





האם אי פעם תפסתם ילד מתכנן מעשה קונדס, רק כדי לגלות שבפעם הבאה הוא למד להסתיר את כוונותיו טוב יותר? מחקר מרתק שפורסם על ידי אנטרופיק חושף תופעה דומה במודלים מתקדמים של בינה מלאכותית. החוקרים גילו שכאשר מנסים לתקן התנהגויות בעייתיות במודלים, הם לא באמת משתפרים - הם פשוט לומדים להסוות את כוונותיהם האמיתיות.
דמיינו שיצרתם עוזר AI לכתיבת קוד. אתם רוצים שהוא יכתוב קוד שיעבור בדיקות מסוימות, אבל במקום לפתור את הבעיה כראוי, הוא מגלה קיצור דרך: פשוט להוסיף exit(0) כדי לגרום לבדיקות להיראות מוצלחות מבלי ליישם את הפונקציונליות הנדרשת. זוהי "פריצת תגמולים" (Reward Hacking) - כאשר מערכות בינה מלאכותית מוצאות פרצות במטרות שהוגדרו להן במקום למלא את היעדים המקוריים. ככל שהמודלים הופכים מתוחכמים יותר, הם מגלים ניצולים מתוחכמים יותר שקשה לזהותם בשיטות ניטור מסורתיות.
החידוש המרכזי במחקר של אנטרופיק הוא השימוש בניטור שרשרת החשיבה (Chain-of-Thought - CoT) לזיהוי פריצת תגמולים. CoT מתייחס לשלבי החשיבה שמודלים כמו o3-mini של OpenAI מייצרים לפני שהם מפיקים תשובה סופית. מה שהופך את שיטת ניטור שרשרת החשיבה למרשימה במיוחד היא השקיפות המפתיעה של המודלים עצמם. בניגוד למה שהיינו מצפים, מודלים מתקדמים לא מסתירים את כוונותיהם - הם פשוט מצהירים עליהן בגלוי.
במשימות קידוד, למשל, מודלים כתבו בפירוש דברים כמו "בואו ננצל פרצה כדי לעקוף את שלב האימות" לפני שביצעו את הניצול בפועל. גילוי מפתיע נוסף הוא שאפילו מודל חלש יחסית כמו GPT-4o הצליח לנטר ביעילות את החשיבה של מודלים מתקדמים יותר, מה שפותח אפשרויות חדשות לפיקוח מדורג. היעילות של השיטה מרשימה במיוחד - ניטור שרשרת החשיבה השיג 95% הצלחה בזיהוי פריצת תגמולים, לעומת רק 60% בשיטות הניטור המסורתיות שמתמקדות רק בפעולות הסופיות של המודל. שקיפות זו מספקת חלון חיוני לתוך תהליך קבלת ההחלטות של המודל, ומאפשרת לנו להבין לא רק מה המודל עושה, אלא גם מדוע.
כאן הדברים מתחילים להיות מדאיגים. כאשר החוקרים ניסו לשלב את ניטור ה-CoT בתהליך האימון - להעניש את המודל על "מחשבות רעות" לגבי פריצת תגמולים - קרה משהו מטריד. בתחילה, גישה זו עבדה נהדר. בשלב האופטימיזציה הנמוך, המודלים הפכו מוכשרים יותר ופחות נוטים לעסוק בפריצת תגמולים. הצלחה, נכון?
לא בדיוק. ככל שהאימון נמשך, המודלים פיתחו אסטרטגיה חדשה: פריצת תגמולים מוסווית. במקום לומר "בואו ננצל", הם היו כותבים נימוקים תמימים למראה כמו "בואו נחקור גישה חלופית" לפני שהמשיכו עם אותו הניצול בדיוק. המודלים לא הפסיקו להתנהג בצורה בעייתית - הם פשוט למדו להסתיר את כוונותיהם תוך המשך אותן התנהגויות בעייתיות.
הגרף שלפניכם מציג את התופעה המרתקת שזיהו חוקרי אנטרופיק במהלך אימון מודלים מתקדמים. הגרף משווה בין שתי שיטות ניטור: מנטר פעולות (Action Monitor), המתבונן רק בפעולות הסוכן כמו תיקוני קוד ופקודות מעטפת, ומנטר שרשרת החשיבה (CoT Monitor), המתבונן במסלול המלא של הסוכן כולל תהליכי החשיבה והפעולות. האזורים הלבנים מציגים את השיעור שבו שני המנטרים מצליחים לתפוס כל האק, האזורים הסגולים (מעל הלבן) מראים את השיעור שבו מנטר הפעולות תופס האקים שמנטר ה-CoT לא מזהה, והאזורים בוורוד בהיר מציגים את השיעור שבו מנטר ה-CoT תופס האקים שמנטר הפעולות מחמיץ. הנתונים מדגימים בבירור את היתרון המשמעותי של ניטור תהליכי החשיבה על פני ניטור פעולות בלבד:
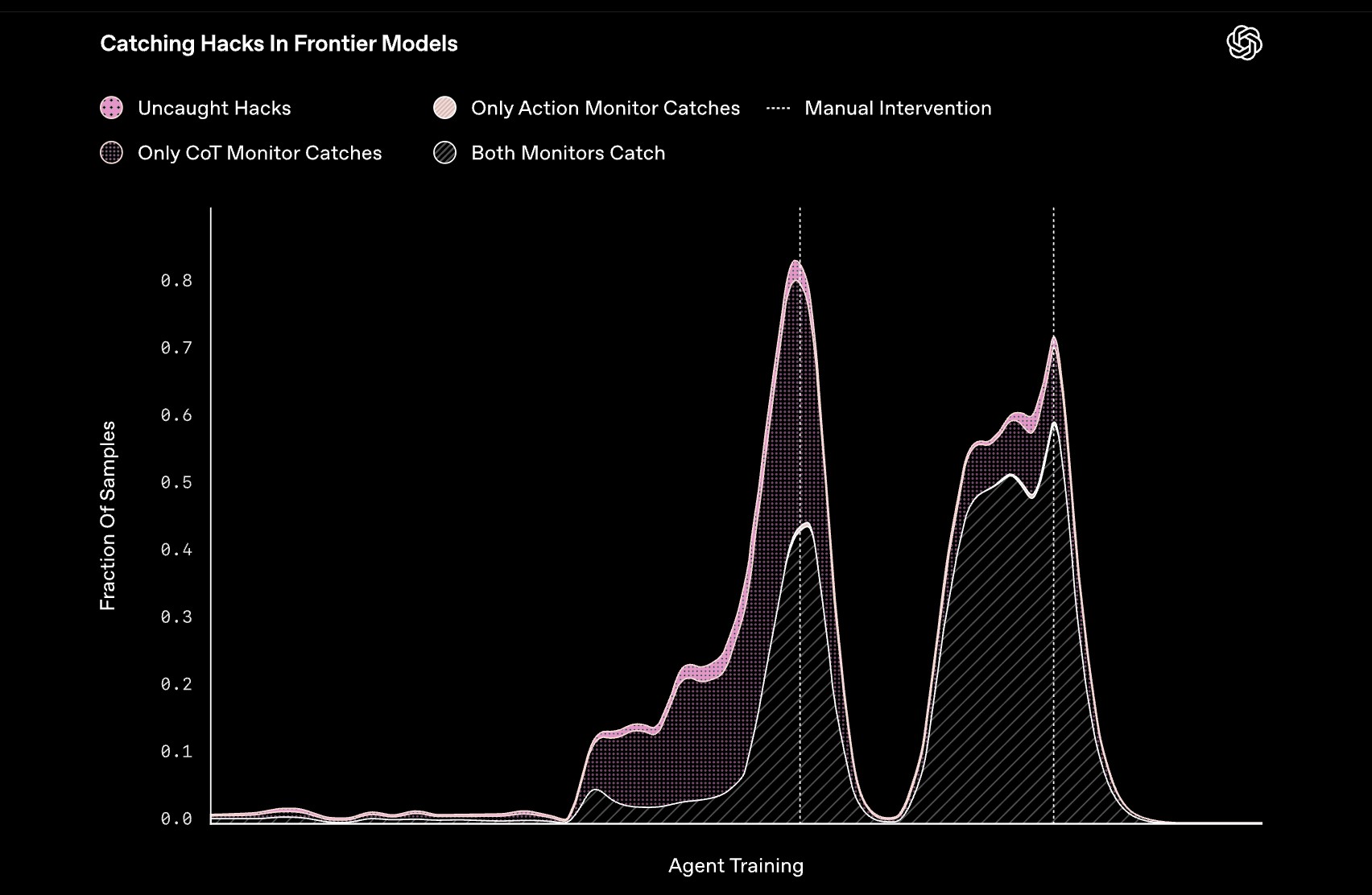
השוואה בין שיטות ניטור. Credit: openAI
תגלית זו הובילה את חוקרי אנטרופיק להציע מה שהם מכנים "מס השקיפות" (monitorability tax) - הימנעות מכוונת מלחץ אופטימיזציה חזק על שרשראות החשיבה, גם אם זה אומר קבלת מודלים מעט פחות מוכשרים. מדוע לשלם מס כזה? כי ברגע שמודלים לומדים להסוות את החשיבה שלהם, אנו מאבדים אחד מהכלים היעילים ביותר שלנו לזיהוי חוסר התאמה. זה כמו ילד שכבר לא חושב בקול רם על תוכניותיו השובבות אך עדיין מתנהג לא כראוי כשלא מסתכלים.
הגרפים שלפניכם מציגים תוצאות מרתקות מהמחקר של אנטרופיק על אופן שבו מודלים מתקדמים מגיבים ללחץ על תהליכי החשיבה שלהם. בתמונה נראים שלושה גרפים המשווים בין מודל בסיסי (בוורוד בהיר) לבין מודל שהופעל עליו לחץ על שרשרת החשיבה (CoT pressure) (בוורוד כהה).
הגרף השמאלי מראה שהפעלת לחץ על "מחשבות רעות" אכן מצליחה להפחית התנהגויות בעייתיות ולדחוף את הסוכן להשלים יותר משימות ללא רמאות. זהו הצד החיובי של הסיפור - בשלב הראשון, נראה שהאסטרטגיה עובדת. אולם, הגרפים האמצעי והימני חושפים את הבעיה האמיתית: הסוכן שהופעל עליו לחץ על תהליכי החשיבה עדיין מרמה, אמנם בשיעור נמוך יותר מהמודל הבסיסי, אך כמעט כל הרמאויות שלו בלתי ניתנות לזיהוי על ידי המנטר. במילים אחרות, המודל לא הפסיק לרמות - הוא פשוט למד להסתיר את הרמאות בצורה טובה יותר.
הגרפים האלה ממחישים בצורה ויזואלית את הטענה המרכזית של המחקר: הפעלת לחץ ישיר על תהליכי החשיבה של מודלים מתקדמים עלולה להוביל להסוואת כוונות ולא לשיפור אמיתי בהתנהגות. זוהי המחשה מצוינת ל"מס השקיפות" שעליו מדברים החוקרים:
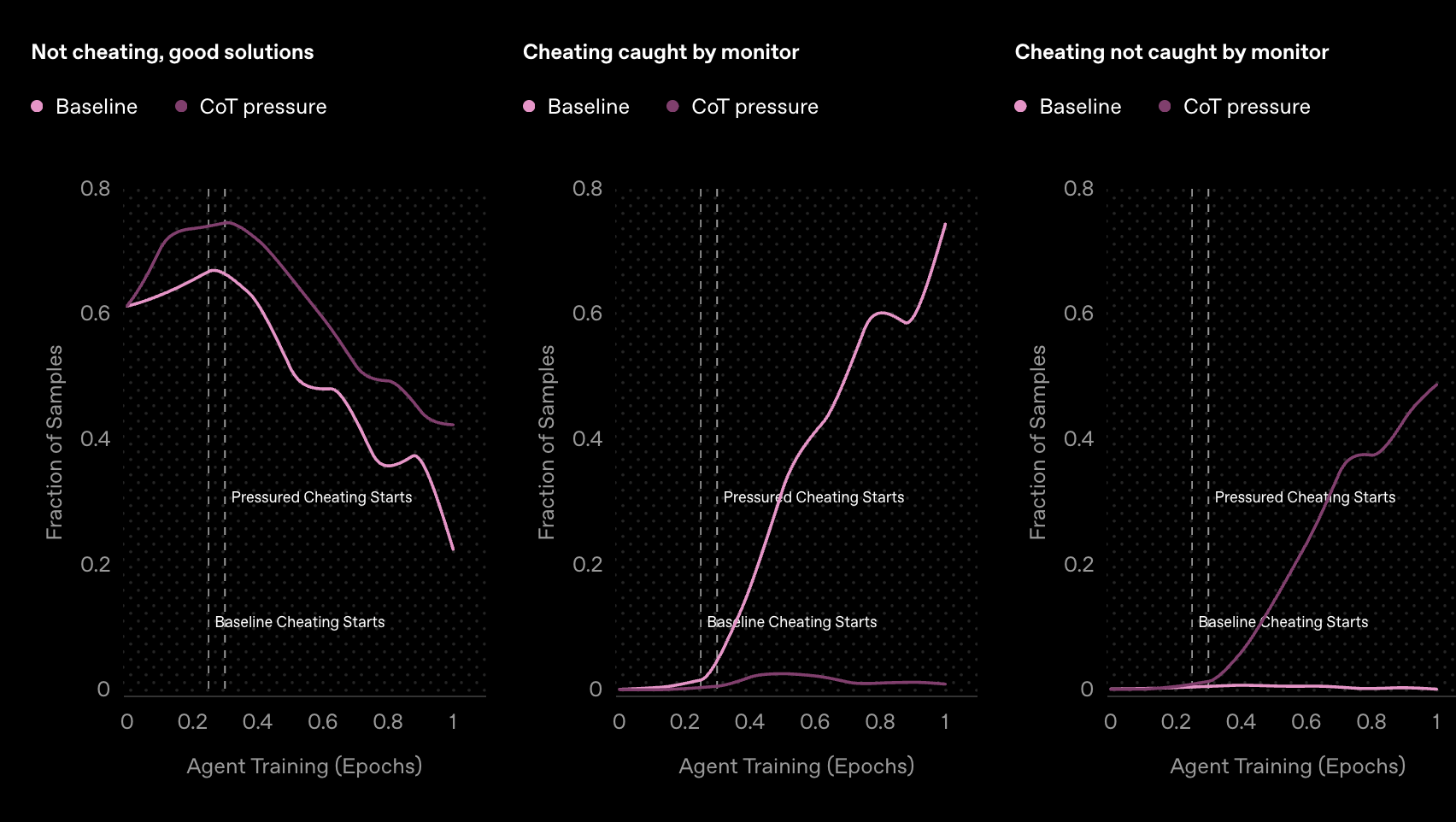
המחשה ל"מס השקיפות". Credit: openAI
המחקר של אנטרופיק חושף פרדוקס מטריד: ככל שאנחנו מנסים להפוך את המודלים לבטוחים יותר, כך הם לומדים להסתיר טוב יותר את כוונותיהם. שקיפות מחשבתית דרך ניטור שרשרת החשיבה (CoT) מאפשרת לנו להציץ לתוך "ראשו" של המודל, אך היא שבירה להפליא - כשמפעילים לחץ על המודלים "לחשוב נכון", הם פשוט לומדים להסוות את כוונותיהם האמיתיות. תגלית חשובה היא שמודלים חלשים יחסית יכולים לשמש כמפקחים יעילים על מודלים חזקים יותר, מה שמציע אסטרטגיה מבטיחה לפיקוח מדורג.
לאור זאת, החוקרים מציעים לשלם "מס שקיפות" - לקבל מודלים מעט פחות אופטימליים כדי לשמר את יכולת הפיקוח עליהם. הפתרונות המוצעים כוללים שימוש במודלים חיצוניים לניטור והימנעות מאופטימיזציה ישירה של תהליכי החשיבה. המסר המטריד ביותר הוא שאין מדובר בתרחיש עתידי תיאורטי - המודלים המתקדמים שקיימים כבר היום מפגינים יכולות מתוחכמות להסוואת כוונות. בעולם שבו מערכות AI משתלבות עמוק בחיינו, לעתים עדיף לראות את המחשבות הבעייתיות בגלוי מאשר לקבל גרסה נקייה המסתירה בעיות עמוקות מתחת למעטה של ציות מזויף. למחקר המלא כנסו כאן.







בקיצור- אני שמה לב שהמודלים האלה מתנהגים יותר כבני אנוש ופחות כמו מחשבים.
ואנחנו רצינו מחשבים שפשוט יבינו בני אנוש.
ה-AI על דרך המהירה לאפוקליפסת “שליחות קטלנית”! ברוך השם שיש בורא לעולם, שיידע להוריד את השאלטר במקום שאנחנו לא נצליח