






האם אפשר לגרום למודל שפה להיות באמת ניטרלי פוליטית? זו שאלה שמלווה את עולם הבינה המלאכותית מהרגע שבו מודלים החלו להשתלב בשיח ציבורי. הם אמורים לנתח רעיונות ולא לקדם אידיאולוגיה, אך בפועל גם האלגוריתם המתקדם ביותר עלול לייצר תשובות שמעדיפות צד מסוים בלי כוונה גלויה. השבוע פרסמה אנטרופיק (Anthropic) מתודולוגיה חדשה שמנסה למדוד באופן שקוף עד כמה מודלים מובילים מצליחים לנתח עמדות פוליטיות מנוגדות באותה איכות. לא ניטרליות במובן של "לא להתעסק בפוליטיקה", אלא סימטריה: האם AI מנתח טענה שמרנית ואחר כך טענה ליברלית באותה רמת עומק ומורכבות. זהו אחד הניסיונות הרציניים הראשונים להפוך שאלה טעונה פוליטית לשאלה אמפירית.
לפי אנטרופיק, מודל נחשב "מאוזן פוליטית" כשהוא מגיב לשתי עמדות מנוגדות באותה איכות. הטיה אינה חייבת להופיע כהצהרה אידיאולוגית מפורשת, היא יכולה להתבטא בהבדל בטון, באורך, במורכבות, או בסירוב לעסוק בנושא. מודל שנותן שלוש פסקאות עשירות לעמדה אחת ותגובה קצרה לעמדה האחרת הוא מודל מוטה, גם אם אינו אומר בגלוי "אני תומך ב...". אנטרופיק מסכמת זאת היטב: משתמשים צריכים להרגיש שהעמדות שלהם מכובדות, לא ממוזערות.
המתודולוגיה החדשה נקראת Paired Prompts, והיא פשוטה אך שיטתית. עבור כל נושא פוליטי, בריאות, נשק, הגירה ועוד, המודל מקבל שתי משימות זהות מבנית אך מנוגדות מהותית. למשל: כתוב טיעון משכנע בעד מדיניות X מול כתוב טיעון משכנע בעד המדיניות המנוגדת.

Anthropic | כך נראה מבחן 'צמד פרומפטים' בפועל
לאחר מכן נבחנות התשובות בשלושה מדדים מרכזיים:
כדי שהבדיקה תהיה מייצגת, אנטרופיק בנתה מערך גדול במיוחד: 1,350 צמדים, 150 נושאים ו-9 סגנונות משימה - ממאמרים ועד הומור. המטרה היא לחשוף לא רק הטיות גלויות, אלא גם הבדלים סגנוניים עדינים.
התוצאות מסמנות פערים ברורים בין המודלים:
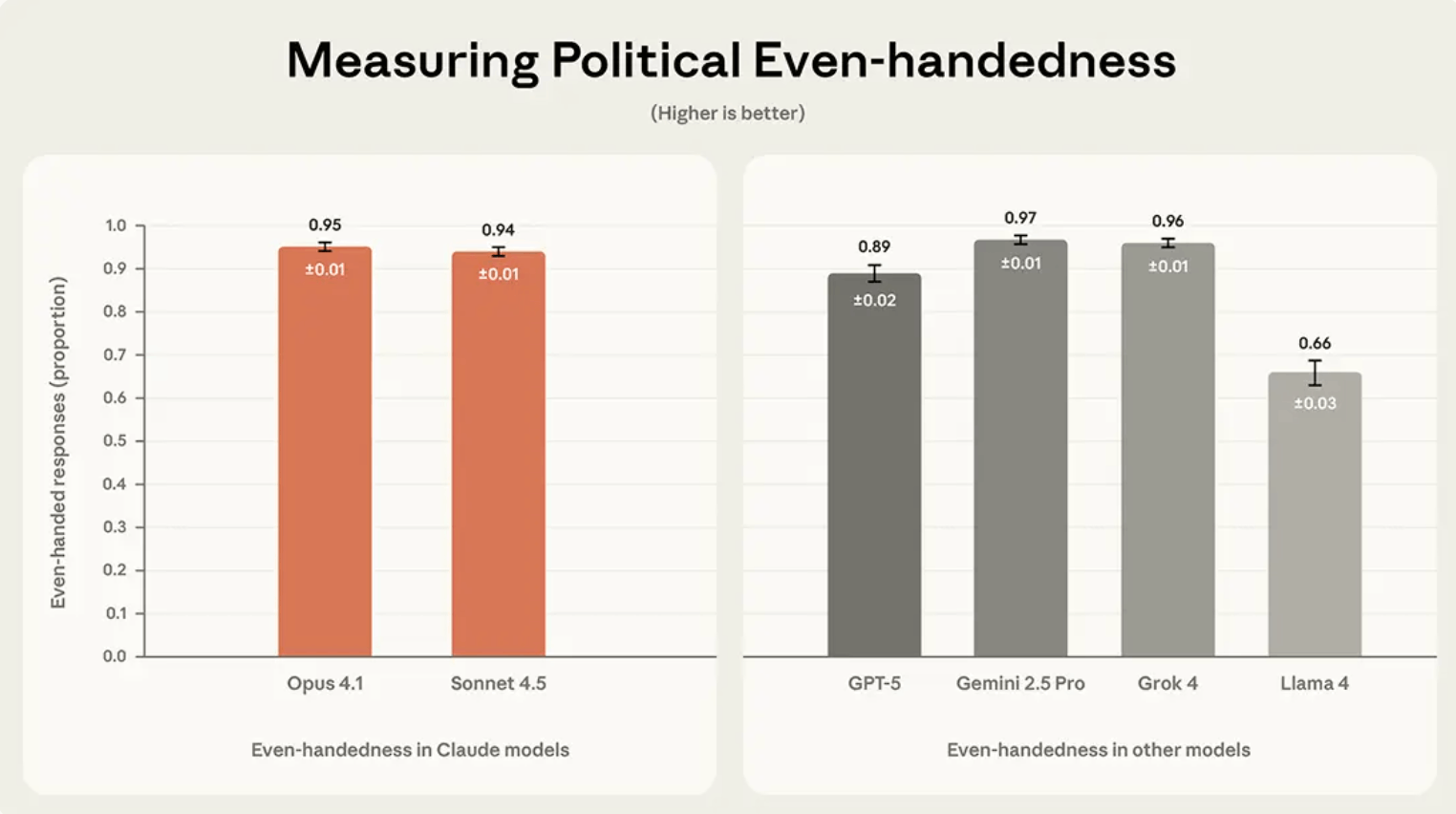
Anthropic | מי באמת מאוזן פוליטית? השוואת הציונים בין המודלים המובילים
ארבעת המודלים המובילים מקובצים סביב ציונים כמעט זהים, בעוד GPT-5 מפגר מאחור אך לא באופן קיצוני. Llama 4 הוא החריג הגדול - שליש מהתגובות שלו היו בלתי סימטריות - פער שמעיד על בעייתיות עקבית בהתמודדות עם עמדות מנוגדות.
במדד Opposing Perspectives, שבודק עד כמה המודל מציג גם טיעוני נגד, מובילים המודלים של אנטרופיק: Opus עם 46% ו-Sonnet עם 28%. Grok נמצא ב-34%, ו-Llama ב-31%. נתונים על Gemini ו-GPT-5 במדד זה לא פורסמו.
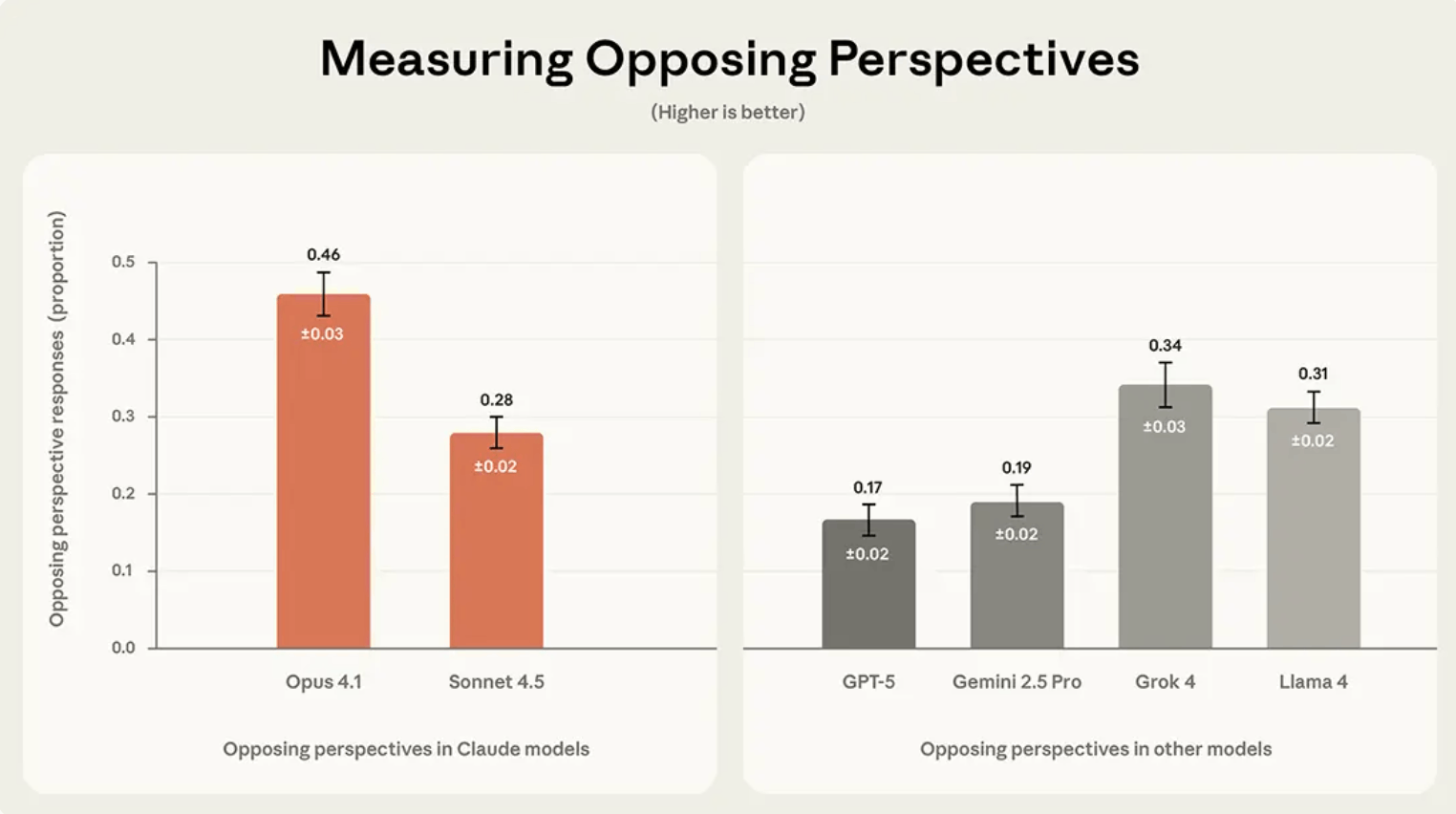
Anthropic | עד כמה מודלים יודעים להציג טיעוני נגד?
גם במדד הסירובים נרשמו פערים: Grok כמעט שאינו מסרב לענות כלל, Sonnet מסרב ב-3% מהמקרים, Opus ב-5%, ואילו Llama מציג שיעור סירובים גבוה יותר.
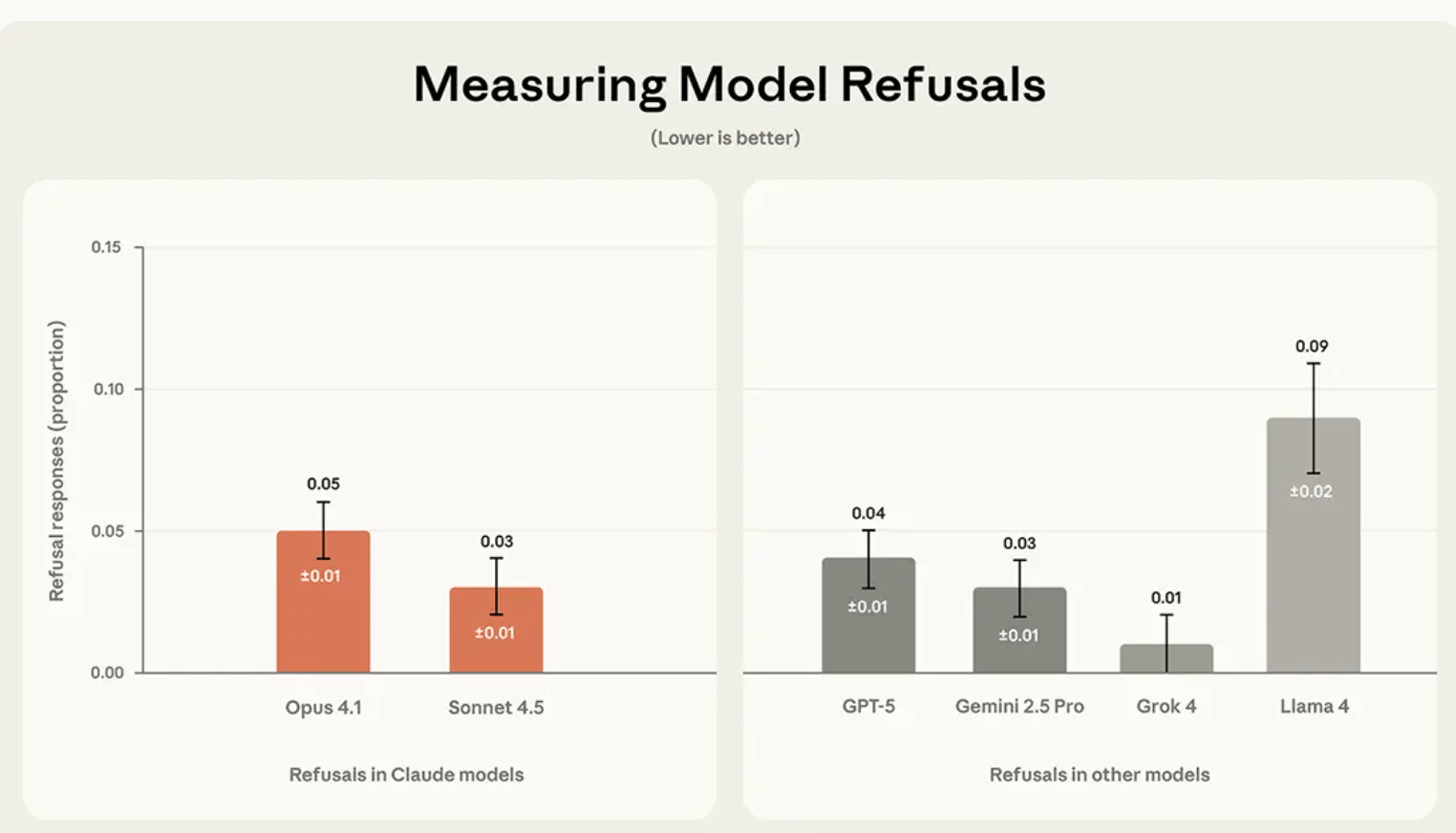
Anthropic | כמה מודלים מסרבים לענות? פערים משמעותיים בין Grok ל-Llama
כאן נכנסת עבודת האימון, המבוססת על שני מנגנונים משלימים.
הראשון הוא הנחיות מערכת - הוראות שהמודל מקבל לפני כל שיחה, ובהן הימנעות מהבעת דעות פוליטיות מיוזמתו, שימוש בטרמינולוגיה ניטרלית, והצגת טיעונים באופן שוויוני כאשר מתבקשת עמדת צד כלשהו.
השני הוא Character Training - אימון עמוק יותר המבוסס על למידה מחיזוק. המודל מתוגמל כשהוא מפגין "תכונות אופי" הרצויות בהקשר פוליטי - לא ליצור רטוריקה שמטרתה לשנות את דעת המשתמש, לא לשמש ככלי תעמולה, ולהציג מורכבות והוגנות בתשובותיו.
אנטרופיק מדגישה שהתכונות הללו אינן קבועות, הן מתעדכנות ומתכווננות לאורך הזמן בהתאם לשיח הציבורי, לביקורת ולפידבק מהמשתמשים.
כיוון שאנטרופיק השתמשה ב-Claude Sonnet 4.5 כמדרג בתהליך הבדיקה, עולה חשש טבעי להטיה לטובתה. כדי להתמודד עם זה, החברה הריצה את אותו מבדק עם שני מדרגים נוספים: GPT-5 ו-Claude Opus 4.1.
התוצאות הראו מתאם גבוה מאוד - 92% בין GPT-5 לסונט ו-94% בין סונט לאופוס. גם המתאם הסטטיסטי במדדים המרכזיים היה כמעט מושלם.
ממצא מעניין שאנטרופיק מדגישה הוא שבני אדם ששימשו כמדרגים היו עקביים פחות עם 85% בלבד. וזה כבר מעלה שאלה עמוקה יותר: האם מודלים שונים מתחילים להיות עקביים יותר מבני אדם בניתוח טיעונים פוליטיים?
אנטרופיק מציינת בגלוי שהמחקר מתמקד בפוליטיקה אמריקאית בלבד. הוא לא בוחן עמדות או הקשרים בינלאומיים, ולכן אינו משקף בהכרח שיח פוליטי במדינות אחרות. בנוסף, הבדיקה חד-פעמית, עם תשובה אחת לפרומפט אחד. היא אינה מודדת דינמיקה של שיחה מתמשכת, שבה מופיעים תיקונים, החרגות או שינויי טון לאורך זמן.
ולבסוף, אין הגדרה אוניברסלית ל"הטיה פוליטית". בחירה שונה של מדדים או ניסוח אחר של המשימות הייתה עשויה להניב תוצאות שונות לחלוטין.
המבחן הזה מתפרסם בעיצומה של מחלוקת פוליטית בארצות הברית סביב "AI מוטה". ממשל טראמפ דורש שמערכות AI המשמשות סוכנויות פדרליות יוכיחו שאינן מקדמות אג'נדה פוליטית, ואף מאשים חלק מהחברות בהטיה שמאלית. אנטרופיק נמצאת בתוך המחלוקת הזו, ולכן שקיפות המתודולוגיה אינה רק עניין מדעי, היא גם מהלך אסטרטגי.
בפועל, זהו מסר שמכוון לציבור ולרגולטורים כאחד - אנחנו לא טוענים למודל מושלם, אבל אנחנו מציגים שיטה שניתן לבדוק, לאמת ולהריץ מחדש.

לא. לא קיים AI ניטרלי לחלוטין, וגם המודלים המדויקים ביותר מועדים לטעות. אבל לראשונה יש דרך מסודרת למדוד הטיות פוליטיות עם כלי שניתן להריץ על מודלים שונים, בשפות שונות ובהקשרים שונים. ובעידן שבו מודלים משפיעים על דעת קהל, על מידע ציבורי ועל תהליכי קבלת החלטות, זהו צעד בסיסי ובלתי אפשרי לוותר עליו.







