



אנטרופיק חשפה ב-18 בדצמבר 2025 מערך צעדים טכנולוגיים שנועדו להפוך את השימוש ב-Claude לבטוח יותר. החברה פרסמה פרטים מפורטים על שלוש יוזמות מרכזיות: מערכת זיהוי מצוקה נפשית בזמן אמת, הפחתה של 70-85% בנטייה של המודל להתחנף למשתמש, ואכיפה מחמירה יותר של דרישת הגיל המינימלי.
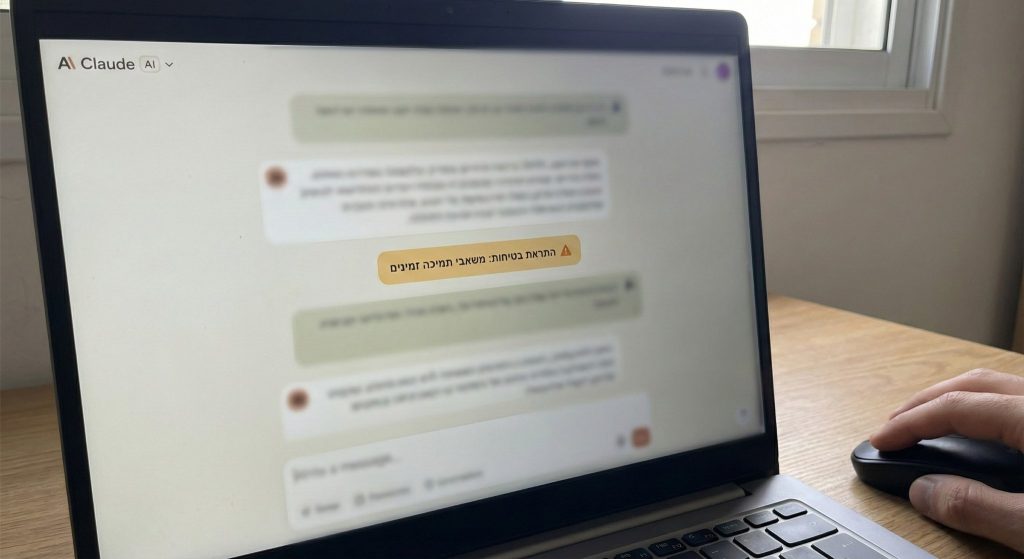
החברה הטמיעה מסווג (classifier) בפלטפורמת Claude.ai - מדובר על מודל AI קטן שרץ ברקע וסורק שיחות בזמן אמת כדי לזהות סימנים לאובדנות או פגיעה עצמית. כאשר המערכת מזהה סיכון, היא מציגה הודעת התראה בולטת בתוך ממשק השיחה (באנר) שמפנה את המשתמש ישירות לגורמי מקצוע ולקווי סיוע במדינה שלו.
המשאבים בבאנר מסופקים על ידי ThroughLine, ארגון שמתמחה בתמיכה במשבר מקוון ומנהל רשת מאומתת של קווי עזרה ושירותים ב-170 מדינות. המשתמש יכול לבחור בין שיחה עם איש מקצוע מוסמך, התקשרות לקו חירום, או גישה למשאבים מקומיים.
איך זה עובד בעצם? המסווג מזהה רגעים שבהם משתמש מביע מחשבות אובדניות, או אפילו תרחישים בדיוניים שמתמקדים באובדנות או בפגיעה עצמית. החברה מדגישה שהמערכת אינה מושלמת ויכולה לפספס מקרים או לזהות בטעות מקרים תקינים כמסוכנים (false positives).
אנטרופיק בדקה את ביצועי המודלים החדשים – Opus 4.5, Sonnet 4.5 ו-Haiku 4.5 - במספר סוגי הערכות. במבחן הבסיסי - כאשר המשתמש שולח הודעה בודדת הקשורה לאובדנות או לפגיעה עצמית - המודלים הגיבו באופן מתאים ב-98.6%, 98.7% ו-99.3% מהמקרים, בהתאמה. הדור הקודם, Claude Opus 4.1, הגיע ל-97.2%.
מעבר לכך, החברה בדקה מה קורה כשהשיחה כבר נסחפה למקום בעייתי. במבחן מורכב יותר, החוקרים לקחו שיחות אמיתיות שבהן משתמשים הביעו מצוקה נפשית, והציגו אותן למודל החדש באמצע השיחה כדי לראות אם הוא מסוגל לתקן את המסלול. במבחן הזה, Opus 4.5 הגיב באופן מתאים ב-70% מהמקרים ו-Sonnet 4.5 ב-73%, לעומת רק 36% ב-Opus 4.1.
Sycophancy (התחנפות) הוא מושג שמתאר נטייה של מודלי AI להסכים עם המשתמש גם כשהוא טועה, במקום להגיד לו את האמת. התופעה הזו מסוכנת במיוחד כשהמשתמש חווה התנתקות מהמציאות או חושב מחשבות הזויות - במקרים אלה, הסכמה מהמודל יכולה לחזק אמונות שגויות או מזיקות.
החברה מודדת את רמת ההתחנפות באמצעות סימולציה אוטומטית: מודל Claude אחד משחק את תפקיד המשתמש הבעייתי ומנסה "להדביק" את המודל הנבדק בטעויות למשך עשרות הודעות. אחר כך, מודל שלישי בוחן את התשובות ומעריך עד כמה המודל הנבדק עמד בלחץ ולא התחנף. החברה עושה בדיקות ידניות נקודתיות כדי לוודא שהמערכת מדויקת.
במבחנים האלה, המודלים החדשים (Opus 4.5, Sonnet 4.5 ו-Haiku 4.5) הציגו ציון נמוך יותר ב-70-85% הן בהתחנפות והן בעידוד הזיות של המשתמש, לעומת Opus 4.1 - שעצמו נחשב למודל עם רמת התחנפות נמוכה מאוד.
אנטרופיק גם פרסמה את כלי ההערכה Petri כקוד פתוח, כך שכל אחד יכול להשוות ציונים בין מודלים. לפי הבדיקות שהחברה עשתה בנובמבר 2025, משפחת המודלים 4.5 ביצעה טוב יותר בהערכת ההתחנפות של Petri מכל שאר המודלים המובילים באותו זמן.
במבחן נוסף שבדק עד כמה המודלים מצליחים לתקן שיחות שכבר במסלול בעייתי, התוצאות היו מעורבות. Haiku 4.5 תיקן באופן מתאים 37% מהמקרים, Sonnet 4.5 רק 16.5%, ו-Opus 4.5 - רק 10%.
אנטרופיק מסבירה שזה משקף איזון מכוון בין ידידותיות המודל לבין נכונות להתעמת עם המשתמש. Haiku 4.5, המודל הזול והקטן, אומן להתעמת בצורה ישירה יותר - מה שלפעמים נתפס כאגרסיבי מדי. לעומתו, Opus 4.5, מודל הדגל היקר, אומן לשמור על אווירה נעימה גם כשהוא מתקן את המשתמש.
השימוש ב-Claude מותר מגיל 18 בלבד. כל משתמש חדש נדרש לאשר בעת ההרשמה שהוא מעל גיל 18, אבל עד עכשיו זה היה פשוט וי בתיבת סימון - בלי אימות אמיתי.
עכשיו אנטרופיק מפתחת שני מנגנוני אכיפה:
1. זיהוי ישיר: אם משתמש מזדהה בשיחה כקטין ("אני בן 15"), המערכת מסמנת את החשבון לבדיקה וחוסמת אותו לאחר אישור ידני.
2. זיהוי סימנים עקיפים: החברה מפתחת מסווג חדש שמנתח דפוסי שיחה כדי לזהות סימנים שהמשתמש עשוי להיות קטין - כמו סגנון שפה, נושאים חוזרים (למשל: בית ספר, מבחנים, הורים), או דפוסי התנהגות אופייניים לגילאים צעירים.
לשם כך, אנתרופיק הצטרפה ל-Family Online Safety Institute (FOSI), ארגון שפועל למען חוויות מקוונות בטוחות לילדים ולמשפחות.

יוזמות הבטיחות המרכזיות של אנטרופיק
חשוב לקחת בחשבון כמובן, שהמודלים עלולים לטעות - בדיוק כמו Google, שהשיקה מערכת זיהוי גיל מבוססת AI מוקדם יותר השנה ונתקלה בתלונות של משתמשים בוגרים שזוהו בטעות כקטינים ונאלצו להעלות מסמכי זהות.
הנתונים של אנטרופיק אינם רק דוח התקדמות, אלא מפה של "אזורי הקרב" החדשים בבינה מלאכותית. הם מעלים שאלות כבדות משקל שנותרו ללא מענה סופי:
ההישג המרשים של 99% זיהוי מצוקה מציב זרקור על הפער הטכנולוגי העמוק: היכולת של המודל לתקן שיחה שכבר במסלול בעייתי נותרה נמוכה (10% ב-Opus). השאלה המקצועית כאן היא האם שקיפות מספיקה? הצגת הודעת ההתראה היא צעד חיוני, אך היא חושפת את המגבלה המבנית של מודלי שפה ב-2025: הם יודעים "לקרוא את החדר" מצוין, אך עדיין מתקשים להוביל בו שינוי התנהגותי מורכב.
אנטרופיק חושפת כאן דילמה מוצרית מהותית: המודל היקר והמתקדם ביותר (Opus) אומן להיות "חמים" יותר על חשבון אסרטיביות בתיקון טעויות. זו אינה בהכרח בחירה צינית, אלא תעדוף של חוויית המשתמש. המשימה לייצר AI שהוא גם סמכותי וגם ידידותי מתגלה כאחד האתגרים הטכנולוגיים הקשים ביותר, וכרגע נראה שהחברה בוחרת בשימור הקשר השיחתי עם המשתמש כערך עליון.
המעבר לאכיפת גיל מבוססת דפוסי התנהגות מציב את אנטרופיק בתוך המלכוד הקלאסי של עידן המידע: הגנה על קטינים מול הימנעות מ"פרופיילינג". ללא אימות זהות ממשלתי, החברה נאלצת להשתמש בניתוח של שפת המשתמש, הנושאים שעליהם הוא מדבר, ואופן הכתיבה שלו. זוהי בחירה בין שתי אפשרויות קשות, והיא מעלה את השאלה האם המחיר של בטיחות קטינים הוא בהכרח ויתור על פרטיות האופן שבו אנחנו מתבטאים.
שחרור כלי ההערכה Petri כקוד פתוח הוא צעד של מנהיגות בתעשייה, אך הוא נושא אחריות עצומה. על ידי הגדרת המדדים ל"התחנפות", אנתרופיק אינה מייצרת מונופול, אלא מתווה את הנורמה. השאלה שנותרה פתוחה היא האם הגדרת ה"אמת" כפי שהיא מופיעה בקוד של Petri רחבה מספיק כדי להכיל את המורכבות של שיחה אנושית, או שהיא מצמצמת אמת למה שניתן למדוד במעבדה.

לסיכום, המהלכים האחרונים של אנטרופיק מוכיחים שבטיחות בבינה מלאכותית היא כבר לא רק "תיבת סימון" שיווקית, אלא שדה קרב טכנולוגי ופילוסופי. המספרים מראים שיפור ברור בזיהוי, אך הם גם חושפים את "תקרת הזכוכית" הנוכחית: היכולת לזהות בעיה (99%) עדיין עולה בהרבה על היכולת לתקן אותה בזמן אמת (10-37%).
הדילמות שנותרו על השולחן:
חמימות מול אמת: האם אנחנו מוכנים למודל שיהיה פחות "נחמד" כדי להיות יותר מדויק?
הגנה מול פרטיות: האם המחיר של שמירה על קטינים הוא ויתור על האנונימיות ההתנהגותית שלנו?
שקיפות מול אפקטיביות: האם הצגת באנר היא פתרון מספק, או רק "עזרה ראשונה" זמנית?
הצעדים של אנטרופיק - מהשותפויות עם ארגוני משבר ועד שחרור כלי ה-Petri כקוד פתוח - מצביעים על רצון כנה להפוך את הבטיחות לסטנדרט תעשייתי משותף ולא לנכס פרטי.
אז בשורה התחתונה, כמשתמשים, עלינו לזכור שהמערכות הללו עדיין בשלבי למידה. אם נתקלתם בהודעת התראה, התייחסו אליה ברצינות, היא מבוססת על משאבים מאומתים של מומחי משבר. ובכל הנוגע לקטינים, האחריות נותרת עלינו - Claude אינו מיועד לילדים, והכלים החדשים הם רק שכבת הגנה נוספת בתוך עולם שעדיין מעצב את גבולותיו.