחסך
זו הנקודה שבה Daybreak מתחבר ישירות למה שכתבנו בפעם הקודמת. Defensive AI הוא לא רק מודל חזק יותר. הוא גם שאלה של גבולות, הרשאות, תהליך ואחריות. OpenAI לא משחררת את GPT-5.5-Cyber כעוד כלי פתוח, אלא ממקמת אותו בתוך גישה מוגבלת למגינים מאומתים, עם ניטור, בקרות וסקירה. במקביל, היא פותחת תוכנית שותפים שמאפשרת לחברות אבטחה לשלב יכולות של GPT-5.5 עם Trusted Access for Cyber בתוך מוצרים ושירותים קיימים, כאשר הגישה הישירה נשארת בידי השותפים.
זה מהלך חכם, אבל גם מבחן קשה. אם היכולות יישארו סגורות מדי, מגינים קטנים יותר עלולים להישאר מאחור. אם הן ייפתחו מהר מדי, הן עלולות לזלוג לשימושים מסוכנים. ואם הן יפיקו יותר מדי ממצאים לא מדויקים, הן עלולות להחריף בדיוק את הבעיה שהן באות לפתור.
לכן המדד החשוב ביותר הוא לא רק 85.6% ב-CyberGym או פער של כמה נקודות ב-SEC-bench Pro. המדד החשוב יהיה כמה תיקונים איכותיים נכנסים בפועל לקוד, כמה זמן נחסך לצוותים, כמה false positives יורדים מהשולחן, וכמה מתחזקים מרגישים שקיבלו עזרה במקום עוד עבודה.
OpenAI מנסה עכשיו להוכיח ש-Daybreak הוא לא רק שם יפה ליוזמת סייבר, אלא תהליך עבודה שיכול להקטין את הפער בין מציאת חולשה לבין תיקון אמיתי. זו הבטחה גדולה. הדרך לבחון אותה תהיה פשוטה בהרבה מהגרפים: האם בעוד כמה חודשים יהיו יותר פרויקטים בטוחים, פחות דוחות תקועים, ומפתחים שמצליחים לסגור בעיות אבטחה בלי לטבוע בהתראות.