





בעידן שבו בינה מלאכותית משתלבת יותר ויותר בעבודה היומיומית שלנו, צצה בעיה שקטה, אבל מסוכנת: הזיות של מודלים. כלומר, מצבים שבהם המודל "ממציא" עובדות שנשמעות אמינות - אבל שגויות או בדויות לגמרי. זו אולי המגבלה הגדולה ביותר שמונעת שימוש יומיומי בטוח ב־ChatGPT ודומיו. והתוצאה? אמון מלא בתוצר - כי העטיפה יפה, הניסוח רהוט, ובעיקר: כי המודל אומר את זה בביטחון מוחלט. ככל שהמודלים הופכים לחלק מתהליכי קבלת החלטות, גובר הצורך לזהות, למדוד ולצמצם את התופעה הזו. המאמר הזה מבוסס על Hallucination Leaderboard של Vectara - פרויקט שמודד את שיעורי ההזיות במודלים הגדולים, ובוחן פתרונות כמו RAG - טכנולוגיה שבה המודל לא רק מנחש: הוא קודם מאתר מידע אמיתי ורק אז כותב תשובה שמבוססת עליו. המטרה כאן ברורה: לא רק להבין מה הן הזיות, אלא לצייד אתכם בכלים פרקטיים להתמודדות. כי בינה מלאכותית צריכה להיות לא רק חכמה - אלא גם אמינה.
הזיות הן אחת הבעיות המדאיגות ביותר במודלים גדולים של שפה (LLMs). מדובר בתשובות שנשמעות אמינות, אבל פשוט לא נכונות. לפעמים הן שגויות, לפעמים מומצאות לגמרי. איך זה קורה? כי המודלים לא באמת “מבינים” את העולם, הם רק חוזים את המילים הבאות על סמך טקסטים שראו. אין להם בקרה פנימית לעובדות.
הבעיה לא נגמרת בטקסטים. גם מודלים חזותיים מזייפים: למשל, מערכת שציירה את קירבי (הדמות הוורודה של נינטנדו) עם שיניים - למרות שהיא ידעה לומר במפורש שלקירבי אין שיניים. המערכת "זכרה" נכון בטקסט, אבל "המציאה" בתמונה. זה מדגיש את הפער בין רכיבי המודל.

קירבי בולע את דונקי קונג עם (ובלי) שיניים. Credit: vectara.com
לפעמים זה מצחיק. אבל ברוב המקרים - ממש לא. כמו עורך הדין שציטט פסיקות משפטיות שהומצאו על ידי ChatGPT, או התשובה השגויה לשאלה בסיסית: “מה כבד יותר, קילו מים או קילו אוויר?”

מה כבד יותר? Credit: vectara.com
המכנה המשותף? אובדן אמון.
כשה-AI משתלב בתחומים כמו רפואה, משפט או חינוך - דיוק הוא לא מותרות. הזיות פוגעות בדיוק בזה: האמינות. וזה אתגר שאי אפשר להתעלם ממנו.
כדי להבין למה ChatGPT ודומיו מייצרים עובדות שגויות, צריך להבין איך הם בנויים. הם לא לומדים את האמת - הם לומדים דפוסים בטקסטים. כלומר: מה סביר שיבוא אחרי מה. כשמודל מייצר תשובה, הוא לא בודק עובדות ולא שואל “האם זה נכון?” הוא פשוט מנחש את המילה הבאה שנשמעת הגיונית. אין לו מושג אם מה שהוא כותב מבוסס או לא.
כאן נכנסת הבחנה קריטית בין שתי גישות: הראשונה נקראת ספר סגור: המודל עונה מתוך "הזיכרון" של מה שלמד באימון. אין לו גישה למידע מעודכן או אמין. השנייה היא ספר פתוח: המודל קודם כל מאחזר מידע בזמן אמת, ואז מסכם אותו. גישה זו מורידה משמעותית את שיעור ההזיות.
בעיה נוספת: המודלים לא יודעים להודות כשהם לא יודעים. הם “זורמים” עם תשובה שנשמעת טוב, גם אם היא שגויה לגמרי. והכי מסוכן? הם עושים את זה בביטחון מלא.
אז לא, זו לא רשלנות. הזיות הן תוצאה ישירה של איך שהמודלים האלה בנויים ומתומרצים: לכתוב טקסט יפה ולאו דווקא נכון.
כדי לבדוק עד כמה מודל נוטה "להמציא", צריך שיטה טובה למדוד את זה. כאן נכנסת לתמונה Vectara, שפיתחה כלי בשם HHEM (Hallucination Evaluation Model) - שיטה חדשנית שמודדת האם התשובות של המודל נאמנות למקור. HHEM לא בודק אם הטקסט “נשמע טוב”, אלא אם הוא באמת מבוסס. הוא מתמקד בסיכומים שבהם המודל ניסח מחדש את המידע, לא רק העתיק. ובניגוד למה שאפשר לחשוב, מדובר במודל קטן יחסית - מה שמוכיח שלא צריך בינה מלאכותית ענקית כדי לעשות עבודה חכמה.
המודל הושווה לאחרים (כמו SummaC ו־TrueTeacher), וזכה לציון גבוה מאוד - 0.837 במדדים כמו דיוק ויכולת הבחנה בין אמת להזיה. בשלב הבא הקימה Vectara את לוח המובילים של ההזיות - דירוג פומבי של מודלים שסיכמו כתבות אמיתיות (כמו מ־CNN או DailyMail). כל סיכום נבדק לפי שיעור הזיה - כמה מהסיכומים הכילו עובדות שגויות, שיעור עקביות - ההיפך מהזיות (100% פחות שיעור ההזיה), שיעור תגובה - כמה פעמים המודל ענה בכלל ואורך סיכום ממוצע.
השורה התחתונה? יש עכשיו דרך ברורה להשוות בין מודלים ולמדוד בדיוק מי נוטה להזות ומי מספק מידע אמין. וזה צעד חשוב לעבר עולם AI שאנחנו באמת יכולים לסמוך עליו.
אז מי שומר על האמת בעולם שבו AI לפעמים ממציא? Hallucination Leaderboard של Vectara נותן תשובה. זהו דירוג שמתעדכן ב־GitHub ומשווה בין מודלים גדולים לפי רמת האמינות העובדתית שלהם - על בסיס גרסה מתקדמת של מודל ההערכה HHEM-2.1. נכון לאפריל 2025, המקום הראשון שייך ל־Gemini-2.0-Flash-001 מבית Google, עם שיעור הזיה של 0.7% בלבד. אחריו Gemini-2.0-Pro-Exp גם של גוגל, o3-mini-high של OpenAI, ו־Mockingbird-2-Echo של Vectara. כולם עם שיעורי הזיה של פחות מ־1%.
זה אולי מפתיע, אבל חשוב להבין: מודלים קטנים ויעילים עקפו לא פעם את הענקים. המשמעות? מה שחשוב באמת הוא איך המודל מאומן ואיך הוא בנוי - לא רק כמה פרמטרים יש לו.
משפחות שומרות על רמה - מודלים מאותה סדרה (כמו GPT או Gemini) מציגים ביצועים עקביים.
פחות לפעמים זה יותר - סיכומים קצרים נוטים להזות פחות.
עדיף לשתוק מאשר להזות - יש מודלים שמסרבים לענות כשאין להם ודאות. וזה דווקא דבר טוב. כמו שנאמר: "סייג לחכמה - שתיקה."
הלוח כולל גם תרשימים חזותיים שממחישים את הפערים - עד פי 7 בין המובילים לגרועים. ויש גם השוואה לגרסאות קודמות, שמראה איך התחום כולו משתפר לאורך זמן.
ולמה זה חשוב? כי רק כשמודדים - אפשר להשתפר. ולוח ההזיות הוא כלי מפתח בדרך ל-AI באמת אמין.
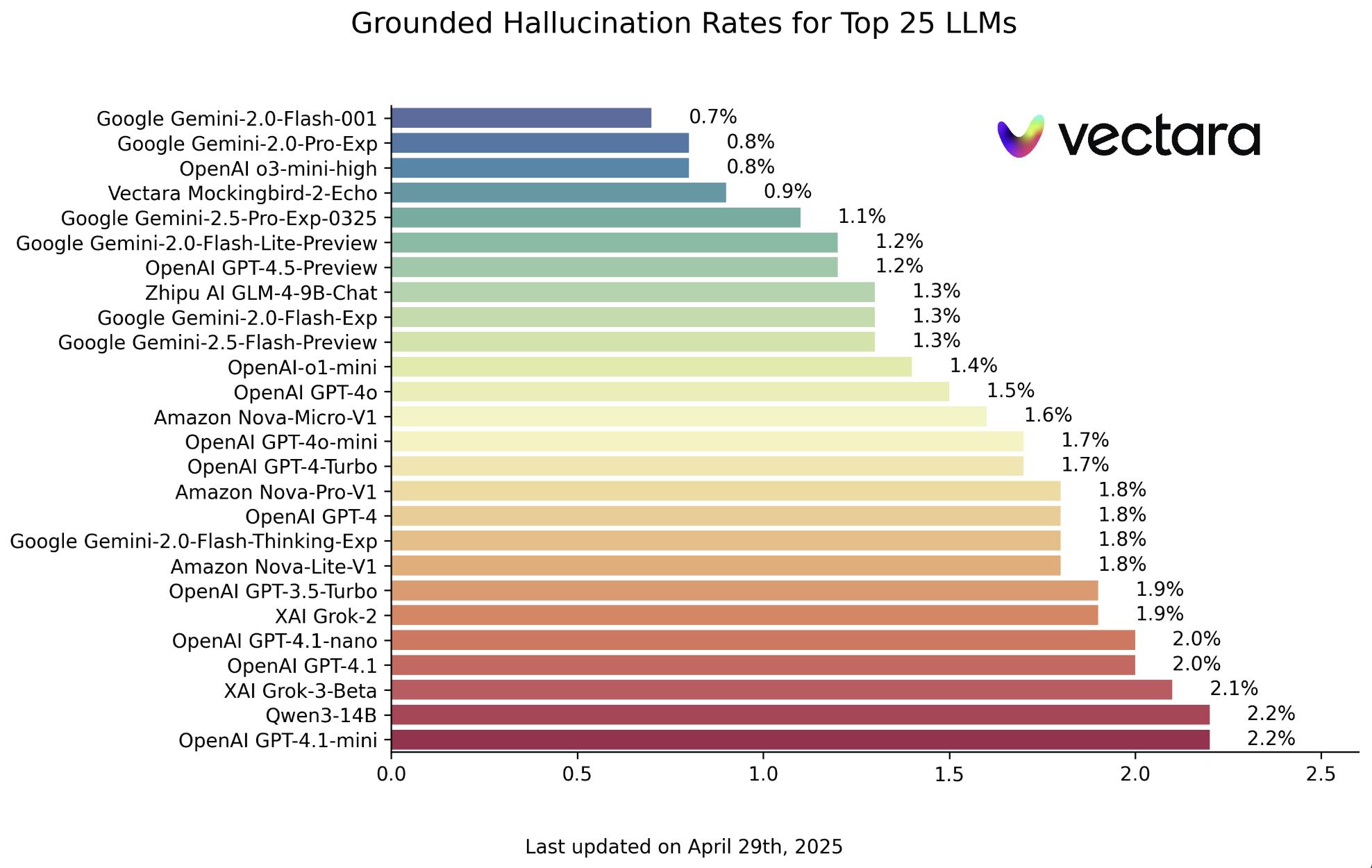
Gemini-2.0-Flash-001 עם שיעור הזיה של 0.7% בלבד. Credit: vectara.com
החדשות הטובות: יש דרך להתמודד עם זה. הפתרון המוביל נקרא RAG - ראשי תיבות של Retrieval-Augmented Generation. או בעברית פשוטה: מודל שיודע קודם לחפש - ואז לנסח. במקום לסמוך על “הזיכרון” הפנימי של המודל, כמו בגישת "ספר סגור" - RAG פועל בגישת "ספר פתוח": המערכת מאחזרת מידע מעודכן ממקור חיצוני, ורק אז מבקשת מהמודל לסכם אותו. כך היא מצמצמת משמעותית טעויות והמצאות. אנחנו כבר רואים את זה בפעולה - למשל ב־Bing Chat או Google Search Chat, שמשלבים חיפוש עם ניסוח מבוסס־מודל.
כדי שמערכת RAG תעבוד באמת - שני דברים חייבים לקרות: קודם כל, האחזור חייב להיות מדויק - כלומר, המידע שנשלף צריך להיות רלוונטי, עדכני ואמין. אבל זה לא מספיק. גם הסיכום שהמודל מנסח חייב להישאר נאמן למקור, בלי לעוות או להמציא. כאן בדיוק נכנסים לתמונה כלים כמו HHEM, שמודדים עד כמה הפלט משקף את העובדות שנשלפו.
עם זאת, RAG היא רק אחת מהשיטות להפחתת הזיות. חלק מהמודלים עוברים כיוונון ייעודי שמלמד אותם לזהות ולצמצם נטייה להמציא. אחרים עושים שימוש ב־כימות אי־ודאות - ומאותתים כשהם לא בטוחים, במקום לנחש. ויש גם כאלה שמפעילים מודולי אימות - שבודקים את התשובה מול מקורות לפני שהיא נשלחת למשתמש. ולמרות שיש כבר מודלים שמציגים עקביות של יותר מ־99% - עדיין מדובר באתגר פתוח. במיוחד כשמדובר בשאלות מורכבות, או בתחומים שבהם אין הרבה מידע איכותי.
בתמונה המצורפת תראו השוואה בין שתי דרכי פעולה של מודלי שפה. בצד ימין - גישת "ספר פתוח" (Open Book Q&A): המודל קודם מאחזר מידע ממקור חיצוני ורק אחר כך מנסח תשובה על בסיסו. כך מתקבלת תשובה מבוססת יותר, שמפחיתה טעויות והזיות. בצד שמאל - גישת "ספר סגור" (Closed Book Q&A): המודל מנסה להשיב רק מתוך מה שלמד באימון, בלי לבדוק במקורות בזמן אמת. זוהי גישה מהירה, אך מועדת יותר לשגיאות ולהמצאות:
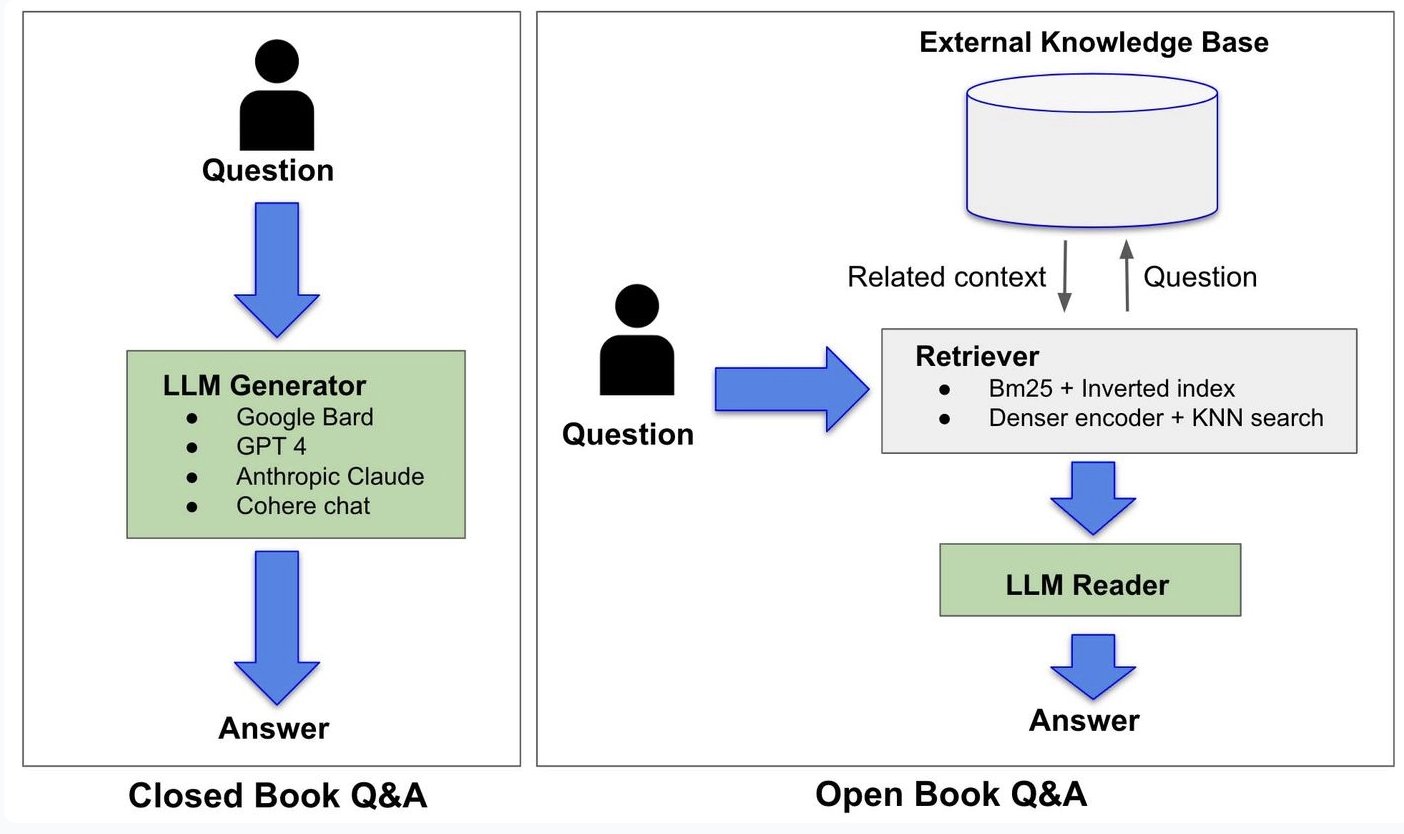
השוואה בין שתי גישות למענה על שאלות על ידי מודלי שפה גדולים. Credit: vectara.com
הזיות הן לא רק באג טכני - הן אתגר שדורש התמודדות מודעת מצד כולם: מפתחים, ארגונים וגם משתמשים.
1. לבחור נכון את המודל: לוח ההזיות של Vectara עוזר לזהות מודלים מדויקים במיוחד - וזה קריטי בתחומים כמו רפואה, משפט וחינוך, גם אם זה בא על חשבון מהירות או יצירתיות.
2. ליישם RAG: חיבור למקורות מידע חיצוניים מאומתים מצמצם הזיות. אבל זה עובד רק אם מנגנון האחזור מדויק והמודל יודע לנסח בלי לעוות.
3. לאותת כשאין ודאות: מודלים צריכים להבהיר מתי הם לא בטוחים. זה יכול להיות ניסוח זהיר ("למיטב ידיעתי...") או ציון רמת ביטחון.
4. לחנך את המשתמשים: ללמד את המשתמשים לא לסמוך בעיניים עצומות. לבדוק, להצליב, להבין את הגבולות של המערכת ולהשתמש בה בחכמה.
5. להיות שקופים: ארגונים צריכים להצהיר בגלוי על מגבלות המערכת. השקיפות בונה אמון ושומרת על אחריות.
1. לשמור על ספקנות בריאה: לא כל מה שנשמע חכם - באמת נכון. אל תדלגו על הצלבת מקורות.
2. להבין את המגבלות: המודל עשוי להשיב בביטחון מלא גם כשהוא טועה. חשוב לזכור את זה.
3. להשתמש באחריות: ראינו מקרים, גם בעולם וגם כאן בישראל, שבהם עורכי דין ציטטו פסקי דין שלא קיימים. זו תוצאה ישירה של שימוש במודלים שמספקים מידע בביטחון מופרז, גם כשהוא פשוט לא נכון. טעויות קטנות כאלה עלולות להוביל להשלכות גדולות - משפטיות, מקצועיות ואישיות.
פסקי דין מומצאים. Credit: vectara.com
שמירה על אמינות לפעמים באה על חשבון יצירתיות, עומק או מהירות. אין כאן פתרון אחד שמתאים לכולם. הבחירה הנכונה תלויה בהקשר ודורשת אחריות, תכנון וחוכמה.
המאבק בהזיות לא נגמר - הוא רק מתחיל. התחום של זיהוי והפחתת שגיאות עובדתיות נמצא היום בתנופה, ואלה שישה כיוונים מבטיחים שכדאי לעקוב אחריהם:
מודלים כמו HHEM עושים עבודה טובה, אבל העתיד שייך לכלים שיידעו להבחין בין סוגי הזיות - קטנות מול קריטיות, או לפי תחום.
במקום לבדוק אחרי, המודלים העתידיים יבדקו תוך כדי. אחזור בזמן אמת, בדיקת עובדות ותיקון לפני שהשגיאה יוצאת החוצה.
זה לא רק גודל. שיטות ענישה להזיות, ייצוג של חוסר ודאות, ושכבות חכמות - כל אלה ישפרו את האמינות.
רפואה, משפט, מדע - לכל תחום יש שפה ומידע משלו. מודלים ייעודיים יידעו לדייק יותר במרחבים מורכבים.
RAG יהפוך לחכם יותר, יבין כוונות, ימצא מקורות מדויקים, ויבנה הקשר עשיר שיאפשר תשובה אמינה באמת.
הצגת רמת ודאות, קישורים למקורות, או אפילו דעות חלופיות - כל אלה יעזרו למשתמש להבין מתי לסמוך ומתי לבדוק שוב. מעבר לכך, נתחיל לראות גם מערכות שלומדות ממשוב אנושי ומשתפרות בזמן אמת, רגולציה שדורשת שקיפות, גילוי מגבלות, ואחריות משפטית על מידע שגוי.
העתיד לא נקי מהזיות - אבל הוא בהחלט בכיוון הנכון.

הזיות הן לא רק תקלה טכנית, הן החסם הגדול ביותר שעומד היום בפני אימוץ אמיתי של בינה מלאכותית. הן אולי מתחילות בטעות קטנה, אפילו משעשעת - אבל יכולות להסתיים באבחון רפואי שגוי, בייעוץ משפטי מסוכן, או בפגיעה באמון של תלמיד, משתמש או לקוח. כדי להתמודד עם זה, העולם עובר לגישה פתוחה יותר. מודלים שמחוברים למידע אמיתי בזמן אמת - לא רק למה שהם זוכרים מהאימון - מייצרים פחות הזיות ויותר דיוק. מתברר שגם הגודל כבר לא משחק תפקיד כמו פעם. דווקא המודלים הקטנים, שבנויים נכון, מצליחים להחזיק באמינות גבוהה יותר. אבל כל זה לא שווה הרבה בלי מדידה. בלי כלים כמו HHEM ולוחות דירוג שמאפשרים השוואה, אי אפשר לשפר באמת.
אז מה נדרש? מהמפתחים - דיוק לפני באזז, שקיפות אמיתית, ומוכנות להודות כשאין ודאות. מהמשתמשים - ספקנות בריאה, הצלבת מידע, והבנה שמודל מרשים הוא עדיין לא מקור מוסמך. אנחנו נמצאים בתחילתה של דרך ארוכה. עם כלים טובים יותר, מבנים חכמים יותר, ויותר מודעות לסיכון - נוכל להפוך את הבינה המלאכותית ממשהו שמרשים אותנו, למשהו שאנחנו באמת יכולים לסמוך עליו. אבל כדי שזה יקרה, היא צריכה לעמוד על שלושה עקרונות פשוטים: אמת. אחריות. אמון.








בסופו של מה שהכי משפיע על אמינות המידע זה אם המידע עליו אומן המודל הוא מספיק מגוון ואמין. אם אין מספיק מידע למודל או שהמידע שיש לו לא מדוייק (בין אם אם הוא לוקח גם מידע מהאינטרנט ובין שלא) הוא יעשה יותר הזיות לדוגמא כשאני מבקש מידע על ספריית תכנות כל שהיא הרבה פעמים אני מקבל מידע שגוי אפילו שהמודל מנסה להשוות עם האינטרנט וזה קורה כי ספריות תוכנה מתעדכנות מאוד מהר ולמודל לרוב יש מידע לא מספיק מעודכן והוא לא יודע כיצד לסנן מה רלוונטי ומה לא
לא בדיוק… המודלים של היום אומנו על כמות דאטה אדירה, כולל דאטה עדכני, ויש להם מנגנונים לשליפת מידע והצלבתו (למשל עם הרשת ו/או שרשרת מחשבה וכו’ וכו’ וכו’).
זה יותר קשור למנגנונים פנימיים ושיטות פעולה. בסוף, בתוך הדאטה שכל מודל אומן עליו יש מלאא מידע שגוי ולא איכותי, אבל זה לא בהכרח משפיע על הזיות. הזיות נוצרות גם כשמודל רוצה “לרצות” את המשתמש, לא יודע לשלוף תשובה נכונה ו”מרגיש” שהוא “חייב” לתת תשובה שקרובה למה שהוא תופס כנכון בעיניו…
וזה באמת על קצה המזלג…
מה הדירוג של PERPLEXITY?