




אתמול (חמישי, 11.12.25) השיקה OpenAI את GPT-5.2 במהלך שנתפס על-ידי רבים יותר כתגובה המתבקשת ל-Gemini3 של גוגל, ופחות כמודל דגל חדש. המודל החדש אמנם מציג שיפורים חשובים, אך השאלה המרכזית שמרחפת מעליו היא האם הוא יצליח לתת פייט למתחרים מ-Google? האם עדכון כזה מסוגל באמת להחזיר את העליונות ש-OpenAI ביססה פה לאורך כמעט 3 שנים - אותה עליונות שגוגל סדקה (או שמא נאמר - ריסקה) לפני מספר שבועות. מה שבטוח - יש פה ניסיון ברור להדביק פער שנפתח מהר מדי, ושנדמה שהולך וגדל עם כל שדרוג והשקה מצד גוגל (ויש הרבה כאלה לאחרונה). המלחמה מתחממת ועולה הילוך! ב-OpenAI מבינים שזו תקופה מכרעת ובהחלט אפשר לזהות את הלחץ שמאחורי ההשקה. אבל בשורה התחתונה - האם זה מודל מספיק טוב כדי לעצור את שטף ביטולי המנויים בתשלום והמעבר לג'מיניי? במילה אחת... אולי. כן - זה מודל מצוין. אבל לא - לא בטוח שהוא התרופה לעלייתה של גוגל ומודל הדגל שלה - Gemini.
לפני 10 שנים ישבו חבורה של Dreamers והחליטו שהעתיד טמון בבינה מלאכותית. אט אט התחוור להם שפריצת הדרך תהיה במה שאנחנו היום מכנים "מודלי שפה גדולים" (LLMs). משם הדרך ל-GPT הייתה קצרה ולפני 3 שנים זה קרה. GPT 3.5 הושק לעולם בקול תרועה רמה, וההיסטוריה האנושית השתנתה לעד. המודל הזה הצית מהפכה שעד היום רק הלכה והתעצמה, ושסוללת מחדש את האופן בו בני אדם מתקשרים עם טכנולוגיה, עובדים עם טכנולוגיה ויוצרים עם טכנולוגיה.
ואכן, ב-3 השנים האחרונות היה נדמה ש-ChatGPT משאיר לכולם אבק. המוצר הצומח ביותר בהיסטוריה האנושית - יותר מספוטיפיי, יותר מטיקטוק, יותר מנטפליקס ויותר מאינסטגרם! מיליון משתמשים תוך 5 ימים. 100,000 משתמשים תוך חודשיים ונכון להיום כ-800 מיליון משתמשים שבועיים.
ואז הגיע נובמבר 2025...
בשבועות האחרונים שמעתי הרבה מאוד אנשים, קולגות ומשפיענים שמצהירים: "ביטלתי את המנוי שלי ל-ChatGPT ועברתי ל-Gemini". חייב לומר שאני לא שם לא הצליחו עדיין לשכנע אותי ש-ChatGPT הפסיק להיות כלי עבודה יעיל במיוחד - מבחינתי מדובר ב"סוס עבודה" בו אני עושה שימוש יומיומי, או ליתר דיוק - שימוש שוטף על בסיס כמעט שעתי. מצד שני, יש לי מנוי לכמעט כל LLM מוביל בשוק, החל מ-Claude ועד Gemini ובהחלט התפעמתי מההתקדמות האדירה של ג'מיניי בשבועות האחרונים.
למה מאמר על ChatGPT סוטה והופך למאמר על Gemini? כי ההשוואה מתבקשת. אחת התובנות המרכזיות שלי, בתור מי שחורש על כל אחת מהפלטפורמות, היא שאנחנו זכינו - ואנחנו זה הציבור הרחב. המשתמשים. זכינו לחיות בתקופה של שפע, שבה ענקיות טק ותאגידי AI גלובליים מתחרים על תשומת הלב שלנו (והארנק שלנו). ההבדלים כיום בין מודלי הדגל דיי מינוריים. כולם מאוד מאוד טובים, וגם היו מאוד מאוד טובים לפני חצי שנה ושנה.
בג'מיניי אמנם יש המון פיצ'רים חדשים ומאוד טובים - מודל תמונות מעולה (ננו בננה פרו), פיצ'רים מעולים לויזואליזציה של נתונים (מצגות, קנבס), מודל וידאו מעולה (Veo 3.1), וכולם יושבים באותו מקום. יש לו Deep Research מ-ט-ו-ר-ף (ואולי הכי טוב בשוק) ופלטפורמת בניית בוטים חביבה במיוחד (Gems). מצד שני - איכשהו בעבודה השוטפת, היומיומית, אני מוצא את עצמי חוזר לג'פטו הישן והטוב. הוא מגיב מהר יותר. זורם יותר. רץ חלק. לפעמים עומס וגודש של כוח חישוב מוביל לתוצאות טובות יותר, אבל גם לחוויית משתמש פחות טובה.
ב-Gemini אמנם אפשר להחליף בין מודל של חשיבה מעמיקה, למודל זריז יותר, אבל מודלי GPT של OpenAI מרגישים הרבה יותר "אייג'נטליים". כלומר - הם מגיבים יותר טוב לשינויים. החל מסדרת מודלי GPT-5, לא צריך להחליף ידנית מודל בבורר המודלים. ב-ChatGPT של סוף 2025, בואכה 2026, הכל עובד חלק יותר. כשהמודל מזהה משימה קלה - הוא עובד זריר, שולף מודל Instant ועונה מהר. כשהוא מזהה משימה מורכבת יותר - הוא חושב חזק ועמוק יותר. ומשהו בכל אותה חוויית שימוש, לי עושה שכל. פשוט "כיף" לעבוד שם. ושוב - זה לא שב-Gemini לא כיף לי, אבל יש דברים שקשה לשים עליהם את האצבע: אמינות, יציבות, זרימה וכן הלאה. את כל אלו ChatGPT שכללו לאורך 3 שנים של שליטה ללא עוררין בתעשייה. וזה עדיין שם!
בתחילת החודש הכריז אלטמן על "קוד אדום", נטישת פרויקטים צדדיים ומיקוד במשימות הליבה - ב-ChatGPT הקלאסי. וההשקה של GPT-5.2 מדברת בשפה אחרת - היא מבליטה פרודוקטיביות ויעילות: לא סתם שיפור בביצועים או מבחנים, אלא אאוטפוטים טובים יותר: סוכנים שעובדים טוב יותר לאורך זמן, יצירת קבצי אקסל מרובי גיליונות (אם תשאלו אותי - ChatGPT היא עדיין הפלטפורמה המובילה בכל מה שקשור לניתוח נתונים וקבצי אקסל ו-CSV). במילים אחרות, OpenAI מנסה להחזיר לעצמה יתרון תדמיתי וטכני לא דרך טריקים, אלא דרך חיזוק המוצר שמייצר לה את רוב הקשר היומיומי עם השוק.

אז אחרי ההקדמה הלא קצרה הזו, בואו נצלול פנימה אל תוך ביצועי המודל - מה חדש? מה השתנה? במה הוא טוב והאם יש פה בשורה אמיתית?
כמו בכל מודלי GPT-5 ומעלה, גם פה המודל "בוחר בשבילכם" כשהוא על מצב AUTO ומסוגל לדלג ולקפץ בין מצבי חשיבה שדורשים יותר כוח חישוב (מודלי הריזונינג שמקוטלגים כ-"Thinking"). או במילים אחרות - אתם מקריבים מהירות תמונות ביצועים טובים יותר (יותר כוח חישוב = פחות הזיות וטעויות, ויותר אמינות ודיוק).
כמובן, אפשר תמיד לבחור ידנית את מודל Instant המהיר, או מודל Thinking הכבד יותר, וגם בו אפשר להגדיר ידנית מצב חשיבה "רגיל" (Standard), או מצב חשיבה מעמיקה (Extendend Thinking). מצב זה מתאים במיוחד למשימות מורכבות או רב-שלביות. משימות כמו ניתוח קבצים ונתונים, ריבוי דאטה וכן הלאה.
מנויי פרו נהנים ממצב חשיבה עוצמתי יותר: GPT‑5.2 Pro. מודל עוצמתי אף יותר ממצב Thinking שמיועד למשימות מורכבות וארוכות באמת. אבל ל-99% מהמשתמשים אין באמת צורך בעוצמות חישוב כאלה.
כל מה שתיארתי פה, לא באמת ייחודי ל-GPT-5.2 והיה קיים בדורות הקודמים של סדרת GPT-5, ועדיין - הביצועים השתפרו וזה מורגש!
הנקודה השנייה היא אמינות. GPT-5.2 מציג ירידה משמעותית בהזיות וטעויות עובדתיות לעומת GPT-5.1 (כ-38% פחות טעויות עובדתיות).
לטענת החברה, GPT-5.2 מכוון לעבודה מקצועית יציבה ואמינה - פרויקטים שנמשכים לאורך הרבה שלבים, שזקוקים להקשר גדול ושמכילים הרבה פעולות. ביומיום כל זה מתורגם לפחות קריסות באמצע תהליכי עבודה, פחות חורים לוגיים בין שלבים, ויותר יכולת להחזיק מסמך, פרויקט או סט משימות לאורך זמן. פחות "צ'אט" ויותר דאטה אנליסט צמוד. מכשיר עוצמתי לניתוח נתונים, קבצים, לקריאה וכתיבה של תוכן. כלי שמצטיין ב"הסקה" (Reasoning) ואיתור דפוסים, מגמות והקשרים.
מבחן GDPval זהו מבחן שמנסה למדוד עד כמה מודל יודע לבצע משימות עבודת ידע “מוגדרות היטב” על פני 44 עיסוקים, כאשר במקום תשובה קצרה הוא נדרש לייצר תוצר עבודה אמיתי כמו מצגת, גיליון אלקטרוני או מסמך תפעולי, וההערכה נעשית על ידי שופטים אנושיים. המבחן הזה בודק כמה פעמים המודל מצליח לנצח אנשי מקצוע מומחים בתחומם, או להגיע לתיקו מולם. מודל GPT-5.2 Thinking הצליח לנצח או לסיים בתיקו מול אנשי מקצוע ב-70.9% מהמקרים, וגרסת GPT-5.2 Pro הגיעה ל-74.1%. מדהים! OpenAI גם טוענת שבמשימות האלה המודל ייצר תוצרים במהירות גבוהה פי 11 ובעלות שנמוכה מ-1% ביחס לעבודה אנושית.

מנצח מומחים אנושיים במבחני GDPval | קרדיט: OpenAI
מבחן פנימי לגיליונות בנקאות השקעות (Spreadsheet modeling), הוא מדד פנימי של OpenAI שמדמה עבודת אנליסט זוטר בבנקאות השקעות. לפי הנתונים, GPT-5.2 Thinking משפר את הציון הממוצע למשימה מ-59.1% ב-GPT-5.1 ל-68.4% ב-5.2 - עלייה של 9.3% בממוצע לכל משימה.
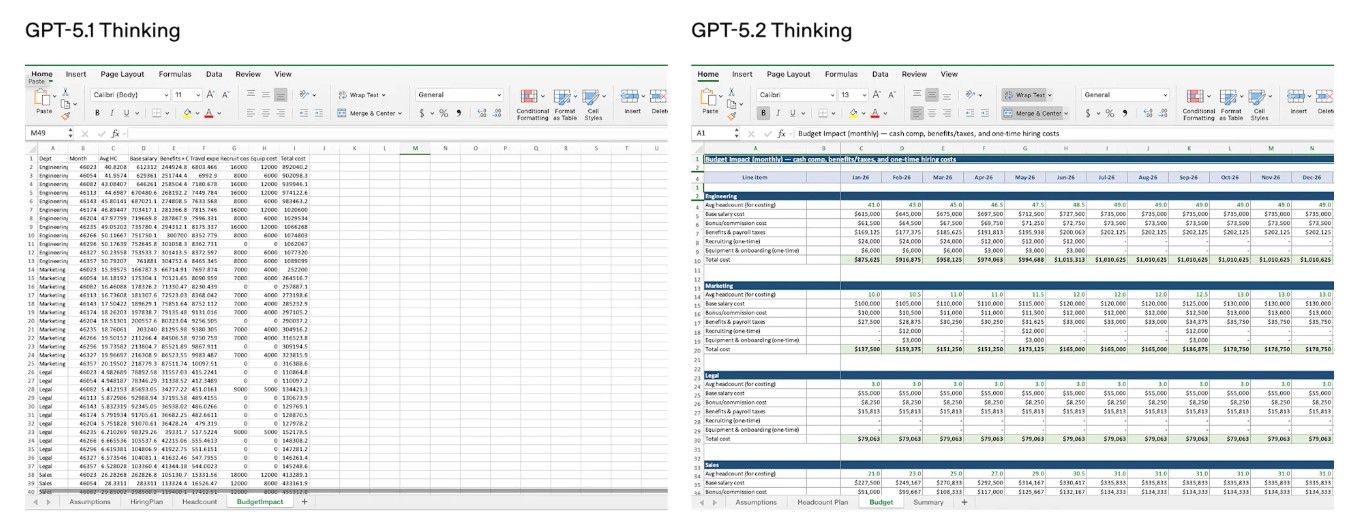
מצטיין בניתוח קבצים ונתונים | Credit: OpenAI
בתחום הקוד, OpenAI מדגישה שיפור בביצועים במדדים כמו SWE-Bench Pro ו-SWE-bench Verified, כאשר המספרים שמופיעים מצביעים על עלייה ביחס ל-GPT-5.1 Thinking. מעבר לתוצאות, הקו הכללי הוא שיפור בעבודה פרקטית: תיקון באגים, רפקטורינג לקוד בסיס גדול, יישום פיצ’רים ושילוח תיקונים מקצה לקצה עם פחות התערבות ידנית.
בתחומי מתמטיקה ומדע, ההכרזה מציינת תוצאות גבוהות במדדים כמו GPQA Diamond וגם AIME 2025, לצד שיפור במדדים מתקדמים יותר כמו FrontierMath.
מבחן GPQA Diamond (שאלות מדע “עמידות גוגל”) הוא בנצ’מרק של שאלות מדע ברמה גבוהה (פיזיקה, כימיה, ביולוגיה) שנועדו להיות קשות לחיפוש מהיר, ובגרסה שמוצגת כאן המודל פותר ללא שימוש בכלים. AIME 2025 (מתמטיקה תחרותית): זהו מבחן מתמטיקה תחרותי שמודד פתרון בעיות ממוקדות בלחץ דיוק, ללא כלים.
מי שלא חי את עולם הבנצ’מרקים יכול לתרגם את זה להבנה הפשוטה הבאה: OpenAI מנסה להראות שהמודל לא רק “מנסח יפה”, אלא גם מחזיק חזק יותר כשנדרשת חשיבה מרובת שלבים ודיוק כמותי. הוא מצטיין בביצועים במתמטיקה ומדע, גם כשהמודל שלפניו (GPT-5.1) עשה את זה טוב (הוא פשוט עושה את זה טוב יותר... חכם יותר).
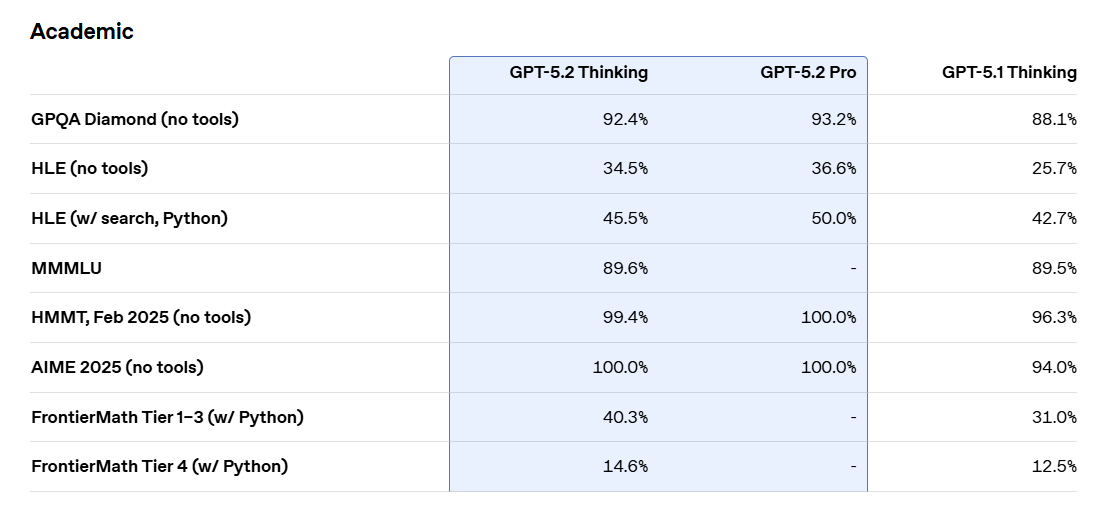
מצטיין במתמטיקה,מדעים וכתיבת קוד | Credit: OpenAI
אחד השיפורים המשמעותיים הוא ביכולות ההסקה המופשטת במדדי ARC-AGI, עם קפיצה משמעותית בתוצאות מול גרסאות קודמות. מבחנים אלו מנסים למדוד יכולת לפתור בעיות מופשטות שלא דומות לשאלות ידע רגילות, עם מיקוד במה שנחשב “חשיבה חדשה” ולא שחזור תבניות. או במילים אחרות - להתמודד עם מצבים שבהם המודל לא נתקל לפני כן בשלב האימון, ממש כמו שאדם אמיתי נדרש לפתור בעיות חדשות שעליהן לא "התאמן" או למד מראש. לפי OpenAI, ב-ARC-AGI-1 (Verified) GPT-5.2 Thinking מגיע ל-86.2% לעומת 72.8% ב-5.1, וב-ARC-AGI-2 (Verified) הוא קופץ ל-52.9% לעומת 17.6%. פה כבר מדובר בפערים גדולים.

מצטיין במבחני ARC AGI | קרדיט: OpenAI
המודל החדש כבר זמין ב-ChatGPT למנויים בתשלום בתשלום - מנויי פלוס (Plus), פרו (Pro), ביזנס (Business) ואנטרפרייז (Enterprise). חלק מהמשתמשים יקבלו אותו בהדרגה, כדי להבטיח פריסה יציבה.
ב-API, המודלים זמינים כבר עכשיו לכל המפתחים. יש גם פרמטר של “מאמץ חשיבה” (reasoning effort) ותמיכה ברמה נוספת בשם xhigh למשימות שבהן איכות חשובה יותר מזמן.
בתמחור, OpenAI מציגה מחיר של 1.75 דולר למיליון טוקנים בקלט ו-14 דולר למיליון טוקנים בפלט עבור gpt-5.2, לצד הנחה משמעותית על קלטים שמורים במטמון. לגרסת Pro המחירים גבוהים משמעותית, עם 21 דולר למיליון טוקנים בקלט ו-168 דולר למיליון טוקנים בפלט. יקר!
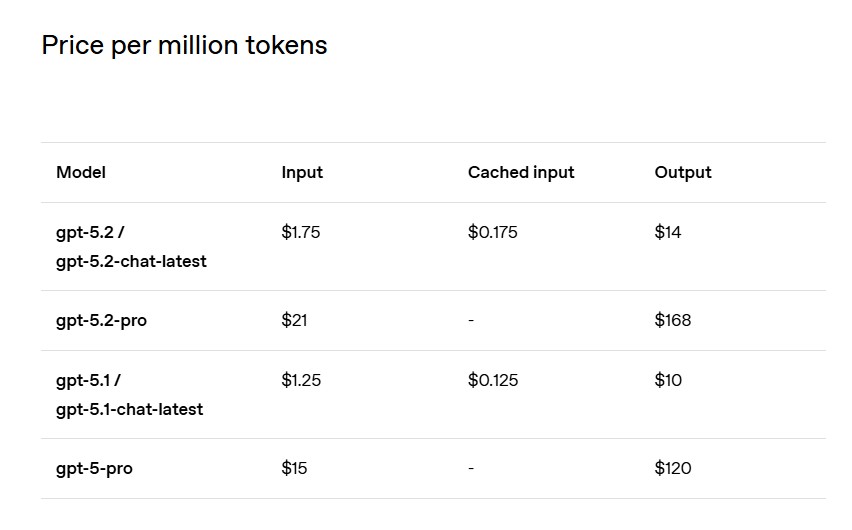
מחיר למיליון טוקנים ב-API
GPT-5.2 מגיע עם שיפור ניכר בכתיבה, קוד והיגיון, ועם דגש על הבנה עמוקה הודות לשמירה על הקשר לאורך זמן. זו לא "התשובה" ל-Gemini 3, אלא ניסיון להעלות זריז לכותרות מודל שיחזיר את GPT לשיח הציבורי. גוגל קיבלה המון תשומת לב בשבועות האחרונים וב-OpenAI נלחצו. זה לא ה-מודל שלה. זה פשוט 'עוד' מודל (מאוד מאוד טוב), שכנראה לא ישכנע אתכם לעבור מ-Gemini ל-ChatGPT, אבל אולי כן יהיה מספיק כדי להשאיר אתכם ב-ChatGPT ולמנוע מכם לנטוש את הספינה. ואם התחלנו באלגוריית הספינה - אז שלרגע אף אחד לא יחשוב שהיא טובעת - ראיתי הרבה שמספידים את OpenAI. אין לי ספק שהם יתאפסו על עצמם ויצמצמו את הפער. יש להם מוצר מעולה ועכשיו הם צריכים לקחת אותו צעד אחד למעלה.