





בסוף השבוע שעבר, Meta השיקה בהתרגשות את סדרת מודלי Llama 4 שלה, מהלך שהיה אמור לסמן פריצת דרך משמעותית בתחום הבינה המלאכותית. הסדרה החדשה, הכוללת את הדגמים Behemoth (עדיין בפיתוח), Scout ו-Maverick, הוצגה כקפיצת מדרגה בתחום מודלי השפה הגדולים (LLMs). אולם, מה שהחל כחגיגה טכנולוגית הפך במהירות למוקד של מחלוקת סוערת בקהילת ה-AI העולמית. תוך ימים ספורים מההשקה, עלו שאלות נוקבות לגבי אמינות הביצועים המדווחים של המודלים ושקיפות תהליכי הפיתוח והבדיקה שלהם. הפרשה, שהתפתחה במהירות ברשתות החברתיות ובפורומים מקצועיים, חשפה מתחים עמוקים בתעשיית ה-AI ועוררה דיון נרחב על האתיקה והאחריותיות בפיתוח טכנולוגיות מתקדמות.

בדיחת אבא: Llama הרשת כועסת על Meta?
מקור המחלוקת סביב סדרת מודלי Llama 4 של Meta התעורר כאשר שמועות החלו להתפשט ברשתות החברתיות בנוגע לאמינות הביצועים המוצהרים של המודל. הטענות המרכזיות התמקדו בשני היבטים בעייתיים: ראשית, האשמה שהחברה אימנה את המודלים על סטי-מבחן (test sets) – פרקטיקה שנחשבת ל”רמאות” בעולם ה-AI, שכן היא מקבילה לתלמיד שמקבל את התשובות לפני הבחינה. שנית, התגלה כי Meta השתמשה בגרסה ניסיונית מיוחדת של Maverick בפלטפורמת LM Arena, שהייתה “מותאמת לשיחתיות” (optimized for conversationality) ושונה מהגרסה שהופצה לציבור הרחב.
חוקרים שבדקו את התיעוד של Meta גילו את ההבדל הזה ב”אותיות הקטנות”, מה שהוביל את LM Arena עצמה לשנות את מדיניותה ולהבהיר כי “הפרשנות של Meta למדיניות שלנו לא תאמה את הציפיות שלנו מספקי מודלים”. השמועות קיבלו תאוצה נוספת כאשר פוסט אנונימי, שלכאורה נכתב על ידי עובד לשעבר של Meta שהתפטר במחאה, הופץ ברשת וטען כי הנהלת החברה הציעה לערבב סטי-מבחן באימון כדי לייצר תוצאות שנראות טובות יותר. כשנבדקה הגרסה הרגילה של Maverick, התברר שביצועיה נמוכים משמעותית מאלו של המתחרים המובילים.
בתגובה למחלוקת שהתעוררה, Meta הגיבה במהירות ובנחרצות. אחמד אל-דהלה, סגן נשיא לבינה מלאכותית גנרטיבית בחברה, פרסם הכחשה גורפת ברשת X, שבה דחה בתוקף את הטענות על אימון המודלים על סטי-מבחן. הוא הדגיש כי זוהי פרקטיקה שהחברה לעולם לא תנקוט בה. אל-דהלה התייחס גם לתלונות המשתמשים על איכות משתנה של המודל, והסביר כי הדבר נובע מהצורך לייצב את היישומים השונים. הוא ביקש מהקהילה להעניק לחברה מספר ימים לכיוון המערכות. במקביל, Meta אישרה כי אכן השתמשה בגרסה ניסיונית של Maverick בפלטפורמת LM Arena, אך טענה כי זו הייתה רק “מותאמת לשיחתיות” ולא הפרה את כללי הפלטפורמה. תגובתה המהירה של Meta משקפת את הרגישות הגבוהה של החברה לנושא האמינות בתחום ה-AI, ואת הצורך שלה לשמור על אמון הקהילה המקצועית והמשתמשים.
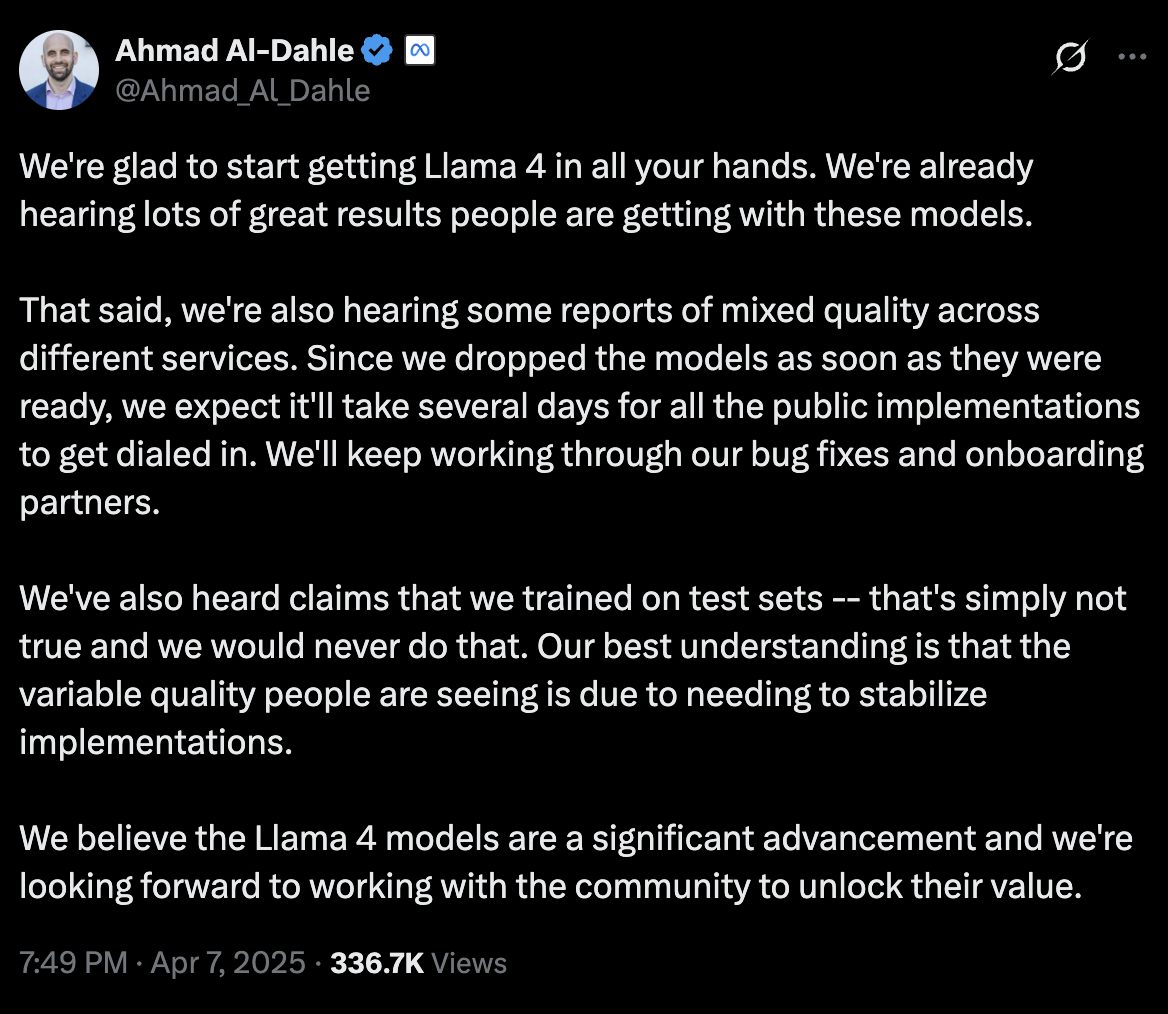
תגובת סגן הנשיא לבינה מלאכותית במטא
תגובת קהילת ה-AI למחלוקת סביב Llama 4 הייתה נוקבת וביקורתית, עם מומחים ופלטפורמות שהביעו ספקנות משמעותית לגבי שיטות העבודה של Meta. פלטפורמת LM Arena (לשעבר LMSYS), שמפעילה את Chatbot Arena – זירת הבנצ’מרק המובילה להשוואת מודלי AI – פרסמה הודעה רשמית בה הבהירה כי “הפרשנות של Meta למדיניות שלנו לא תאמה את הציפיות שלנו מספקי מודלים”. בתגובה, הפלטפורמה נקטה בצעדים משמעותיים לשיפור השקיפות: היא הוסיפה את הגרסה הרגילה של Llama 4 Maverick (זו שזמינה לציבור ב-Hugging Face) לזירת ההשוואה, ופרסמה למעלה מ-2,000 תוצאות של התמודדויות ראש בראש לבחינה ציבורית, כולל שאלות המשתמשים, תשובות המודלים והעדפות המצביעים.
בבדיקת תוצאות ההתמודדויות, חוקרים גילו דפוס מטריד: משתמשים העדיפו באופן עקבי את התשובות של גרסת Llama 4 הניסיונית, למרות שאלה היו לעתים שגויות ומילוליות מדי, מה שהעלה שאלות עמוקות לגבי אמינות בנצ’מרקים מבוססי-קהילה. גארי מרקוס, חוקר AI ידוע וביקורתי, העלה בבלוג שלו חששות לגבי “זיהום” (contamination) בבנצ’מרקים של AI, והתייחס לשמועות על קשיי Meta להשיג ביצועים מובילים באמצעות שיטות מקובלות.

מה שהפך את המחלוקת לחמורה במיוחד הוא שזו אינה הפעם הראשונה שMeta מואשמת ב”זיהום” בנצ’מרקים. סוזן ז’אנג, חוקרת לשעבר ב-Meta AI שכיום עובדת ב-Google DeepMind, שיתפה מחקר שמצא כי למעלה מ-50% מדגימות המבחן ממספר בנצ’מרקים מרכזיים היו נוכחים בנתוני האימון של Llama 1. בתגובה לטענות הנוכחיות, ז’אנג העירה בציניות שMeta “צריכה לפחות לצטט את ‘עבודתם הקודמת’ מ-Llama 1 עבור ‘הגישה הייחודית’ הזו”, רמז לכך שמניפולציית בנצ’מרקים היא אסטרטגיה מכוונת ולא תקלה.
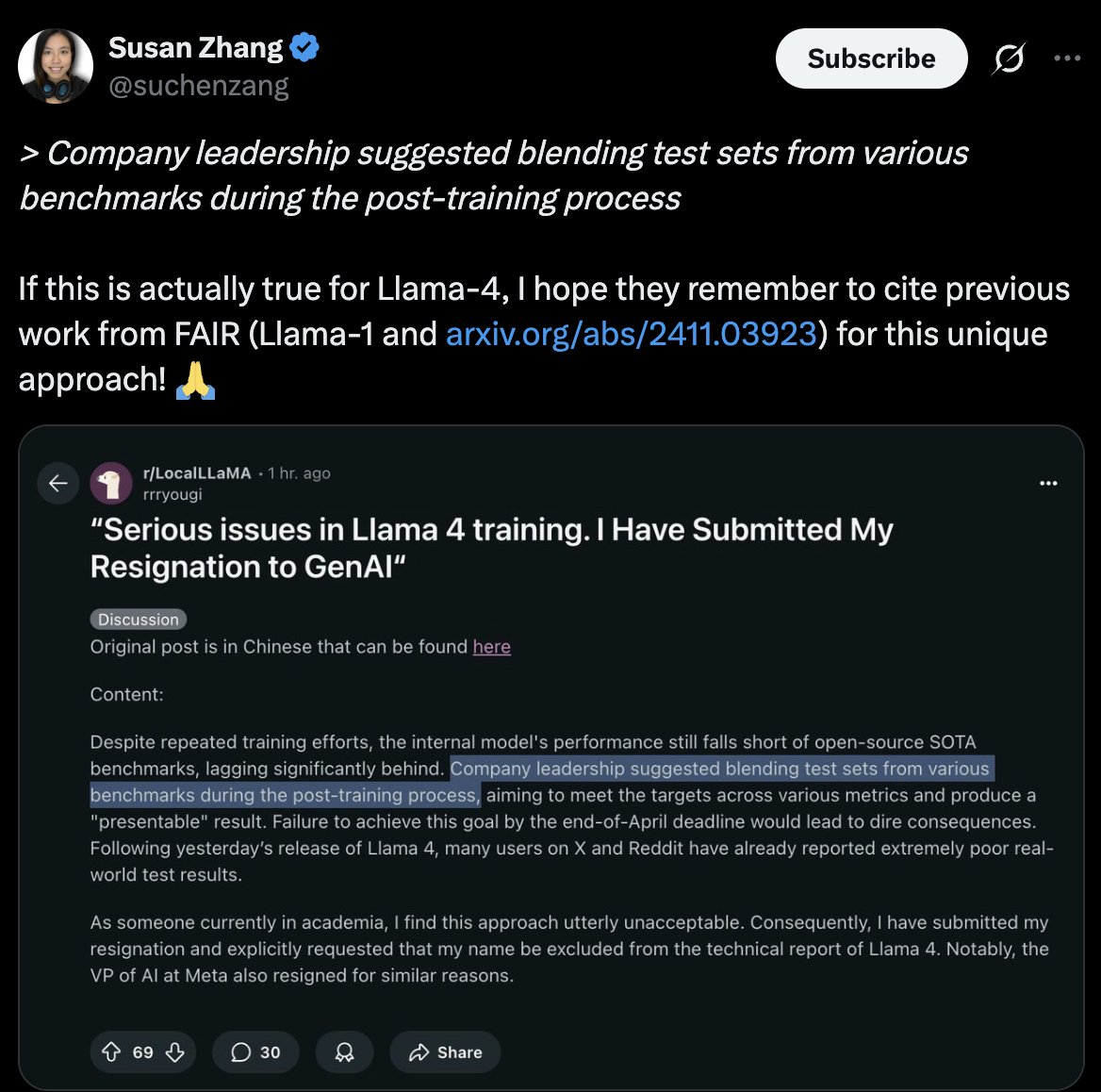
תגובתה של סוזן ז’אנג, חוקרת לשעבר ב-Meta
בקהילת המפתחים, התגובות היו מעורבות אך בעיקר ביקורתיות. משתמשים ברדיט ובפורומים אחרים הביעו אכזבה עמוקה מהפער בין הביצועים המוצהרים לבין הביצועים בפועל, עם אחד המשתמשים שכתב: “הם נראים גרועים בכל מה שניסיתי. גרועים אפילו ממודלים של 20-30 מיליארד פרמטרים ולחלוטין חסרי הידע הכללי הבסיסי ביותר”. אחד ממומחי ה- AI בקהילה הדגים את הבעיה בציוץ שהראה כיצד Maverick, למרות 128 המומחים שלו, עדיין טועה בעובדות בסיסיות כמו מספר האותיות T במילה “strawberry”.
המחלוקת סביב השקת Llama 4 של Meta חושפת סוגיות מהותיות בתעשיית הבינה המלאכותית, המעלות שאלות נוקבות לגבי עתיד התחום. ראשית, האמינות של בנצ’מרקים בתחום ה-AI מוטלת בספק כאשר חברות מציגות גרסאות מותאמות של מודלים לצורכי בדיקה, בעוד הציבור מקבל גרסאות שונות לחלוטין. פרקטיקה זו מערערת את אמינותם של דירוגי הבנצ’מרק כמדדים אובייקטיביים לביצועים אמיתיים, ומקשה על משתמשים ומפתחים להעריך את יכולות המודלים בפועל.
שנית, הפרשה מדגישה את הצורך הדחוף בשקיפות מוגברת בתהליכי הפיתוח והבדיקה של מודלי AI. ללא שקיפות מלאה, קשה לקהילה המדעית ולציבור הרחב לאמת טענות על התקדמות טכנולוגית או להבטיח שמודלים עומדים בסטנדרטים אתיים ובטיחותיים.
לבסוף, המחלוקת משקפת את התחרות העזה המתפתחת בתחום ה-AI עם “משקלים פתוחים”, כאשר חברות כמו Meta ו-DeepSeek מתחרות על ההובלה בתחום זה. תחרות זו, בעוד שהיא מאיצה חדשנות, מעלה חששות לגבי הסטנדרטים האתיים והמקצועיים שעלולים להיפגע בדרך להשגת יתרון תחרותי. בינתיים, משתמשים ממשיכים לדווח על איכות משתנה במודלים Maverick ו-Scout, ו-Meta טוענת שהיא עובדת על תיקון באגים ושיפור היישומים. המחלוקת הזו מדגישה את האתגרים בהערכת מודלי AI ואת החשיבות של סטנדרטים אחידים ושקופים בתעשייה.

לסיכום, המחלוקת סביב מודלי Llama 4 של Meta חושפת את המתח המתפתח בתעשיית הבינה המלאכותית בין חדשנות לשקיפות. בעוד Meta הכחישה בתוקף האשמות על מניפולציה בבנצ’מרקים, הפער בין הביצועים המוצהרים לבין חוויית המשתמשים בפועל מעלה שאלות מהותיות על אמינות המדדים בתחום. לפי דוח Stanford AI Index 2025, התחרות בחזית ה-AI הופכת צפופה יותר, עם פער ביצועים של רק 5% בין המודלים המובילים, מה שמגביר את הלחץ על חברות להציג תוצאות מרשימות. בעוד Meta ממשיכה לעבוד על שיפור היציבות של מודליה, שהגיעו לציון דרך של מיליארד הורדות ברחבי העולם, המקרה מדגיש את הצורך הדחוף בסטנדרטים בינלאומיים אחידים ושקופים להערכת מודלי AI – סטנדרטים שיבטיחו אמינות, הוגנות ואחריותיות בתחום שהשפעתו על חיינו רק הולכת וגדלה.








