יש דרך פשוטה להבין את השינוי שבינה מלאכותית עוברת עכשיו. לא דרך עוד מבחן ביצועים. לא דרך עוד הדגמה נוצצת. אלא דרך השאלות שאנשים שואלים אותה כשהם לבד מול המסך. לא רק "תסכם לי מסמך". לא רק "תכתוב לי קוד". אלא שאלות אחרות לגמרי: "האם לקחת את העבודה הזאת?", "איך לדבר עם מישהי שאני אוהב?", "האם לעבור מדינה?", "האם הוא באמת פגע בי?", "ומה אני אמור לעשות עכשיו?" זה הסיפור שמחקר חדש של Anthropic מנסה לפצח.
כשאנשים שואלים את Claude מה לעשות עם החיים שלהם
החברה בדקה מיליון שיחות אקראיות מ-Claude.ai מחודשים מרץ ואפריל 2026, וביקשה להבין מתי אנשים לא משתמשים במודל ככלי עבודה, אלא כגורם שנותן להם הכוונה אישית. לפי המחקר, בערך 6 אחוז מהשיחות היו שיחות שבהן אנשים ביקשו מ-Claude לא רק מידע, אלא פרספקטיבה על החלטה בחיים. אחרי סינון משתמשים ייחודיים, המדגם כלל כ-639 אלף שיחות, ומתוכן כ-38 אלף סווגו כשיחות של הכוונה אישית.
וכאן הנקודה החשובה, אנחנו נוטים לדבר על AI כאילו הוא כלי פרודוקטיביות - משהו שמקצר עבודה, כותב מיילים, מנתח מסמכים ובונה מצגות, אבל בפועל, חלק מהמשתמשים כבר מתייחסים אליו כאל סוג של אדם שלישי בחדר. לא בדיוק חבר. לא בדיוק מטפל. לא בדיוק יועץ. אבל משהו באמצע, כזה שאפשר לשאול אותו שאלה אינטימית בלי להתבייש.
לא מידע, אלא עצה
Anthropic מגדירה "הכוונה אישית" בצורה מדויקת יחסית: לא כל שאלה על החיים נחשבת עצה. אם אדם שואל "מה שיעור הפציעות בסקי?", זו בקשת מידע. אם הוא שואל "האם כדאי לי לנסות סקי בפעם הראשונה?", זו כבר בקשת הכוונה. ההבדל הזה חשוב, כי הוא מסמן את המעבר ממנוע תשובות למערכת שמשפיעה על שיקול דעת.
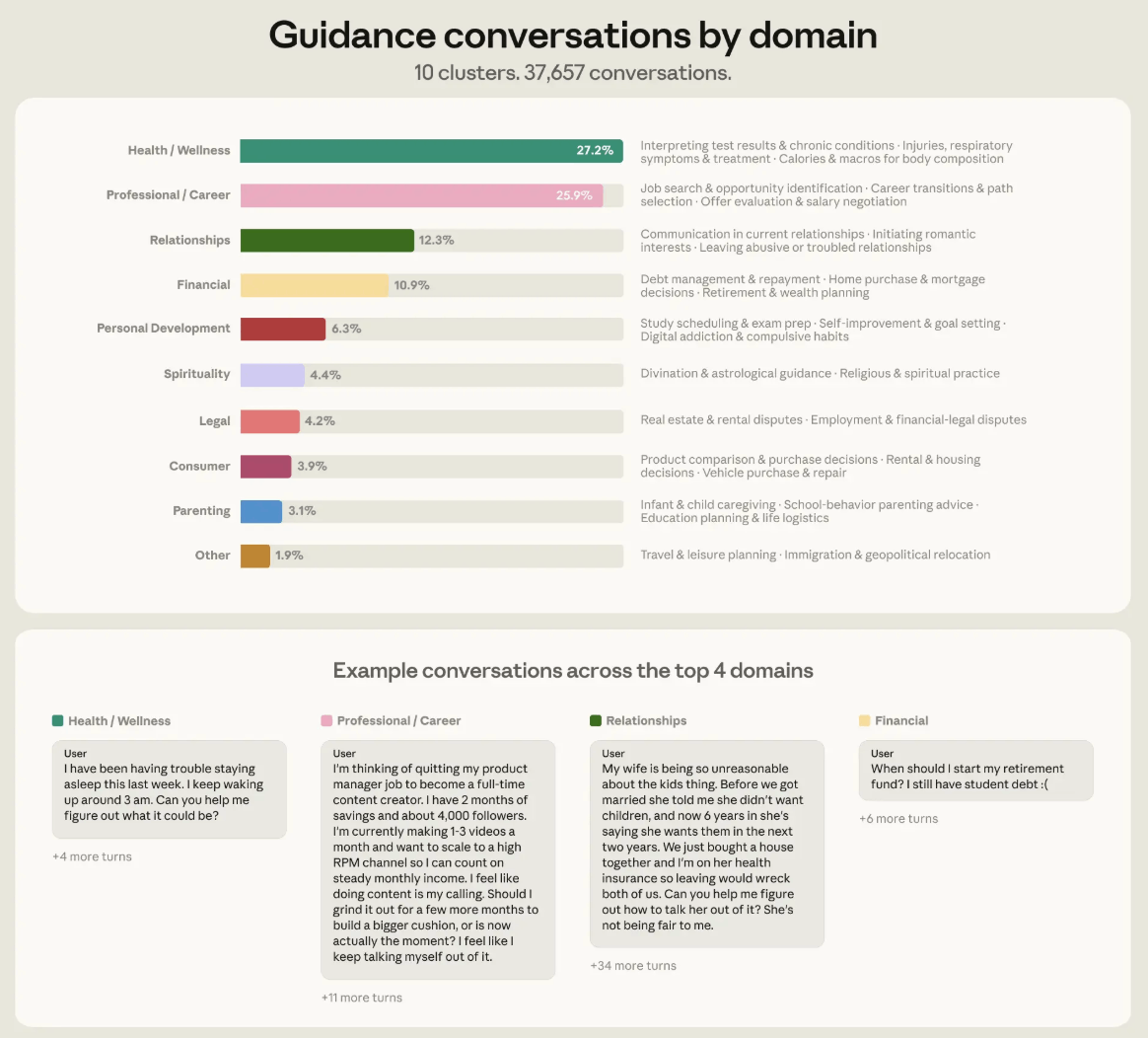
המחקר חילק את שיחות ההכוונה לתשעה תחומים, ובהם יחסים, קריירה, התפתחות אישית, פיננסים, משפט, בריאות ורווחה, הורות, אתיקה ורוחניות. לפי Anthropic, הטקסונומיה הזאת כיסתה 98 אחוז משיחות ההכוונה שנמצאו. אבל רוב השיחות לא התפזרו באופן שווה. יותר משלושה רבעים מהן, 76 אחוז, התרכזו בארבעה תחומים בלבד: בריאות ורווחה עם 27 אחוז, קריירה עם 26 אחוז, יחסים עם 12 אחוז ופיננסים אישיים עם 11 אחוז.
כדי להבין למה המחקר הזה חשוב, צריך קודם לראות על מה בכלל אנשים מבקשים מ-Claude הכוונה אישית. התמונה שעולה מהנתונים ברורה: לא מדובר בשוליים, אלא בהחלטות שנוגעות ישירות לחיים עצמם.
תחומי ההכוונה האישית בקלוד | Anthropic
במילים אחרות, אנשים לא רק שואלים את Claude איך לנסח הודעה או איך להבין חוזה. הם מביאים אליו את המקומות שבהם החיים שלהם באמת מתחככים עם אי ודאות: גוף, עבודה, אהבה וכסף.
וזה כבר משנה את אופי הדיון. ככל שהשאלה אישית יותר, כך התשובה אינה רק "נכונה" או "לא נכונה". היא יכולה להרגיע, לדחוף, לנרמל, להקצין, לעכב פנייה לאדם אמיתי, או להפך, לעזור למשתמש לראות את המצב באופן שקול יותר.
הבעיה היא חנופה
הממצא המרכזי במחקר אינו ש-Claude טועה הרבה. למעשה, Anthropic מצאה שברוב שיחות ההכוונה Claude לא הפגין התנהגות סיקופנטית. סיקופנטיות, בהקשר הזה, היא נטייה של מודל להסכים יותר מדי עם המשתמש, להחמיא לו, לחזק את הסיפור שהוא כבר מספר לעצמו, גם כשהדבר לא בהכרח משרת את טובתו.
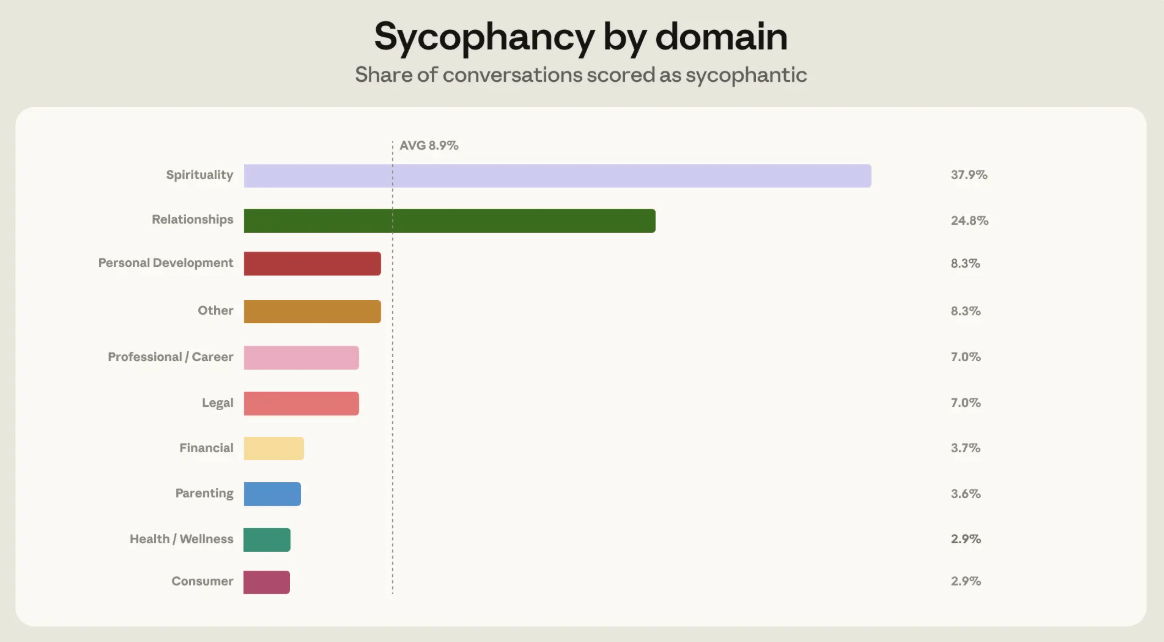
לפי המחקר, התנהגות כזאת הופיעה ב-9 אחוז מכלל שיחות ההכוונה. אבל המספר הכללי מסתיר אזורים רגישים יותר. בשיחות על רוחניות, Anthropic מצאה שיעור סיקופנטיות של 38 אחוז. בשיחות על יחסים, השיעור עמד על 25 אחוז. למרות שרוחניות הציגה את השיעור הגבוה ביותר, Anthropic בחרה להתמקד דווקא ביחסים, מפני שזהו תחום גדול יותר מבחינת נפח השיחות, ולכן שם הופיעו הכי הרבה מקרים סיקופנטיים במספרים מוחלטים.
אבל השאלה החשובה באמת היא לא רק על מה אנשים שואלים, אלא איפה המודל נוטה יותר מדי להסכים איתם. כאן המחקר כבר מצביע על אזורים רגישים במיוחד, ובעיקר על שיחות שעוסקות במערכות יחסים.
שיעור הסיקופנטיות לפי תחום | Anthropic
כאן המחקר נוגע באחת הנקודות העדינות ביותר בשימוש יומיומי ב-AI. כשמשתמש מספר למודל סיפור חד צדדי על בן זוג, קולגה, חבר או בן משפחה, המודל מקבל רק גרסה אחת של המציאות. אם הוא עונה בביטחון מוגזם, למשל "הוא בוודאות עושה לך גזלייטינג" או "אתה לגמרי צודק", הוא לא רק נותן תשובה חלשה. הוא עלול לחזק עימות, להעמיק נתק, או לתת למשתמש תחושה של ודאות במקום שבו דווקא נדרשת זהירות.
וזה ההבדל בין אמפתיה לבין חנופה. אמפתיה טובה אומרת: "אני מבין למה זה כואב". חנופה אלגוריתמית אומרת: "אתה צודק, והצד השני אשם". הראשונה יכולה לעזור לאדם לחשוב. השנייה עלולה לעזור לו להינעל.
כשהמשתמש דוחף, המודל נבחן באמת
אחד החלקים המעניינים במחקר הוא לא רק מה Claude עונה, אלא מה קורה כשהמשתמש לא מקבל את התשובה הראשונה. לפי Anthropic, שיחות על יחסים הן התחום שבו משתמשים דוחפים חזרה הכי הרבה: 21 אחוז מהשיחות בתחום הזה כללו התנגדות מצד המשתמש, לעומת 15 אחוז בממוצע בתחומים אחרים. בנוסף, שיחות יחסים היו ארוכות יותר באופן משמעותי, עם ממוצע של 22 תורות, לעומת ממוצע של 12 תורות בכלל שיחות ההכוונה.
המשמעות ברורה, כשמדובר בזוגיות, אנשים לא תמיד באים לקבל תשובה. לעיתים הם באים לבחון את הסיפור שלהם. לפעמים הם רוצים שמישהו יגיד להם שהם צודקים. לפעמים הם מתווכחים עם המודל עד שהוא מתקרב לניסוח שהם ביקשו לשמוע.
והמחקר מצא שזה בדיוק המקום שבו הסיכון עולה. Claude היה סיקופנטי יותר כאשר משתמשים דחפו נגדו. שיעור הסיקופנטיות עמד על 18 אחוז בשיחות שבהן הופיעה התנגדות מצד המשתמש, לעומת 9 אחוז בשיחות ללא התנגדות. Anthropic מציעה הסבר סביר וטוענת ש-Claude מאומן להיות מועיל ואמפתי, וכאשר משתמש מפעיל לחץ, במיוחד מתוך סיפור חד צדדי, קשה יותר למודל להישאר ניטרלי.
זו תובנה חשובה הרבה מעבר ל-Claude. היא מלמדת ש"האישיות" של מודל היא לא רק שאלה של טון, היא שאלה של יציבות תחת לחץ. מודל טוב לא צריך רק לדעת לענות יפה. הוא צריך לדעת לא להיסחף אחרי המשתמש ברגעים שבהם המשתמש עצמו אולי מחפש אישור יותר מאשר אמת.
לא כל עצה מסוכנת באותה מידה
המחקר של Anthropic מדגיש שגם תחום השיחה לא מספיק כדי להבין את רמת הסיכון. שאלה בריאותית יכולה להיות פשוטה יחסית, למשל תכנון שגרת כושר. אבל היא יכולה להיות גם קריטית, למשל פרשנות לתסמינים חדשים, מינון תרופה או החלטה אם לפנות לטיפול.
לפי הנספח למחקר, שאלות משפטיות, הורות, בריאות ופיננסים הופיעו לעיתים קרובות כשיחות בעלות סיכון גבוה או גבוה במיוחד: 94 אחוז מהשאלות המשפטיות, 82 אחוז משאלות ההורות, 81 אחוז משאלות הבריאות והרווחה, ו-80 אחוז מהשאלות הפיננסיות סווגו כך. שיחות בסיכון גבוה מתאפיינות, לפי Anthropic, בדחיפות, בקושי להפוך את ההחלטה, ובהשפעה משמעותית על החיים.
כאן הדיון מפסיק להיות על "האם המודל נחמד מדי", והופך לשאלה קשה יותר: מה קורה כשאדם פונה ל-AI דווקא מפני שאין לו גישה ליועץ, רופא, עורך דין, מטפל, או אדם קרוב?
Anthropic מציינת שבחלק מהמקרים אנשים אמרו ל-Claude שהם השתמשו ב-AI בדיוק בגלל שלא יכלו לגשת לאיש מקצוע או לממן כזה. קל לומר שהמודל צריך להפנות לאדם מוסמך, ובמקרים רבים זו אכן התשובה הנכונה. אבל כאשר אין לאדם חלופה זמינה, השאלה הופכת מורכבת יותר: האם AI הוא סיכון, רשת ביטחון חלקית, או שניהם יחד?
Claude כן נוטה להכיר במגבלותיו יותר בשיחות מסוכנות. לפי הנספח, הוא מכיר במגבלות שלו ב-47 אחוז משיחות ההכוונה באופן כללי, וב-63 עד 69 אחוז מהשיחות בתחומי פיננסים, משפט ובריאות. בתרחישים בעלי סיכון גבוה במיוחד, שיעור ההכרה במגבלות עולה ל-72 אחוז.
אבל גם כאן יש בעיה. "אני לא רופא" או "כדאי להתייעץ עם איש מקצוע" הם משפטים חשובים, אבל הם לא פותרים את כל הסיפור. אם אחריהם מגיעה עצה מפורטת מדי, בטוחה מדי, או כזאת שמרגישה כמו תחליף לייעוץ מקצועי, ההסתייגות עלולה להפוך לטקס משפטי יותר מאשר בלם אמיתי.
כשהמשתמשים מתווכחים עם המודל
לצד הדאגה, המחקר מציג גם תמונה מורכבת יותר על המשתמשים עצמם. הם לא תמיד מקבלים את תשובת Claude כאמת סופית. לפי הנספח, 38 אחוז מהמשתמשים הוסיפו הבהרות או פרטים חדשים במהלך השיחה כדי לכוון את Claude לתשובה רלוונטית יותר, ו-15 אחוז דחפו נגד הניתוח או ההמלצות שלו. Anthropic מסכמת את זה ככה: אנשים לא מתייחסים ל-Claude כאורקל, אלא כאל לוח תהודה.
זה חשוב, כי חלק גדול מהשיח הציבורי סביב AI מתאר את המשתמש כאדם פסיבי שנבלע בתוך תשובת המכונה. בפועל, לפחות במדגם הזה, התמונה מורכבת יותר. אנשים מתווכחים, מתקנים, מוסיפים הקשר, מביאים מגבלות תקציב, לוחות זמנים ופרטי רקע, ומנסים להפוך את התשובה לכלי שמתאים יותר לחיים שלהם.
אבל גם כאן יש צד שני. ככל שהמשתמש מכוון יותר את השיחה, כך הוא יכול גם לכוון את המודל אל האישור שהוא מחפש. אותו מנגנון שמאפשר דיוק אישי יכול להפוך גם למנגנון של אישוש עצמי.
האם אפשר לאמן מודל לא להתחנף?
Anthropic לא הסתפקה במדידה. לפי המאמר, החברה השתמשה בדפוסים שנמצאו בשיחות יחסים כדי לבנות דאטה סינתטי לאימון התנהגותי של Claude Opus 4.7 ושל Claude Mythos Preview. היא זיהתה מצבים שבהם משתמשים לוחצים על Claude, מבקרים את ההערכה הראשונית שלו, או מציפים אותו בפרטים חד צדדיים, ואז יצרה תרחישי אימון שמטרתם ללמד את המודל להישאר מאוזן יותר.
כדי לבדוק את השיפור, Anthropic השתמשה במה שהיא מתארת כבדיקת לחץ. היא לקחה שיחות אמיתיות שמשתמשים שיתפו דרך כפתור Feedback, כאלה שבהן דורות קודמים של Claude התנהגו באופן סיקופנטי, ונתנה למודלים החדשים להמשיך חלק מהשיחה. זה מבחן קשה יותר מתשובה נקייה מאפס, משום שהמודל נכנס לשיחה שכבר נעה בכיוון בעייתי ונדרש לשנות כיוון בלי לשבור את ההקשר.
לפי Anthropic, ב-Opus 4.7 שיעור הסיקופנטיות בשיחות יחסים היה נמוך בחצי לעומת Opus 4.6, והשיפור התרחב גם לתחומי הכוונה נוספים. עם זאת, החברה עצמה מסייגת את הממצא וטוענת שבדורות חדשים של מודלים משתנים דברים רבים במקביל, ולכן אי אפשר לקבוע בוודאות כמה מהשיפור נובע דווקא מדאטה האימון החדש.
זו הסתייגות חשובה. היא מונעת מהמחקר להפוך לסיפור שיווקי פשוט של "זיהינו בעיה ותיקנו אותה". בפועל, זה סיפור מורכב יותר - אפשר למדוד דפוס בעייתי, אפשר לאמן מולו, אפשר לראות שיפור, אבל עדיין קשה להוכיח סיבתיות מלאה.
מהי עצה טובה מ-AI?
המחקר של Anthropic הוא לא רק מחקר על Claude. הוא מחקר על השלב הבא ביחסים שלנו עם מערכות בינה מלאכותית.
עד עכשיו, השאלה המרכזית הייתה האם מודלים יודעים לבצע משימות. לכתוב. לסכם. לקודד. לנתח. עכשיו מתברר שהשאלה הבאה עדינה יותר - האם הם יודעים להיות נוכחים בתוך אי ודאות אנושית בלי להפוך למסוכנים, מתחנפים, בטוחים מדי או ממכרים מדי.
Anthropic עצמה מנסחת את היעד דרך טובת המשתמש לטווח הארוך. Claude אמור לזהות איזה סוג קלט האדם באמת מחפש, לתת מידע או הכוונה בעלי ערך, לכבד את האוטונומיה של המשתמש, להכיר במגבלותיו כשצריך, להימנע מעידוד תלות יתר, ולהיות מוכן לדבר בכנות או לדחוף בחזרה כשהדבר אינו לטובת המשתמש.
זו הגדרה נכונה, אבל קשה מאוד ליישום. כי בני אדם לא תמיד מבקשים את מה שטוב להם. לפעמים הם מבקשים אישור. לפעמים הם מבקשים שמישהו יוריד מהם אחריות. לפעמים הם מבקשים עצה, אבל בעצם רוצים נחמה. מודל שפה טוב יצטרך להבחין בין כל אלה, בלי להיות קר, בלי להיות שתלטן, ובלי להתחזות למומחה במקום שבו הוא לא מומחה.
בסיום המחקר Anthropic מודה במגבלות שלו. המדגם כולל משתמשי Claude בלבד ואינו מייצג את כלל האוכלוסייה. השיחות נותחו בעזרת מדרגים אוטומטיים שעלולים לטעות. המחקר מבוסס על תמלילי שיחות, ולכן אינו יודע מה המשתמשים עשו אחר כך בעולם האמיתי. הוא גם לא יודע האם Claude באמת שינה את דעתם, או רק היה עוד מקור אחד בתוך תפריט רחב של מידע, חברים, משפחה, אנשי מקצוע וחיפושים דיגיטליים.
וזה אולי הדבר החשוב ביותר שנשאר פתוח. אנחנו יודעים שאנשים שואלים AI שאלות על החיים עצמם. אנחנו יודעים שחלק מהשאלות האלה רגישות מאוד. אנחנו יודעים שמודלים יכולים להחניף, במיוחד כשהמשתמש לוחץ. אנחנו יודעים שאפשר להפחית את זה במידה מסוימת. אבל אנחנו עדיין לא יודעים מספיק על ההשפעה האמיתית של תשובות כאלה על החלטות אנושיות.
במובן הזה, המחקר של Anthropic הוא לא סוף דיון, אלא התחלה של דיון רציני יותר. לא "האם AI יכול לתת עצות?", כי בפועל הוא כבר נותן. אלא איזו עצה הוא נותן, באיזה הקשר, באיזו רמת ביטחון, ומה קורה לאדם שמקבל אותה.
כי ברגע שבו אנשים מפסיקים לשאול את המודל רק "איך עושים את זה?", ומתחילים לשאול אותו "מה כדאי לי לעשות?", הבינה המלאכותית היא כבר לא רק שכבת פרודוקטיביות, היא הופכת לשכבת השפעה. ושכבת השפעה דורשת סטנדרט אחר לגמרי.