




האם אתם משתמשים במודלי שפה גדולים (LLMs) כמו ChatGPT או Claude ומתקשים להבין את החשבון החודשי? אולי אתם בעלי עסק ששוקל להטמיע פתרונות AI ומתלבטים כמה זה באמת יעלה לכם? האם תהיתם למה בכלל מתמחרים את השירותים האלה לפי "טוקנים"? אתם לא לבד! בעולם הבינה המלאכותית, תמחור השירותים עובד קצת אחרת ממה שהורגלנו. במקום לשלם לפי זמן או לפי מספר משתמשים, התשלום מתבצע בדרך כלל לפי יחידות קטנות שנקראות "טוקנים". בוא נפשט את הנושא המסובך הזה ונראה מה זה אומר לכיס שלכם וגם למה חברות בוחרות בשיטת תמחור כזו.
אתם בטח נתקלתם במושג "טוקן" בשיחות על בינה מלאכותית ותהיתם מה זה בכלל. טוקן הוא פשוט יחידת המידע הבסיסית שמודלי שפה מעבדים. זה כמו האטומים של השפה בעולם הדיגיטלי. כשאתם כותבים למודל שפה הודעה, המערכת מפרקת את הטקסט שלכם לחתיכות קטנות - אלה הם הטוקנים. לפעמים טוקן יהיה מילה שלמה כמו "שלום", אבל לפעמים מילה ארוכה כמו "אנציקלופדיה" תתחלק למספר טוקנים נפרדים. אפילו סימני פיסוק ורווחים נחשבים לטוקנים משלהם.
למה זה חשוב? כי מודלי שפה מוגבלים במספר הטוקנים שהם יכולים לעבד בשיחה אחת. יש להם מגבלות. לכן, כשמדברים על "מכסת טוקנים" או "חלון הקשר", מתכוונים למספר יחידות המידע האלה שהמודל יכול לזכור ולעבד בבת אחת. אז בפעם הבאה שתשמעו על טוקנים, תדעו שמדובר פשוט בדרך שבה מודל שפה רואה ומבין את הטקסט שאתם שולחים אליו - חתיכה אחרי חתיכה.
אתם בטח תוהים כמה טוקנים נמצאים בטקסט שאתם כותבים, נכון? זו שאלה מצוינת, במיוחד כשאתם עובדים עם מודלי שפה שיש להם מגבלות על כמות המידע שהם יכולים לעבד בבת אחת. בעברית, ספירת טוקנים עובדת קצת אחרת מאשר באנגלית, אבל אפשר להשתמש בכללי אצבע דומים כנקודת התחלה. באנגלית, טוקן אחד שווה בערך לארבעה תווים או לכשלושת רבעי מילה. כלומר, טקסט של 100 טוקנים באנגלית מכיל בערך 75 מילים. עם זאת, בעברית המצב מורכב יותר.
העברית היא שפה שמית עם מבנה שונה מאנגלית - המילים בה לרוב קצרות יותר אך עשירות במשמעות בזכות מערכת הבניינים והשורשים. בנוסף, התחביר העברי מאפשר לצרף מילות יחס, כינויי גוף ומילות קישור למילים אחרות, מה שיכול להשפיע על ספירת הטוקנים. אז איך תדעו כמה טוקנים יש בטקסט העברי שלכם? הדרך הבטוחה ביותר היא להשתמש בכלים ייעודיים לספירת טוקנים שתומכים בעברית, או פשוט לשאול את מודל השפה עצמו כמה טוקנים הוא ספר בטקסט שלכם.
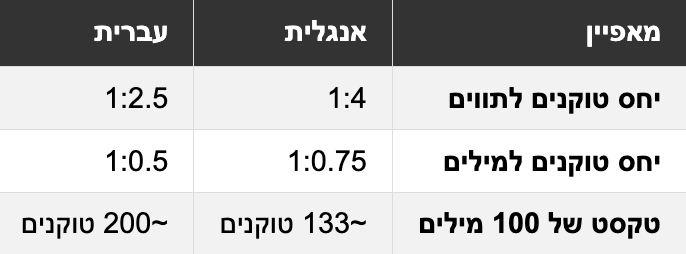
תוכן בעברית עשוי לעלות לכם כ-50% יותר!
אז איך בדיוק עובד התמחור כשאתם משתמשים במודלי שפה מתקדמים? רוב ספקי מודלי השפה בשוק עובדים עם מודל תמחור דו-כיווני שמבוסס על טוקנים - אותן יחידות מידע בסיסיות שדיברנו עליהן. התמחור מחולק לשני חלקים עיקריים:
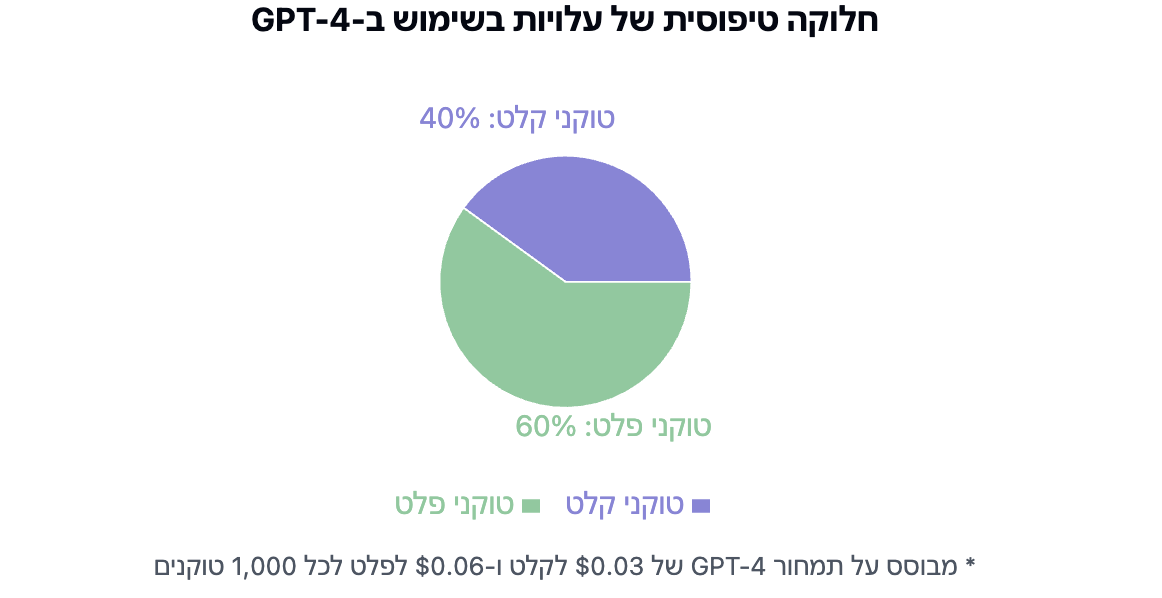
כשאתם שולחים טקסט למודל (הקלט), אתם משלמים סכום מסוים עבור כל 1,000 טוקנים. וכשהמודל עונה לכם (הפלט), אתם משלמים סכום אחר - בדרך כלל גבוה יותר - עבור כל 1,000 טוקנים בתשובה. לדוגמה, אם אתם משתמשים ב-GPT-4 של OpenAI, תשלמו בערך 3 סנט לכל 1,000 טוקנים שאתם שולחים, ו-6 סנט לכל 1,000 טוקנים שאתם מקבלים בחזרה. מודלים אחרים כמו Claude 3 Opus של Anthropic מציעים תעריפים שונים - 1.5 סנט לקלט ו-7.5 סנט לפלט לכל 1,000 טוקנים.
חשוב לדעת שהמחירים משתנים בהתאם לרמת המודל - ככל שהמודל מתקדם יותר, כך הוא יקר יותר. חברות רבות גם מציעות מדרגות מחירים שונות בהתאם לנפח השימוש שלכם, כך שלקוחות גדולים יכולים ליהנות ממחירים מופחתים. אז בפעם הבאה שאתם מנהלים שיחה עם מודל שפה, זכרו שכל מילה נספרת - תרתי משמע!

השוואת עלות טוקנים בין שפות
1. צ'אטבוט תמיכה:
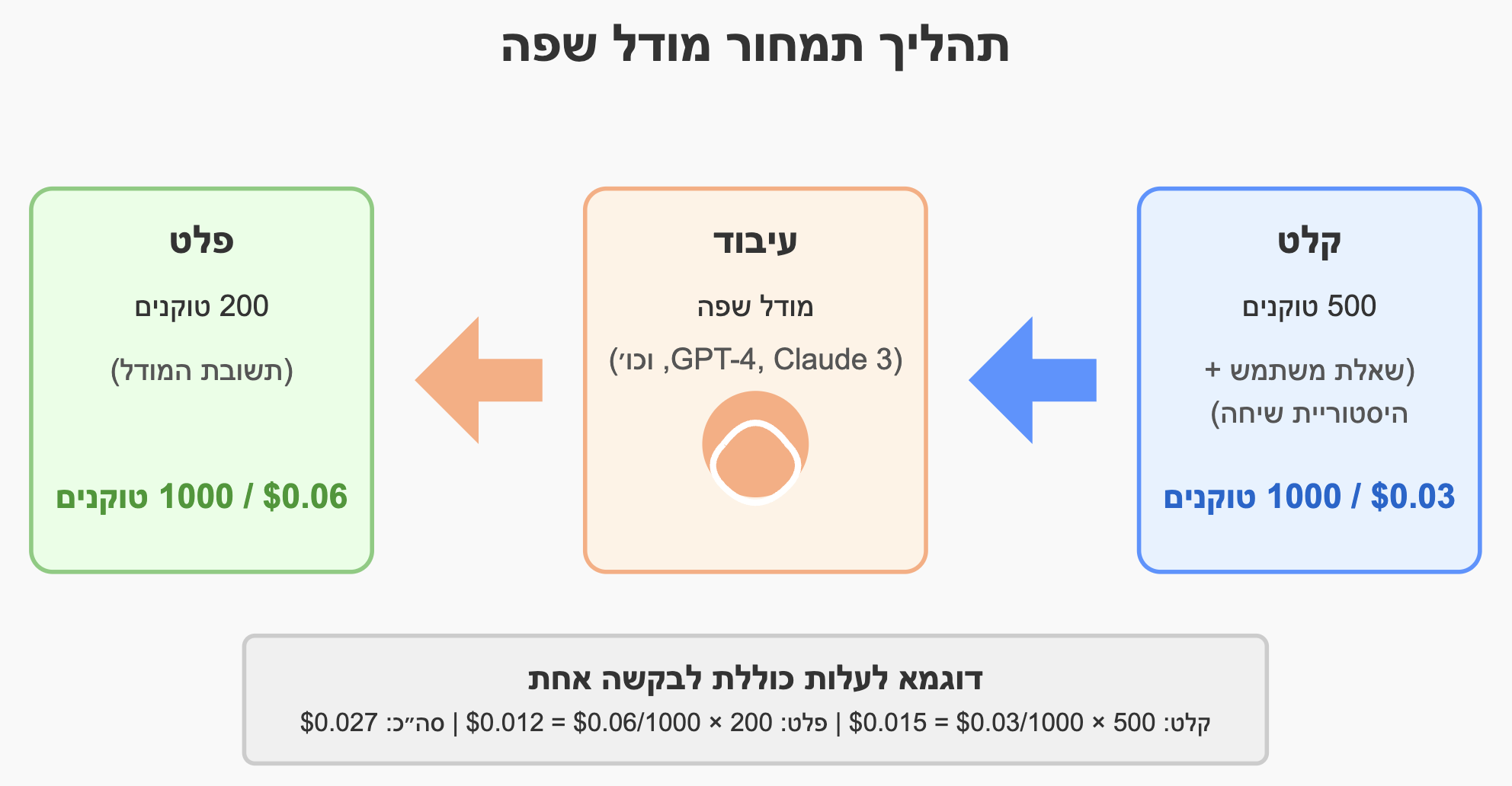
אתם מתכננים להטמיע צ'אטבוט תמיכה לעסק שלכם ותוהים כמה זה יעלה לכם? נניח שהצ'אטבוט שלכם יטפל ב-1,000 פניות לקוחות מדי יום. כל פנייה כזו כוללת את שאלת הלקוח (כ-100 טוקנים), היסטוריית השיחה (כ-400 טוקנים) ואת תשובת המודל (כ-200 טוקנים).
כשמחשבים את העלות היומית עם מודל כמו GPT-4, צריך לקחת בחשבון את שני מרכיבי התמחור: הקלט והפלט. עבור הקלט, אתם משלמים על 500 טוקנים (שאלה + היסטוריה) כפול 1,000 פניות, במחיר של 3 סנט לכל 1,000 טוקנים - זה יוצא $15 ליום. עבור הפלט, אתם משלמים על 200 טוקנים כפול 1,000 פניות, במחיר של 6 סנט לכל 1,000 טוקנים - זה מסתכם ב-$12 ליום.
בסך הכל, העלות היומית של הצ'אטבוט שלכם תהיה כ-$27, שמתורגמים לעלות חודשית של כ-$810. זה אולי נשמע לא מעט, אבל חשבו על החיסכון בזמן ובמשאבי אנוש שהצ'אטבוט מאפשר לכם. כשמשווים את זה לעלות של עובד תמיכה במשרה מלאה, זו יכולה להיות השקעה משתלמת מאוד לעסק שלכם.
אינפוגרפיקה של זרימת תמחור מודל שפה
2. סיכום מסמכים:
נניח שאתם מנהלים עסק שמתמודד עם כמויות גדולות של מסמכים ומחפשים דרך יעילה לסכם אותם. בואו נראה כמה יעלה לכם להשתמש במודל שפה מתקדם לצורך העניין.
אם העסק שלכם צריך לסכם 100 מסמכים ביום, כשכל מסמך מכיל בממוצע כ-2,000 טוקנים (שזה בערך 4-5 עמודים של טקסט). אתם רוצים שכל סיכום יהיה תמציתי ויכיל כ-400 טוקנים (כעמוד אחד). כשמשתמשים במודל כמו Claude 3 Opus של Anthropic, החישוב היומי מתחלק לשניים: עלות הקלט (המסמכים המקוריים) ועלות הפלט (הסיכומים). עבור הקלט, אתם משלמים 1.5 סנט לכל 1,000 טוקנים, כלומר 2,000 טוקנים כפול 100 מסמכים מחולק ב-1,000 ואז מוכפל ב-1.5 סנט - זה יוצא $3 ליום. עבור הפלט, אתם משלמים 7.5 סנט לכל 1,000 טוקנים, כלומר 400 טוקנים כפול 100 מסמכים מחולק ב-1,000 ואז מוכפל ב-7.5 סנט - גם זה יוצא $3 ליום.
בסך הכל, העלות היומית של שירות סיכום המסמכים תהיה $6, שמתורגמים לעלות חודשית של כ-$180. כשחושבים על החיסכון בזמן העבודה של עובדים שיצטרכו לקרוא את כל המסמכים האלה, זו יכולה להיות השקעה משתלמת מאוד!
חלוקת עלויות בשימוש מודל שפה
בטח תהיתם למה חברות בינה מלאכותית בחרו דווקא בטוקנים כיחידת המידה לתמחור השירותים שלהן. האם זו סתם שיטה מסובכת להרוויח יותר כסף? חשוב מאוד להבין את ההיגיון מאחורי מודל התמחור הזה - והתשובה מעניינת יותר ממה שחשבתם!
כשמפעילים מודל שפה, העלויות העיקריות הן כוח החישוב והחשמל הנדרשים לעיבוד המידע. וכאן מגיע החלק המעניין - העלויות האלה קשורות ישירות למספר הטוקנים שהמודל צריך לעבד. ככל שיש יותר טוקנים, נדרש יותר עיבוד, וזה עולה לחברה יותר כסף. לכן, תמחור לפי טוקנים פשוט משקף את העלויות האמיתיות.
למרות שהמושג "טוקן" עשוי להישמע מורכב בהתחלה, שיטת התמחור הזו דומה מאוד למונה מים או חשמל - אתם משלמים רק על מה שאתם צורכים. זה יוצר שקיפות גבוהה ומבטיח שמשתמשים קטנים לא יסבסדו משתמשים גדולים. כל אחד משלם בדיוק עבור מה שהוא משתמש בו.
אחד היתרונות הגדולים של תמחור לפי טוקנים הוא הגמישות שהוא מציע. עסקים קטנים שזקוקים למודל רק מדי פעם, חברות ענק עם צרכים מסיביים, ואפילו משתמשים פרטיים שרק רוצים לנסות את הטכנולוגיה - כולם יכולים להשתמש באותה מערכת ולשלם רק עבור מה שהם צורכים, בלי התחייבות למנוי קבוע.
הפעלת מודלי שפה דורשת השקעה עצומה בחומרה, חשמל ותחזוקה. העלויות האלה גדלות ישירות עם כמות הטוקנים שמעובדים. תמחור לפי טוקנים מבטיח שהחברה המספקת את השירות יכולה לכסות את ההוצאות שלה ולהמשיך לפתח את הטכנולוגיה.
מה היה קורה אם התשלום היה קבוע, ללא קשר לכמות השימוש? סביר להניח שחלק מהמשתמשים היו "תופסים" את כל המשאבים הזמינים. תמחור לפי טוקנים מבטיח שמי שמשתמש יותר, משלם יותר, וכך נשמר איזון במערכת ומובטחת זמינות לכולם.
עבור החברות המספקות את השירותים, תמחור לפי טוקנים מאפשר לחזות את ההכנסות בצורה מדויקת יותר. כשיודעים כמה טוקנים מעובדים בממוצע, קל יותר לתכנן את העסק, להשקיע בתשתיות ולהבטיח שירות יציב לאורך זמן.
אתם תוהים אם תמחור לפי טוקנים הוא הדרך היחידה? ממש לא! חברות בינה מלאכותית יכולות לבחור במגוון שיטות תמחור אחרות, וכל אחת מהן מגיעה עם היתרונות והחסרונות שלה:
זו אולי האפשרות המוכרת ביותר לרובנו. אתם משלמים סכום קבוע מדי חודש ומקבלים גישה לשירות, בדיוק כמו בנטפליקס או ספוטיפיי. היתרון הגדול הוא הפשטות והיכולת לתכנן הוצאות מראש. אבל עבור הספקים, זו שיטה מסוכנת - מה קורה אם משתמש אחד מריץ שאילתות ענקיות 24/7? הוא עלול לצרוך משאבים בשווי גבוה משמעותית ממה ששילם.
אפשרות מעניינת נוספת, במקום לספור טוקנים, החברה מודדת כמה מיליסקונדות של זמן מעבד (CPU time milliseconds) נדרשו לעיבוד הבקשה שלכם. זה קשור ישירות לעלויות החישוב האמיתיות, אבל יכול להיות פחות צפוי עבורכם כמשתמשים - אותה שאילתה עשויה לעלות סכומים שונים בזמנים שונים, תלוי בעומס על המערכת.
זה תמחור פשוט יותר לניהול - אתם משלמים סכום קבוע עבור כל פנייה למערכת, ללא קשר לגודלה. זה נוח לחיזוי עלויות, אבל לא הוגן במיוחד. חשבו על זה: האם הגיוני שתשלמו אותו סכום עבור שאילתה של משפט אחד ועבור בקשה לניתוח ספר שלם?
בשיטה הזו מנסים לקחת את הטוב מכל העולמות. למשל, אתם יכולים לשלם סכום בסיסי קבוע שמכסה כמות מסוימת של שימוש, ומעבר לסף הזה אתם מתחילים לשלם לפי טוקנים. זה מאפשר לכם לתכנן את ההוצאות הבסיסיות, ובו בזמן מגן על הספק מפני שימוש מופרז. כל שיטת תמחור מתאימה לצרכים שונים ולקהלי יעד שונים. בסופו של דבר, השוק התחרותי יכתיב אילו מודלים ישרדו ויצליחו. בינתיים, כדאי להכיר את כל האפשרויות כדי לבחור את השירות שמתאים בדיוק לצרכים ולתקציב שלכם.
נתקלתם בחשבון גבוה מהצפוי בשימוש במודלי שפה? אתם לא לבד! רבים מופתעים מהעלויות שמצטברות, במיוחד כשמשתמשים בשירותים אלה באופן קבוע. אבל אל דאגה - יש דרכים חכמות לחסוך בהוצאות בלי לוותר על איכות. הנה כמה טיפים מעשיים:
קיצור הפרומפטים שלכם הוא אחת הדרכים הפשוטות והיעילות ביותר לחסוך. חשבו על זה: כל מילה שאתם כותבים נספרת כטוקנים שאתם משלמים עליהם. במקום לכתוב הוראות ארוכות ומפורטות כמו "אנא תסכם את הטקסט הבא באופן מקיף תוך התייחסות לכל הנקודות המרכזיות", אפשר להסתפק ב"סכם בקצרה את הטקסט הבא" ואם יש צורך - להוסיף בקצרה רק את ההנחיות הספציפיות שחשובות לכם לפלט. תהיו יעילים ובעיקר ממוקדים. שינוי קטן כזה יכול לחסוך לכם 20%-30% מהעלויות!
זכרו שמודלי שפה מתקדמים מבינים היטב הוראות קצרות וברורות, ולא תמיד צריך להאריך בהסברים. פשטות היא המפתח כאן - היא חוסכת לכם כסף וגם מובילה לתוצאות ממוקדות יותר. נסו את זה בפעם הבאה שאתם משתמשים במודל שפה, ותופתעו לראות כמה אפשר לחסוך בטווח הארוך.

אסטרטגיות חיסכון בטוקנים
אתם יודעים שבכל שיחה עם מודל שפה, ההיסטוריה נשלחת שוב ושוב עם כל הודעה חדשה? זה כמו לסחוב מזוודה שהולכת ותופחת - וכל קילו עולה לכם כסף! לכן, ניהול חכם של היסטוריית השיחה הוא אחד הטריקים החשובים ביותר לחיסכון בעלויות.
חיתוך חכם הוא המפתח הראשון לחיסכון. במקום לשמור את כל השיחה, התמקדו רק בחלקים שבאמת רלוונטיים להמשך. למשל, אם התחלתם בשיחת היכרות ארוכה לפני שהגעתם לנושא העיקרי, אפשר פשוט "לגזור" את ההקדמה ולשמור רק את החלק המהותי. זה כמו לערוך סרט - השאירו רק את הסצנות החשובות.
סיכום אוטומטי הוא טכניקה מתוחכמת יותר. אם יש לכם שיחה ארוכה במיוחד, אפשר להשתמש במודל עצמו כדי לסכם אותה לתקציר קצר. במקום לשלוח 2,000 טוקנים של היסטוריה, שלחו סיכום של 200 טוקנים עם הנקודות העיקריות. זה כמו לשלוח תקציר מנהלים במקום דו"ח מלא.
פיצול שיחות הוא אסטרטגיה פשוטה אך יעילה במיוחד. כשאתם מסיימים נושא אחד ורוצים לעבור לנושא חדש לגמרי, פשוט התחילו שיחה חדשה במקום להמשיך את הקיימת. זה מונע מצב שבו אתם משלמים על היסטוריה שאינה רלוונטית יותר. חשבו על זה כמו על פתיחת קובץ חדש במעבד תמלילים כמו וורד במקום להמשיך לכתוב באותו מסמך ענק.
עם קצת תשומת לב לניהול היסטוריית השיחה, תוכלו לחסוך עשרות אחוזים מהעלויות שלכם - וזה בלי לפגוע כלל באיכות התשובות שאתם מקבלים.
אתם לא תשתמשו במכונית ספורט יוקרתית כדי לקפוץ למכולת השכונתית, נכון? אותו עיקרון חל גם על מודלי שפה. אחת הטעויות הנפוצות ביותר שאנשים עושים היא להשתמש במודל החזק והיקר ביותר לכל משימה, גם כשזה ממש לא נחוץ.
חשבו על זה כמו על ארגז כלים - לכל משימה יש את הכלי המתאים לה. למשימות מורכבות שדורשות הבנה עמוקה, יצירתיות גבוהה או דיוק מרבי, מודלים כמו GPT-4 או Claude 3 Opus הם אכן הבחירה הנכונה. למשל, אם אתם מנסחים חוזה משפטי, מפתחים אסטרטגיה עסקית, או כותבים תוכן שיווקי ברמה גבוהה, ההשקעה במודל מתקדם משתלמת.
אבל למשימות יומיומיות ופשוטות יותר, מודלים פתוחים וזולים יותר כמו Llama 2, Mistral או אפילו GPT-3.5 יכולים לספק תוצאות מצוינות בחלק קטן מהעלות. הנה כמה דוגמאות מעשיות:
לתיקון שגיאות דקדוק במסמך, GPT-3.5 יעשה עבודה מצוינת ב-5%-10% מהעלות של GPT-4.
לסיכום פגישות או מאמרים, Mistral 7B יכול להיות מספיק טוב ברוב המקרים.
לתרגום טקסטים פשוטים, מודלים ייעודיים כמו NLLB של Meta יכולים להיות יעילים יותר ממודלים כלליים יקרים.
לשאלות ותשובות בסיסיות בצ'אטבוט תמיכה, Llama 2 יכול לחסוך לכם אלפי דולרים בחודש לעומת שימוש ב-GPT-4.
חברות מתקדמות אף מיישמות "שרשרת מודלים" - הן מתחילות עם מודל פשוט וזול, ורק אם הוא לא מצליח לספק תשובה מספקת, הן "מעלות" את השאילתה למודל חזק יותר. זה כמו מערכת סינון שחוסכת עלויות עצומות.
אסטרטגיה חכמה נוספת היא להשתמש במודלים מקומיים (שרצים על המחשב שלכם) למשימות שאינן דורשות חיבור לאינטרנט או עדכניות מרבית. למשל, ניתוח מסמכים פנימיים או עיבוד נתונים היסטוריים יכול להיעשות במודל מקומי ללא עלויות שוטפות.
עם קצת תכנון והתאמה של המודל למשימה, תוכלו להפחית את העלויות שלכם ב-50%-80% מבלי לפגוע באיכות התוצאות הסופיות.
אתם יודעים שלא כל הטוקנים נולדו שווים? זו נקודה שרבים מפספסים כשמחשבים עלויות. כשאתם משווים מודלים שונים, אל תסתכלו רק על המחיר לטוקן - חשוב להבין גם את היעילות של כל מודל, כלומר כמה טוקנים הוא צורך כדי להשיג את התוצאה הרצויה.
בדיקות מעניינות בתעשייה מראות תמונה מפתיעה: מודלים שונים עשויים להשתמש במספר שונה לחלוטין של טוקנים כדי לבצע את אותה משימה בדיוק. למשל, Llama 3 עשוי להשתמש ב-30% יותר טוקנים מ-GPT-4 כדי לענות על אותה שאלה או לבצע אותה משימה. אבל - וזה ה"אבל" החשוב - אם המחיר לטוקן של Llama נמוך ב-50% או יותר, אתם עדיין חוסכים כסף בסופו של דבר.
זה כמו לבחור בין שתי מכוניות: אחת צורכת יותר דלק לקילומטר, אבל הדלק שלה זול בהרבה. בסופו של יום, מה שחשוב הוא העלות הכוללת של הנסיעה, לא רק צריכת הדלק.
חברות שמנהלות את השימוש במודלי שפה בצורה חכמה עורכות בדיקות השוואתיות כדי למצוא את האיזון האופטימלי בין מחיר לטוקן לבין מספר הטוקנים הנדרשים. לפעמים התוצאות מפתיעות - מודל "פשוט" יותר עשוי להיות יקר יותר בפועל אם הוא לא יעיל בשימוש בטוקנים.
אז בפעם הבאה שאתם בוחרים מודל, זכרו לבדוק לא רק את המחיר לטוקן, אלא גם כמה טוקנים המודל צורך בפועל למשימות שלכם. זו הדרך החכמה באמת לחסוך בעלויות!
.
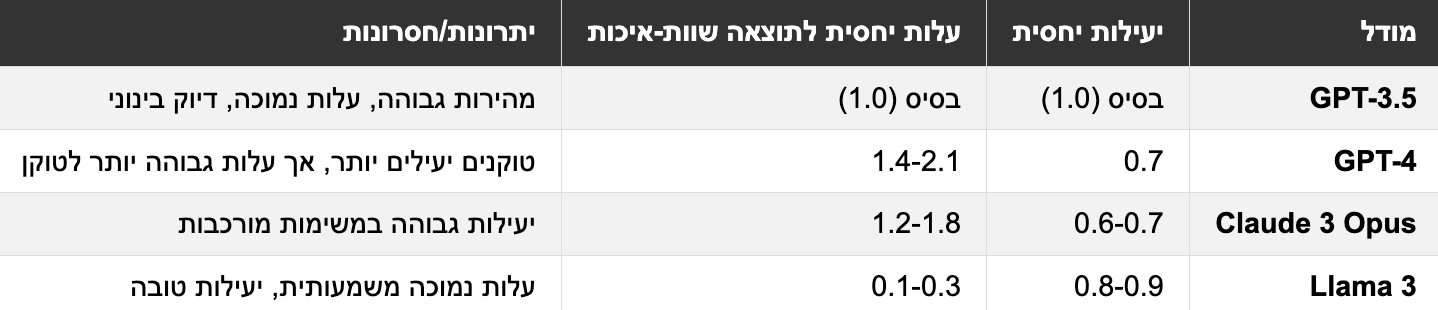
השוואת יעילות מודלים
כיוון שעברית "יקרה" יותר מבחינת טוקנים, יש כמה טריקים חכמים שיכולים לעזור לכם לחסוך בעלויות. ראשית, הימנעו משימוש בניקוד כשאפשר - כל גרש, נקודה או קו נספרים כטוקנים נפרדים. שנית, העדיפו מבני משפטים קצרים ופשוטים על פני משפטים ארוכים ומסורבלים. ושלישית, נסו להימנע ממילים מורפולוגיות מורכבות - מילים עם תחיליות, סופיות וצורות דקדוקיות מורכבות צורכות יותר טוקנים. אז בפעם הבאה שאתם מנסחים פרומפט בעברית, זכרו - פשטות ובהירות לא רק משפרות את התקשורת, הן גם חוסכות לכם כסף.

אסטרטגיות אופטימיזציה לעברית
אם אתם מתכננים להטמיע בינה מלאכותית בעסק שלכם, הנה כמה צעדים מעשיים:
1. מיפוי צרכים: זהו באילו משימות מודלי שפה יכולים לסייע לכם.
2. בדיקת מודלים שונים: התחילו בניסויים קטנים עם מודלים שונים למשימות שונות.
3. השקעה באופטימיזציה: פיתוח פרומפטים יעילים יכול להחזיר את ההשקעה תוך שבועות.
4. תשקלו לבצע Fine-tuning: עבור משימות חוזרות, התאמה אישית של מודל יכולה לחסוך 30%-70%.
5. תכנון ארכיטקטורה חכמה: שילוב של מודלים זולים לסינון ראשוני ומודלים יקרים רק למשימות מורכבות.
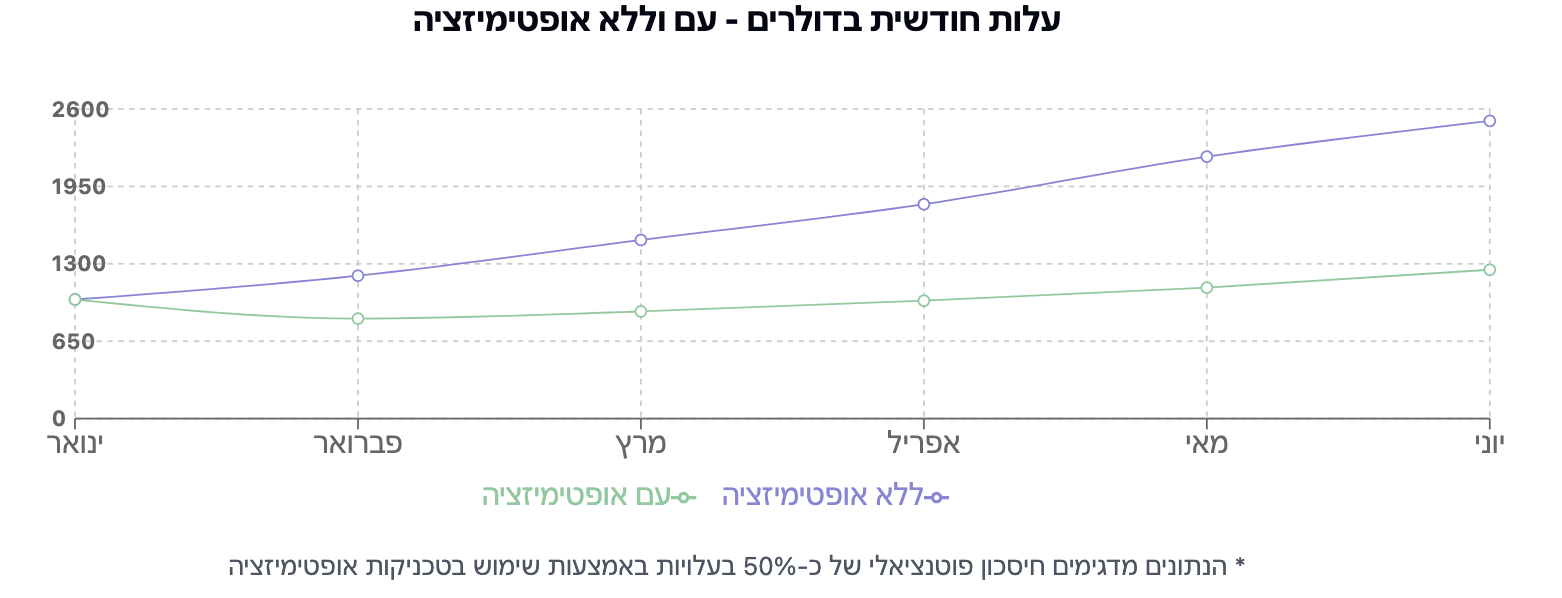
חסכון בעלויות עם אופטימיזציה
תמחור מודלי שפה לפי טוקנים משול לתשלום עבור מים לפי הליטרים - אתם משלמים לפי הצריכה שלכם. זה הפך לסטנדרט בתעשייה מסיבות טובות - הוא משקף את העלויות האמיתיות, מציע שקיפות והגינות, ומאפשר גמישות הן לספקים והן למשתמשים. הבנת המבנה הזה מאפשרת לכם לתכנן טוב יותר את השימוש ולחסוך כסף. זכרו שההבדלים בין שפות (במיוחד בין אנגלית לעברית) משפיעים משמעותית על העלויות. עם השתכללות הטכנולוגיה והגברת התחרות בשוק, סביר שנראה שינויים במודלים העסקיים ובאסטרטגיות התמחור - המפתח להצלחה הוא להישאר מעודכנים ולהתאים את האסטרטגיה שלכם בהתאם.
רוצים להבין איך ניתן לחסוך בעלויות מודלי שפה? טכנולוגיית RAG (Retrieval Augmented Generation) מאפשרת למודלים לגשת למאגרי מידע ולשלוף נתונים רלוונטיים לעסק שלכם בזמן אמת. כך תקבלו תשובות מדויקות המבוססות על מידע עדכני ואמיתי. למדו עוד על RAG ועל היתרונות שלו. מעוניינים להבין את ההבדל בין RAG ל-KAG? גלו את ההבדלים כאן.






