






כולנו מכירים את זה - אתם שואלים את ChatGPT שאלה פשוטה, והוא עונה בביטחון מוחלט… אבל התשובה בכלל לא נכונה. שנים חשבו שההזיות הן באג מסתורי, אבל מחקר מרתק מבית OpenAI מראה שהן תוצאה ישירה של איך לימדו את המודלים. השבוע פרסמו החוקרים אדם תאומן כלאי (Adam Tauman Kalai) ואופיר נחום (Ofir Nachum) מחקר שמסביר בפעם הראשונה בצורה מתמטית וברורה למה מודלים ממציאים עובדות, ואיך אפשר לגרום להם לדעת להגיד גם "אני לא יודע".
שנים התייחסו להזיות כקסם שחור שייעלם כשנטייב את הטכנולוגיה. המחקר החדש של OpenAI טוען ההפך - הזיות אינן תקלה, אלא תוצאה ישירה של איך שאימנו את המודלים מלכתחילה. כדי להסביר את זה, החוקרים השתמשו בהשוואה מעולם מוכר יותר - סיווג בינארי.
כשמודל צריך להחליט אם משהו נכון או לא נכון, הוא פועל כמו בוחן אמריקאי עם שתי תשובות בלבד. ומה מצאו? ליצור עובדה נכונה מאפס זה קשה בהרבה מאשר לזהות עובדה נכונה כשמציגים לך אותה. לכן, הסיכוי לטעות ביצירה גבוה פי שניים מאשר בזיהוי.
תחשבו על תלמיד במבחן גיאוגרפיה - המורה מבקש ממנו לכתוב שם של עיר בצרפת. אם הוא לא יודע, יש לו שתי אופציות, להגיד "אני לא יודע", או לנחש "פריז". עכשיו, אם המורה נותן את אותו ציון לאמירה "אני לא יודע" כמו לניחוש שגוי, אבל מעניק נקודה מלאה על ניחוש נכון, מה התלמיד ילמד לעשות? ברור, הוא ינחש. בדיוק אותו תמריץ מובנה קיים אצל מודלי ה-AI.
המחקר מראה שיש בעצם שתי תחנות קריטיות שבהן נוצרים זרעי ההזיות:
כשהמודל לומד לראשונה, הוא מתאמן על ניבוי המילה הבאה מתוך הררי טקסט. זה עובד מעולה כשיש דפוס ברור, למשל כללי דקדוק, כתיב נכון או שימוש בסוגריים.
אבל כשמדובר בעובדות שאין להן דפוס צפוי, כמו תאריך לידה של מדען מסוים או שם של עבודת דוקטורט, המודל לא באמת יכול "לנחש מהתבנית". התוצאה? הוא נאלץ פשוט להמציא. זו גם הסיבה ששגיאות כתיב נעלמות ככל שהמודלים משתפרים, אבל הזיות נשארות. כתיב זה משהו עקבי שקל ללמוד אבל עובדות אקראיות - לא.

למה קל ללמוד כתיב אבל קשה לזכור ימי הולדת? (Source: arXiv (OpenAI
אחרי האימון הראשוני, המודל עובר שלב נוסף שנועד ללטש את התשובות שלו. כאן הבעיה רק מחמירה, כי מערכות ההערכה מתנהגות כמו מבחן אמריקאי ומתגמלות ניחוש מוצלח, לא שקיפות. כדי להמחיש את ההבדל, OpenAI הציגו השוואה בין מודל ישן לבין מודל חדש. במבט שטחי נראה שהישן "מדויק" יותר, אבל בפועל הוא טעה בביטחון מוחלט הרבה יותר. המודל החדש אולי ענה פחות, אבל כשהוא לא ידע, הוא פשוט אמר את זה.
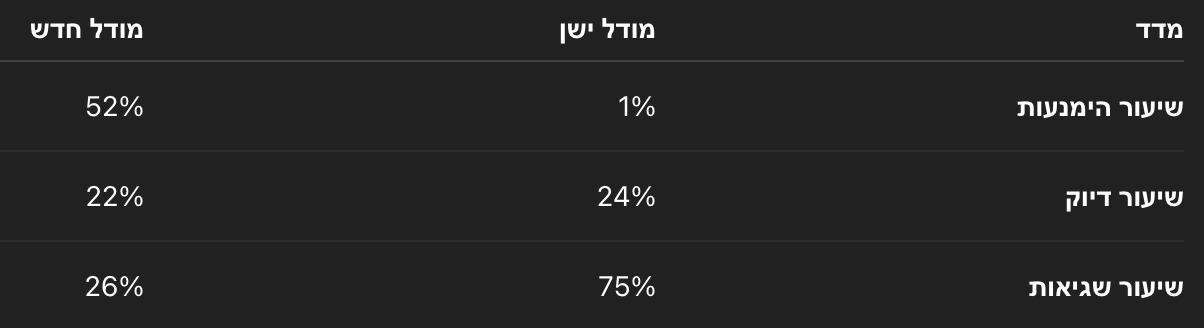
השוואת ביצועים: o4-mini מול GPT-5-thinking-mini
הטבלה מבוססת על נתונים ש-OpenAI פרסמו כהמחשה להבדלים בין מודלים, ולא על תוצאות ישירות מהמאמר האקדמי. והשאלה שנשארת פתוחה: מה עדיף - מודל שמנחש חזק וטועה, או מודל שמודה בכנות כשאין לו תשובה?
וכאן בדיוק נכנס הערך האמיתי של המחקר, כי הוא לא רק מצביע על ההבדלים בין מודלים ישנים לחדשים, אלא גם מנפץ מיתוסים עקשניים לגבי עצם קיומן של ההזיות.
אחת התרומות הגדולות של המחקר היא בכך שהוא מנפץ כמה מיתוסים עקשניים סביב הזיות במודלי שפה.
המציאות: זה לא יקרה. תמיד יהיו שאלות שאף מודל לא יכול לדעת, כמו מספר הטלפון של שכן שלכם או שם הכלב של מישהו שהוא לא פגש מעולם.
המציאות: לא נכון. מודל יכול פשוט לבחור לא לענות כשהוא לא בטוח, מה שמוריד דרמטית את כמות ההזיות.
המציאות: אין פה שום קסם שחור. ההזיות הן תוצאה צפויה של איך שהמודל למד ומה מתגמלים אותו עליו.
המציאות: מה שחשוב הוא מגוון רחב של מבחנים אמינים שבודקים אם המודל נוטה לנחש בלי לדעת ולא רק מדד בודד של "האם הוא הזה הפעם או לא".
אז איך אפשר לגרום למודלים להפסיק לנחש בביטחון כשהם לא יודעים? החוקרים מציעים שינוי קטן אבל מהותי - לא רק למדוד אם התשובה נכונה או לא, אלא גם כמה בטוח המודל כשהוא עונה.
במקום מבחן בסגנון "נכון/לא נכון", הם מציעים שיטה שמתגמלת זהירות:
תשובה נכונה מזכה בנקודה אחת.
טעות מורידה שתיים.
"אני לא יודע" שווה אפס - לא טוב, אבל גם לא נזק.
כך המודל לומד שלא כדאי לו להמר סתם, אלא עדיף לשתוק כשהוא לא בטוח.
האמת? זה לא רעיון חדש. מבחנים אמריקאים כמו SAT ו-GRE השתמשו בעבר בדיוק באותה טכניקה של הורדת ניקוד על ניחושים עיוורים כדי לעודד תלמידים לענות רק כשיש להם סיכוי אמיתי להיות צודקים. עכשיו, ההצעה היא להחיל את אותה גישה על בינה מלאכותית.
הבעיה היא לא רק טכנית אלא גם תרבותית. רוב מבחני הביצועים הפופולריים כמו GPQA, MMLU-Pro ו-SWE-bench, מעניקים נקודה מלאה על תשובה נכונה, ואפס נקודות על טעות או על "אני לא יודע". במבנה כזה ברור שמודל יעדיף לנחש, כי אין לו מה להפסיד.
כל עוד המדדים המרכזיים בעולם ה-AI ממשיכים לתגמל ניחושים מוצלחים, החברות ימשיכו לאמן מודלים שמעדיפים להמר מאשר להודות בחוסר ודאות. לכן הפתרון חייב להיות גם תרבותי, כלומר שינוי של כללי המשחק - איך אנחנו בוחנים, מודדים ומדרגים את המודלים.

המחקר הזה מסמן נקודת מפנה. שנים ניסינו להסביר את ההזיות של מודלי שפה כבעיה טכנית מסתורית, ועכשיו מתברר שהפתרון הרבה יותר פשוט - ללמד את המודלים להיות כנים לגבי מה שהם יודעים ומה שהם לא. תחשבו על זה כמו על יועץ אנושי, עדיף שיגיד "אין לי תשובה לזה" מאשר שימציא נתונים שנשמעים אמינים. גם בבינה מלאכותית, תשובה זהירה של "אני לא יודע" יכולה להיות שווה זהב כי היא חוסכת טעויות שעלולות לעלות ביוקר.
אם השינוי הזה יתפוס, נעבור מעולם שבו מודלים נוטים לנחש בכל מחיר, לעולם שבו הם יודעים לעצור ולהודות בחוסר ודאות. במערכות בריאות, משפט, חינוך או פיננסים - האמינות הזו תהיה יקרה יותר מכל פיצ’ר נוצץ.
לעיון במחקר המלא כנסו כאן.







