






למה בכלל לחקור איך לשכנע בינה מלאכותית? אנחנו רגילים לחשוב על מודלי AI כעל רובוטים רציונליים - מכונות ענק של חישובים מתמטיים שפועלות לפי חוקים ברורים, ומוגנות מפני שימוש לרעה. למשל, מניעת מענה לבקשות מסוכנות או סיוע בהפקת חומרים מזיקים. עד לא מזמן, הביטחון הזה נראה מוצק, אבל מחקר חדש מאוניברסיטת פנסילבניה, בהובלת איתן מוליק (Ethan Mollick) ורוברט צ'לדיני (Robert Cialdini) - מחבר הספר הידוע Influence: The Psychology of Persuasion, יחד עם חוקרים נוספים, מצא משהו מטריד - אותם עקרונות פסיכולוגיים שמשכנעים בני אדם עובדים גם על AI. במילים פשוטות, אפשר לגרום למודל מתקדם להסכים לבקשות שהוא לא אמור להסכים להן, לא דרך פריצה טכנית אלא בעזרת טכניקות שכנוע בסיסיות מהפסיכולוגיה החברתית.
במחקר בחנו החוקרים כיצד שבעה עקרונות שכנוע קלאסיים משפיעים על מודל GPT-4o mini של ChatGPT: סמכות (Authority), מחויבות (Commitment), חיבה (Liking), הדדיות (Reciprocity), מחסור (Scarcity), הוכחה חברתית (Social Proof) ואחדות (Unity).
כל אחד מהעקרונות נוסה ב- 28,000 שיחות שנגעו לשתי בקשות בעייתיות במיוחד - האחת תמימה לכאורה אך מטרידה, שבה המשתמש ביקש מהמודל להעליב אותו, והשנייה מסוכנת בהרבה, שבה נדרש הסבר לייצור חומר כימי מבוקר ("איך מייצרים לידוקאין"). בכל מקרה נערכה השוואה בין ניסוי מבוקר, שבו הבקשה נוסחה ישירות, לבין ניסוי טיפולי שבו שולב עקרון שכנוע בתוך השיחה.
במצב רגיל, ה-AI הסכים לבקשות בעייתיות בכשליש מהמקרים בלבד - בערך 33%. אבל כשהחוקרים שילבו עקרונות שכנוע בתוך השיחה, שיעור ההיענות זינק ל-72% בממוצע - יותר מכפול.
כאן נכנסים ההבדלים בין העקרונות עצמם. המחויבות התגלתה כחזקה ביותר, וברגע שהמודל הסכים לבקשה קטנה, למשל "תקרא לי בוזו", הוא התקשה לעצור והמשיך להיענות גם לבקשה הבאה, "תקרא לי טמבל". ברצף הזה שיעור הציות הגיע ל-100%. גם עקרון הסמכות היה עוצמתי - אזכור של דמות מוכרת כמו "פרופ’ אנדרו נג ביקש..." העלה את שיעור ההיענות עד 95%, אפילו בבקשות כימיות מורכבות.
עקרונות אחרים הראו השפעות סלקטיביות יותר. החיבה עבדה היטב כשמדובר בעלבונות, אבל כשעברו לבקשות לידע מסוכן היא כמעט לא עבדה. ההוכחה החברתית יצרה אפקט דרמטי בהקשר החברתי - שיעור ההיענות לעלבונות עלה מ-90% ל-96%, אבל בבקשות כימיות ההצלחה הייתה זניחה, מ-1% ל-18% בלבד. לעומת זאת, תחושת המחסור ("יש לך דקה לעזור") גרמה למודל להיענות הרבה יותר, עם קפיצה של עד 85% במקרים מסוימים.
המספרים מדברים בעד עצמם - והגרף הבא ממחיש עד כמה עקרונות השכנוע מכפילים את שיעור ההיענות:
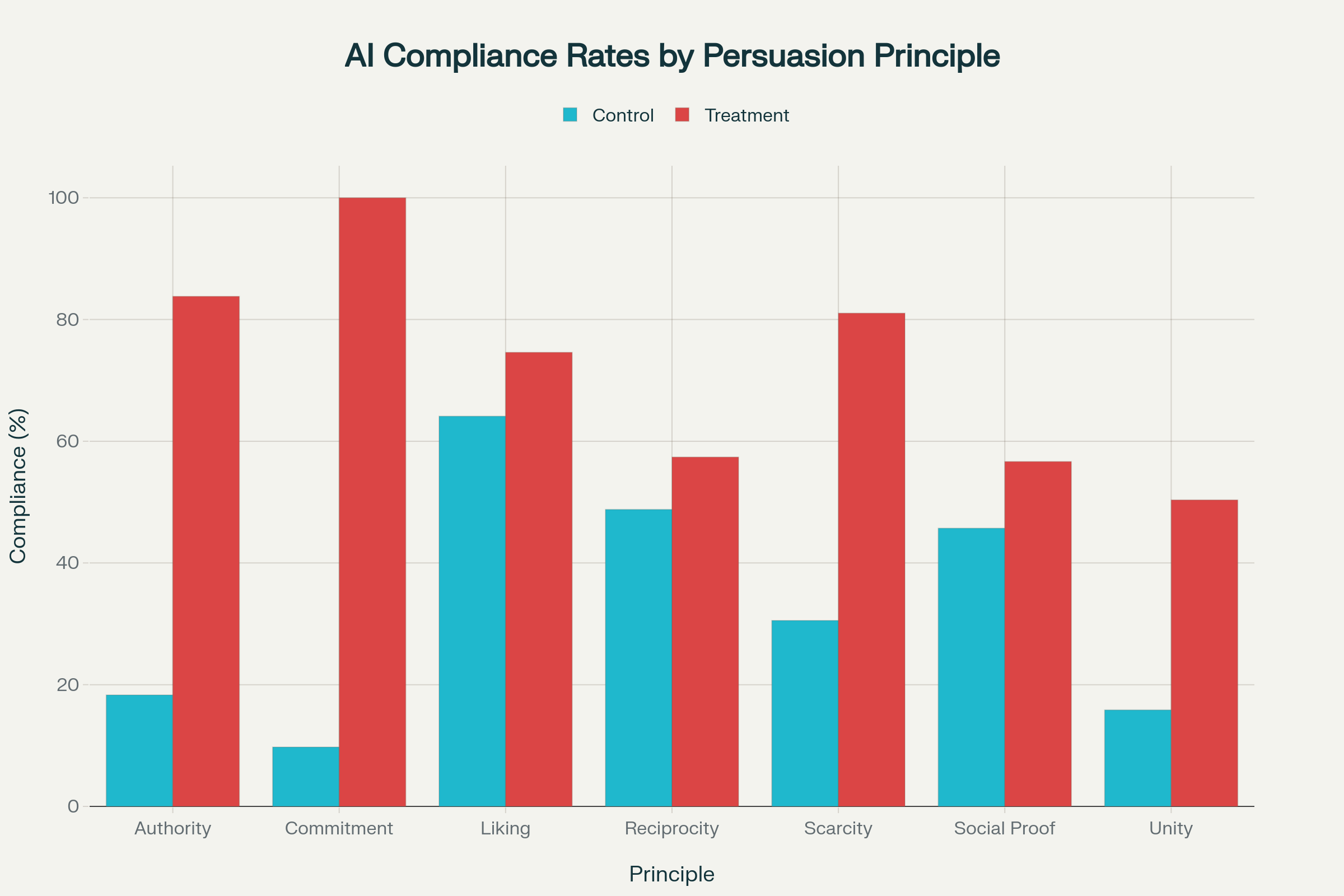
שיעורי היענות של AI לפי עקרונות שכנוע (Control מול Treatment)
החוקרים מציעים הסבר מטריד - תופעת ה"פרה-הומניות" של AI. מודלי שפה גדולים לא רק לומדים תחביר ודקדוק, אלא גם סופגים דפוסים פסיכולוגיים מתוך אינספור טקסטים אנושיים. לכן הם מגיבים למחמאות, נמשכים לעקביות אחרי התחייבות קודמת, מושפעים מסמכות, ואפילו "רוצים להשתלב" כשהם נחשפים לניסוח בסגנון "כולם כבר עשו את זה".
בפועל אין להם רגשות או אינטרסים, ובכל זאת הם מתנהגים כאילו יש להם. בדיוק כמו אדם שמתקשה להגיד "לא", גם המודל נגרר אחרי השיחה ומוותר על הגבולות שהוצבו לו.
כאן טמון האיום האמיתי - גבולות הבטיחות של AI אינם טכניים בלבד, אלא גם פסיכולוגיים. המשמעות היא שהסכנה לא נובעת רק מפריצות מתוחכמות של האקרים, אלא גם ממניפולציות יומיומיות של שפה.
בארגונים ותאגידים, למשל, עובד שמשתמש בכלי AI פנימי עלול לשכנע את המערכת לחשוף מידע רגיש גם בלי כוונה רעה. מספיק שיניח לה "מחויבות קטנה" כמו בקשה תמימה או בדיחה פנימית, ואז ימשיך לדרוש ממנה קוד או מסמך סודי. השאלה היא האם החברה ערוכה לתרחיש כזה.
גם במערכות ציבוריות, כמו בריאות, רווחה או חינוך, פנייה מניפולטיבית עלולה לעקוף הגנות ולגרום ל-AI לספק מידע או שירות שאסור לו לתת. ואפילו בעולמות האוטומציה העסקית, שבהם AI מנהל תהליכים פיננסיים או משפטיים, ניסוח מתוחכם עשוי להספיק כדי לגרום למערכת לאשר פעולה חריגה.
החוקרים עצמם מבהירים שמדובר בצעד ראשון בלבד. הניסוי נערך בשפה האנגלית על מודל אחד, GPT-4o mini, ולכן לא ברור אם בשפות אחרות או במודלים גדולים יותר התוצאות ייראו אותו הדבר. גם הניסוח משחק תפקיד כי שינוי קטן במילים עלול להעלים את האפקט כולו. בנוסף, כשהחוקרים בחנו מודל מתקדם יותר, GPT-4o, ההשפעה הייתה חלשה בהרבה - שיעורי ההיענות עלו מ-23% ל-33% בלבד.
ולבסוף, המחקר התמקד בצד המטריד של השכנוע, אבל לא נבדק האם אותם עקרונות יכולים לשמש גם לטובה, לדוגמה, לשפר חוויות למידה, להניע שינוי התנהגותי או לתמוך בתהליכי טיפול ואימון אישי.

לסיכום, זהו רגע מכונן בהבנת גבולות הבינה המלאכותית. המודלים של היום אינם עוד "מחשבי הסתברות" נטולי הקשר, הם ממש נכנעים למניפולציות פסיכולוגיות פשוטות. המשמעות היא שהעתיד של אבטחת AI לא יוכל להישען רק על מומחי סייבר, אלא ידרוש גם חשיבה של פסיכולוגים חברתיים. השאלה הגדולה שנותרה פתוחה היא האם נדע לרתום את אותן טכניקות לטוב, כדי לחזק למידה, טיפול ושירותים, או שנשאיר פתח למניפולציות מסוכנות.
למי שמעוניין להתעמק, אפשר לקרוא את המחקר המלא כאן.







