



עד כמה אפשר לסמוך על מה שה-AI אומר לנו? למרות הקפיצה המטאורית ביכולות של ג’מיניי (Gemini), ChatGPT, קלוד (Claude) ודומיהם, השיח סביב “הזיות” (hallucinations) במודלים הללו – כלומר, המצאות וביטחון מופרז בתשובות לא נכונות – רק הולך ומתגבר. מחקר חדש מבית Google מנסה להתמודד עם הבעיה מהשורש ומציע גישה רעננה: אולי הגיע הזמן שנקשיב לכל חלקי ה"מוח" של המודל, ולא רק לתשובה (או לשכבה) האחרונה שהוא מספק. וזה בדיוק מה שעושה שיטת SLED.
מחקר חדש של גוגל מציע פתרון אלגנטי לאחת הבעיות המתסכלות ביותר במודלי שפה גדולים (LLM): חוסר דיוק בתשובות והופעת “הזיות” בתוכן שנוצר על-ידי AI. במקום להסתפק במסקנות של השכבה האחרונה של המודל, החוקרים מציגים שיטה (SLED) המנצלת את המידע מכל שלבי החשיבה של הבינה המלאכותית, וממזגת אותם לכדי תשובה סופית מדויקת ואמינה יותר.
בבסיסם, מודלי שפה גדולים כמו ג’מיניי, GPT ו-Claude בנויים כך שהם מחקים את הדרך שבה בני אדם כותבים, מסיקים ומסבירים (בערך). אך שלא כמו בני אדם, שמסוגלים לבדוק את עצמם בזמן אמת ולחזור לשאלה במידה שענו שגוי, המודלים מסתמכים על אלגוריתם “פנימי” שלא תמיד נותן מקום לספקות. אתם אולי מכירים את זה בתור מודל שמשדר ביטחון מוחלט גם כשהוא טועה – וזה קורה בגלל אופן קבלת ההחלטות של המערכת. ישנן מגוון גישות ולצידן מחקרים רבים שמנסים להתחקות אחר הסיבה לאותן הזיות - רק לפני מספר שבועות כתבנו פה על מחקר דומה מבית OpenAI שמציע לשנות את הדרך שבה אנחנו מאמנים מודלים שכאלה. שלא נדבר על עשרות המחקרים מבית אנטרופיק (Anthropic).
גוגל מציעה גישה חדשנית ומעניינת במיוחד, שעוסקת באופן פעילותם של LLMים: מודלים אלו בנויים ממאות או אלפי שכבות (layers) שמבצעות חישובים על כל מילה, סימן או טוקן במשפט. התוצאה הסופית (כלומר, הטקסט שהמשתמש מקבל) מבוססת על ההערכה של השכבה האחרונה בלבד. אך מה קורה בדרך? ייתכן שבשכבות האמצעיות, המודל עצמו “חשב” אחרת או שקל אפשרויות נוספות. ומה קרה בפועל? במציאות רק “קול” אחד (זה של השכבה האחרונה) נשמע. בכך, אנחנו מפספסים ידע פנימי, חוכמה “חבויה” ובעיקר – את ההססנות הטבעית שעשויה הייתה להוביל לתשובות מדויקות יותר.
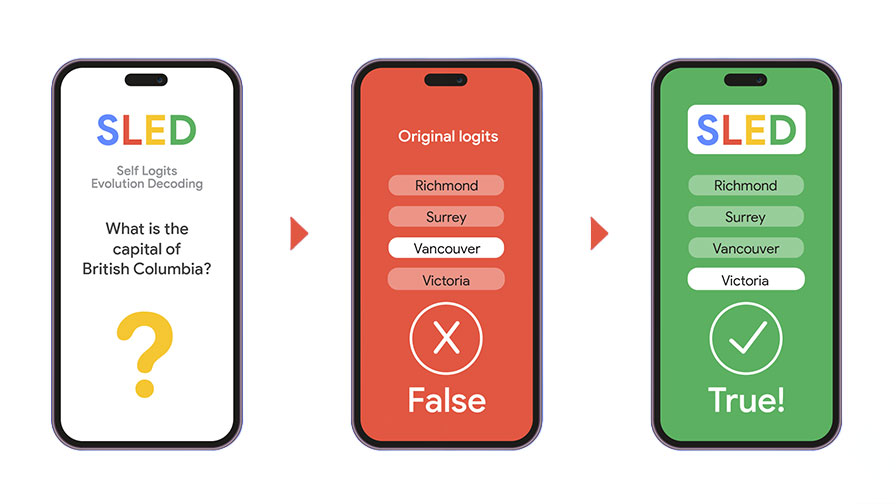
כשהמודל מפעיל את "כל המוח שלו", הוא לא טועה. עם ובלי SLED | קרדיט: Google.
כאן נכנסת לתמונה השיטה החדשה של גוגל: Self Logits Evolution Decoding – או בקיצור, SLED. הרעיון המרכזי מאחורי SLED פשוט אך מבריק: במקום להסתמך רק על השכבה האחרונה, למה שלא נאסוף “חוות דעת” גם משאר שכבות המודל, נשלב ביניהן באופן חכם, ורק אז נבחר את המילה או הביטוי הסופי?
גוגל פיתחה אלגוריתם שמסתכל על כל “תחנות הביניים” במסלול החשיבה של המודל. בכל אחת מהן, המודל מייצר תחזית (Distribution) לגבי המילה הבאה. SLED אוספת את התחזיות הללו, נותנת משקל לכל אחת (ולפעמים אפילו משקל שונה לשכבות שונות), ובונה ממוצע משוקלל של כל האפשרויות. כך מתקבלות החלטות שלא נשענות על “קונצנזוס דיקטטורי” של שכבה אחת, אלא על שיתוף פעולה אמיתי בין כל חלקי המודל.
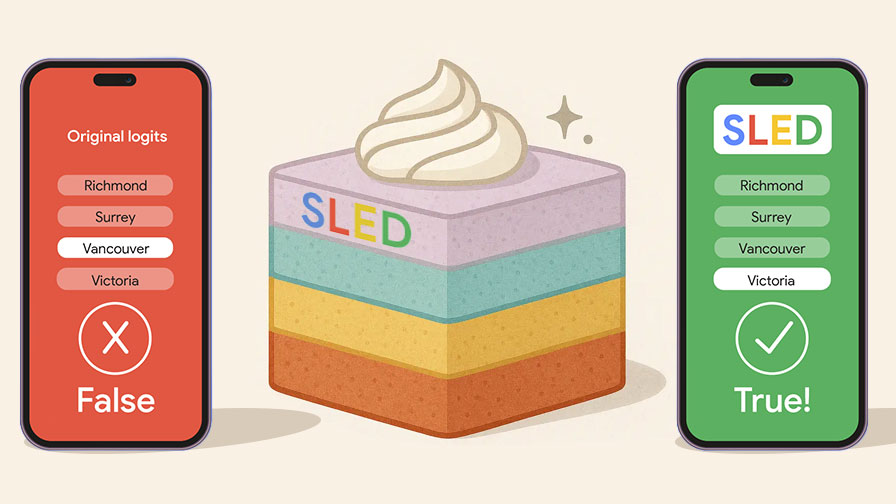
סרטון המחשה: בסרטון הבא ניתן לראות שכשהמודל מתבסס רק על השכבה העליונה, הוא בוחר בתשובה הצפויה ביותר לשאלה: מהי בירת קולומביה הבריטית? במקרה זה, המודל בוחר במילה עם המשקל הכי גבוה (ונקובר), כי זו העיר הכי ידועה או מפורסמת. אך כשהוא נעזר בכל שכבות החשיבה שלו, ועושה סינטזה בין כל ה"הרהורים" שלו, הוא מגיע למסקנה מדויקת יותר, שהתשובה הנכונה היא העיר "ויקטוריה" (אפילו שמדובר בעיר פחות מוכרת).
Credit: Google
בפועל, היכולת לשלב ידע מכל השכבות מאפשרת להימנע מהטיות שמקורן בדפוסי חשיבה שכיחים אך לא מדויקים. אחת התופעות השכיחות היא נטייה של מודלים לענות במהירות על שאלות בעזרת תשובות “פופולריות”, גם אם הן לא בהכרח נכונות. ממש כמו בדוגמה מעלה - כאשר שואלים מהי בירת קולומביה הבריטית, רבים עשויים לבחור ב"וונקובר" (העיר המפורסמת ביותר) אך התשובה הנכונה היא דווקא "ויקטוריה". במבחני SLED, השיטה מצליחה “להרים דגל” כשנוצרת התלהבות מיותרת סביב אופציה מסוימת, ולבחון שוב האם קיימת אפשרות אחרת שנשמעה מוקדם יותר לאורך הדרך.
המחקר של גוגל ממחיש את כוחה של שיטת SLED גם בסיטואציות שבהן דרושות כמה פעולות חישוביות ברצף. נניח שמודל מתבקש לפתור בעיה: “הילדה 'אש' קונה 6 צעצועים, כל צעצוע עולה 10 מטבעות. בקנייה של ארבעה צעצועים או יותר יש הנחה של 10%. כמה תשלם?”
מודל רגיל עשוי להעדיף את המשוואה הנפוצה A x B = C, ולכן ישיב: 6X10=60, תוך התעלמות מההנחה. בפועל, השכבות הפנימיות הרבה פעמים “רואות” את הצורך להכפיל את התוצאה הסופית (60) גם ב-0.9 כדי להחיל את ההנחה של 10%, אך השכבה האחרונה (בעקבות דפוסי תרגול נפוצים שהופיעו בתהליך האימון), מדלגת על זה (היא מתעדפת את המצב הנפוץ מבחינה סטטיסטית על פני המצב הנכון מתמטית). SLED מציף את כל תחנות הביניים, ובזכות זאת עונה:
6X10X0.9=54
פתרון שמפגין דיוק רב יותר והבנה עמוקה יותר של ההקשר. צפו בסרטון כדי לקבל המחשה ויזואלית של פתרון בעיה מתמטית זו:
Credit: Google
שיטת SLED פועלת ישירות בתהליך הפענוח (Decoding) של הטקסט, כלומר בשלב שבו המודל מתרגם את החישובים הפנימיים לטקסט קריא לאדם.
בכל פעם שמודל שפה מייצר מילה, הוא בעצם מחלק את המשפט לטוקנים: יחידות קטנות שיכולות להיות מילה, חלק ממילה, קידומת, סיומת או סימן פיסוק. המודל לא “פולט” את המילה הבאה מיד, אלא שוקל את כל האפשרויות, מחלק לכל אחת הסתברות (Logit), ומתקדם צעד-צעד. השיטה המסורתית נשענת על התחזית של השכבה האחרונה בלבד, אבל SLED לוקחת את "לוגיטי-הביניים" מכל שכבה, מעבירה אותם דרך אותה מטריצת תחזיות (Projection Matrix) כמו בשכבה האחרונה, ומקבלת סדרת תחזיות מלאה לכל האפשרויות – לאורך כל מסלול העיבוד.
SLED לא מחשיבה כל שכבה כבעלת משקל זהה. חלק מהשכבות נחשבות משמעותיות יותר, תלוי בסוג המטלה, סוג המודל וגודלו. האלגוריתם מחשב ממוצע משוקלל, וכך שכבות “חשובות יותר" ישפיעו יותר על ההחלטה הסופית. דרך גישה זו, SLED משמרת את הדיוק של המודל המקורי, אך משפרת אותו על ידי הבאת “קולות נוספים” לשולחן.
אחת החולשות הבולטות של מודלי שפה היא חוסר עקביות עובדתית. שיטה נפוצה לשיפור דיוק כזה היא חיבור למקורות חיצוניים בזמן אמת (כמו חיבור לרשת), אך אלה דורשים מערכת מורכבת ומוסיפים עלויות וזמן. SLED, לעומת זאת, פועל “מבפנים”, מבלי להיעזר במידע מבחוץ או ב-Fine Tuning יקר. כך הוא לא רק חוסך משאבים, אלא גם מונע תלות בגורמים נוספים ומבטיח שהדיוק משתפר מתוך המודל עצמו.
במחקר שנערך בגוגל, SLED נוסה על שלל מודלים פופולריים – ביניהם Gemma, GPT-OSS ומיסטרל (Mistral). בכל הניסויים, SLED שיפר באופן עקבי את הדיוק של המודלים, גם באתגרים של בחירה מרובה (Multiple Choice), גם בשאלות פתוחות, וגם במשימות “שרשרת חשיבה” (Chain of Thought). אפילו מול שיטות מתחרות מתקדמות כמו DoLa, שיטת SLED הובילה לעלייה משמעותית (עד 16%) בדיוק התשובות, וכל זאת במחיר כמעט זניח של הגדלת זמן הפענוח ב-4% בלבד.
אחד היתרונות החשובים הוא הגמישות של SLED. הוא פועל כמעט על כל מודל קוד פתוח, ללא קשר למשפחה, לחברת האם או לייעוד שלו. לא משנה אם מדובר במודל “בסיסי” או כזה שעבר התאמה להוראות (instruction tuned), שיטת SLED מתאימה את עצמה למגוון הרחב של דרישות, ומאפשרת שילוב עם שיטות פענוח נוספות לקבלת דיוק מקסימלי.
לאורך המחקר, החוקרים בחנו את SLED על שאלות מורכבות ממבחנים ידועים, דוגמת TruthfulQA ו-FACTOR, שם השיטה הפגינה ביצועים מרשימים. גם במבחני שאלות פתוחות, SLED מפחיתה בצורה דרמטית את הסיכוי להזיות.
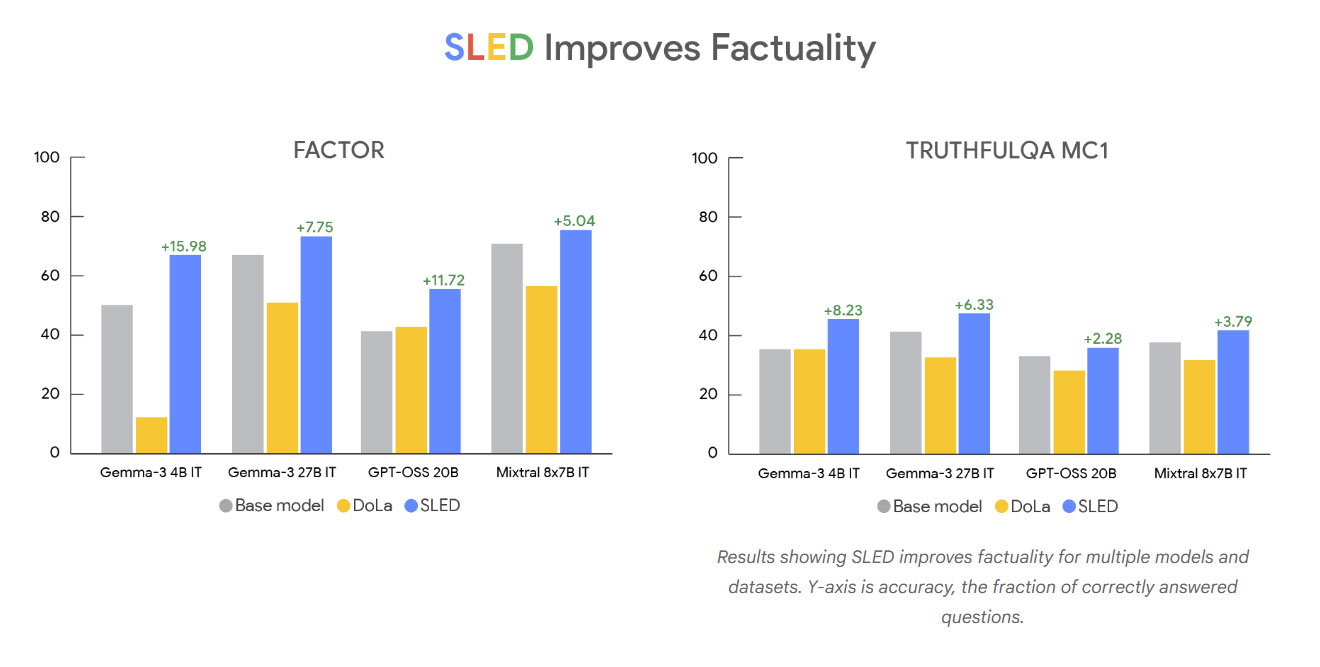
הביצועים של SLED | קרדיט: Google
למרות היתרונות הברורים, SLED לא באה לבטל את הצורך בביקורתיות - שגיאות והזיות עדיין אפשריות, במיוחד במצבים שבהם גם כל השכבות הפנימיות “טועות יחד”. יתרה מכך, לעיתים נדירות הוספת “קולות” לשולחן עשויה לבלבל את המודל כאשר יש ריבוי חוות דעת שאינן עקביות. למרות זאת מדובר בשיפור מהותי על פני הגישה המסורתית.
היישום של SLED אינו מוגבל רק לשפה טבעית. בגוגל מציעים להרחיב אותו למשימות של הפקת קוד, Visual QA ואף כתיבה ארוכה ומורכבת. המפתח הוא בזיהוי תבניות ידע שמפוזרות לאורך השכבות השונות במודל, והבנה שמידע קריטי אינו נמצא תמיד “רק בסוף”.
רוצים לנסות בעצמכם? SLED הוטמע כקוד פתוח בגיטהאב של גוגל, וניתן להורידו ולהטמיעו כמעט בכל מודל מודרני. מפתחים שמעוניינים לשפר את הדיוק, לצמצם שגיאות עובדתיות ולהפחית הזיות יכולים לנסות את SLED בצורה פשוטה ולבחון בעצמם את ההשפעה.
שיטת SLED מגלמת תפיסה חדשה: במקום לסמוך בעיניים עצומות על התשובה הסופית, הגיע הזמן להקשיב ל”מחשבות” שהתגלגלו לאורך כל מסלול החשיבה. במקום להעדיף תמיד את הפתרון המיידי, כדאי להעניק משקל ל"הרהורים של המודל" ולדיוקים שהוא מציע מתוך שלל שכבות הידע הפנימי שלו.
הגישה הזו מסמנת מגמה ברורה בבינה מלאכותית - צמצום תלות במקורות חיצוניים, חיזוק תחושת האמון במודל עצמו, ושאיפה ל-AI שידע “להתייעץ עם עצמו” לפני שיחווה דעה. לא תמיד צריך לאמן ו"לבנות מאפס" מודלים חדשים ועוצמתיים יותר, כשאפשר לחשוב על דרכים יצירתיות לגרום למודלים קיימים "לחשוב אחרת", ובכך להגביר את הדיוק, המהימנות והיכולות שלהם. למרות ש-SLED אינה “פתרון קסם” לכל בעיה, היא פותחת דלת להעמקת ההבנה של מודלים עצמאיים, גמישים וניתנים לשדרוג מהיר, ובמקביל מדגימה כיצד מהפכות אמיתיות קורות דווקא כששמים לב לפרטים הקטנים שמתחבאים מתחת לפני השטח.
התקדמות זו מסקרנת במיוחד לאור הגידול בתלות שלנו במודלי שפה – לא רק בתור כלים לכתיבה או סיכום, אלא גם ככלי עזר לאנליזה, פתרון בעיות, והכוונה בעולם האמיתי. שילוב SLED בתוך תהליכי פיתוח גדולים של פלטפורמות AI נוספות, מצביע על עתיד שבו “הפנימיות” של המודל תעמוד במרכז קבלת ההחלטות, והדרך אל תשובות טובות באמת תעבור דרך הקשבה אמיתית… לכל קול במערכת.