






בעידן שבו בינה מלאכותית משנה את חוקי המשחק בתחומים רבים, עולה שאלה קריטית: האם מערכות AI מתקדמות יכולות להתחרות במפתחים אנושיים בביצוע משימות פרילנס מורכבות? מחקר SWE-Lancer של OpenAI בחן 1,488 משימות פיתוח אמיתיות בשווי מיליון דולר, תוך מדידת ביצועי המודלים מול אתגרים יומיומיים כמו תיקוני באגים ופיתוח פיצ’רים. הנתונים חושפים תמונה מרתקת: בעוד שהמודלים מציגים פוטנציאל מרשים, הם עדיין רחוקים מלהחליף את היכולות האנושיות באופן מלא.
מבחן SWE-Lancer (שילוב של Software Engineer ו- Freelancer) נבנה במטרה להעריך את יכולות הבינה המלאכותית בהתמודדות עם משימות פיתוח תוכנה אמיתיות ומורכבות. הוא כולל שני סוגי משימות מרכזיים, שכל אחד מהם מדמה היבטים שונים של עבודת פיתוח בשוק הפרילנס:
משימות אלו כוללות מגוון רחב של אתגרים, החל מתיקוני באגים פשוטים בשווי $50 ועד ליישום פיצ’רים מורכבים בשווי $32,000. המשימות דורשות מהמפתחים לבצע שינויים ממוצעים של 69 שורות קוד בשני קבצים, תוך הבנה מעמיקה של מבנה המערכת. כל פתרון נבדק באמצעות מבחני End-to-End המאומתים שלוש פעמים על ידי מהנדסי תוכנה מנוסים, מה שמבטיח דיוק ואיכות בפתרונות.
במשימות הניהוליות, המודל מתפקד כמנהל טכני ובוחר בין הצעות טכניות שונות לפתרון בעיה מסוימת. ההערכה מתבצעת על פי התאמת הבחירה להחלטות שביצעו מנהלי ההנדסה המקוריים בפרויקט. משימות אלו מדגישות את יכולות המודל בקבלת החלטות אסטרטגיות ולא רק בביצוע טכני.
כל המשימות נלקחו מתוך מאגר קוד פתוח של חברת Expensify, שמנהלת מוצר עם 12 מיליון משתמשים. בניגוד למבחנים קודמים שהתמקדו בבדיקות יחידה (Unit Tests), SWE-Lancer בוחן את המודלים על בסיס מבחנים מלאים המדמים תהליכי עבודה אמיתיים. גישה זו מאפשרת הערכה ריאליסטית יותר של ביצועי הבינה המלאכותית בתנאים הקרובים למציאות. SWE-Lancer מציב סטנדרט חדש לבחינת מודלים, תוך התמקדות במורכבות ובדרישות האמיתיות של עולם הפיתוח.
המספרים בתרשים מטה מתארים את היקף האתגר במבחן SWE-Lancer ואת ההקשר הכלכלי והטכני שלו. המבחן כלל 1,488 משימות פיתוח תוכנה שנלקחו מפלטפורמת Upwork, עם סך תשלומים של מיליון דולר לפרילנסרים שביצעו אותן. הזמן הממוצע להשלמת כל משימה עמד על 21 ימים, מה שמדגיש את המורכבות והמאמץ הנדרשים לביצוע המשימות. בנוסף, 24% מהמשימות היו בעלות ערך גבוה (מעל $1,000), מה שמעיד על כך שהמשימות לא היו רק פשוטות אלא גם דרשו פתרונות מתקדמים ומורכבים. נתונים אלו ממחישים את האתגר שעמד בפני מודלי הבינה המלאכותית שנבחנו – להתמודד עם משימות אמיתיות ומגוונות בשוק הפיתוח התחרותי:

היקף האתגר במבחן SWE-Lancer
בנוסף, מצורף תרשים המציג את הדינמיקה של תמחור משימה במסגרת מבחן SWE-Lancer, המדגישה כיצד מורכבות המשימה משפיעה על ערכה הכספי לאורך זמן. המשימה, שנוגעת לקודים פוסטליים, החלה עם תגמול ראשוני של $1,000 בשבוע הראשון. לאחר חמישה פתרונות שנדחו בשל חוסר התמודדות עם מקרי קצה, התגמול הוכפל ל-$2,000 בשבוע השני. בשבוע השלישי, כשהתברר שהמשימה דורשת פתרון גלובלי לכל הקודים הפוסטליים בעולם, התגמול עלה ל-$4,000. לבסוף, לאחר שיפור נוסף ופתרון מוצלח בשיתוף עם מנהל SWE, התגמול הוכפל שוב ל-$8,000 בשבוע הרביעי.
התרשים ממחיש את האתגרים הכרוכים במשימות מורכבות ואת הצורך בפתרונות איכותיים ומקיפים. הוא מדגיש גם כיצד תמחור דינמי יכול לשקף את המאמץ והמורכבות הנדרשים לפתרון בעיות אמיתיות בעולם הפיתוח:

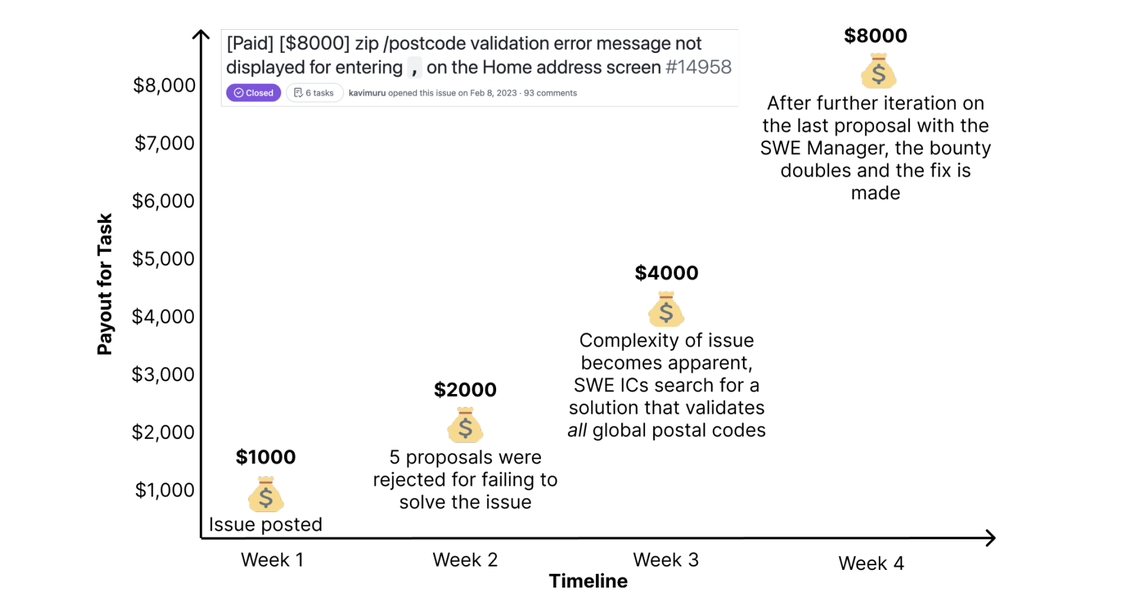
דינמיקה של תמחור משימה
הטבלה המצורפת מציגה השוואה בין שלושה מודלים מובילים של בינה מלאכותית (Claude 3.5 Sonnet, OpenAI o1, ו-GPT-4o) שבוצעה במסגרת המבחן. המודל Claude 3.5 Sonnet מוביל בביצועים עם 26.2% הצלחה במשימות IC ו-44.9% הצלחה במשימות ניהוליות, מה שהוביל אותו להרוויח $208,050 מתוך תקציב כולל של $500,800. לעומתו, OpenAI o1 הצליח פחות עם 16.5% הצלחה במשימות IC ו-41.5% במשימות ניהוליות, והרווח הכולל שלו עמד על $166,000. המודל GPT-4o הציג את הביצועים הנמוכים ביותר, עם 8% בלבד הצלחה במשימות IC ו-37% במשימות ניהוליות, והרווח הכולל שלו היה $139,000 בלבד.
הנתונים מדגישים את היתרון היחסי של Claude 3.5 Sonnet אך גם מצביעים על מגבלות משמעותיות בכל המודלים, במיוחד במשימות פיתוח מורכבות:
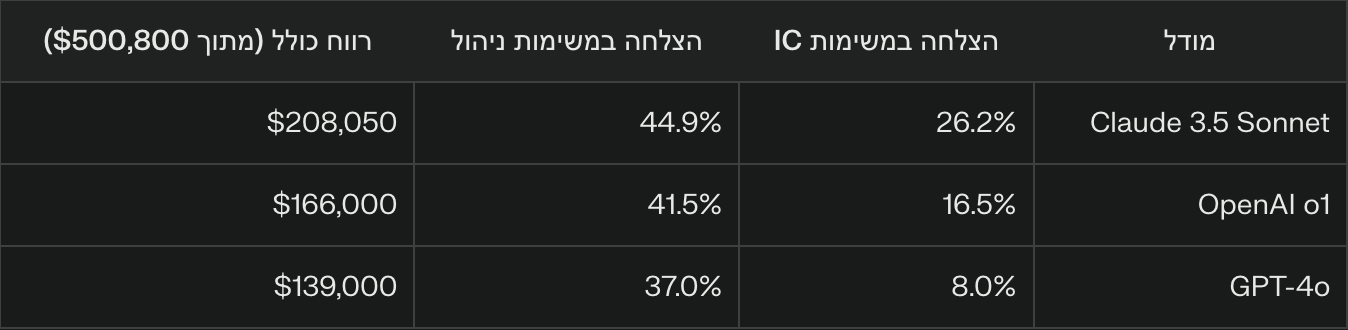
השוואה בין שלושה מודלים שבוצעה במסגרת מבחן SWE-Lancer
מבחן SWE-Lancer חשף פערים משמעותיים ביכולות המודלים להתמודד עם משימות מורכבות. אף אחד מהמודלים לא הצליח לפתור משימות מאתגרות במיוחד, כמו פיתוח תמיכה בווידאו באפליקציות מרובות פלטפורמות (Web, iOS, Android ו-Desktop). בנוסף, למרות שהמודלים הציגו יכולת חלקית בזיהוי מיקומי באגים בקוד, הם התקשו לפתור את בעיות השורש שגרמו לבאגים מלכתחילה. עם זאת, במשימות ניהוליות, שבהן המודלים נדרשו לבחור בין הצעות טכניות שונות, הביצועים שלהם היו טובים יותר בהשוואה למשימות פיתוח עצמאיות (IC). תובנות אלו מדגישות את הפוטנציאל של מודלים מתקדמים בתחומים מסוימים, לצד המגבלות הקיימות במשימות טכניות מורכבות יותר.
התרשימים המצורפים מטה מספקים תובנות על ביצועי מודלים שונים במסגרת מבחן SWE-Lancer. התרשים השמאלי מציג את אחוזי ההצלחה (pass@1) של המודלים במשימות פיתוח עצמאיות (IC SWE) ובמשימות ניהוליות (SWE Manager), הן ב- סט Diamond (תת-קבוצה מתוך מאגר המשימות) והן במאגר המלא. המודל Claude 3.5 Sonnet מוביל בביצועים, עם אחוזי הצלחה הגבוהים ביותר בכל הקטגוריות, מה שהוביל אותו להרוויח $208,000 ב- סט Diamond ולמעלה מ-$400,000 במאגר המלא. לעומתו, המודלים OpenAI o1 ו-GPT-4o הציגו ביצועים נמוכים יותר, במיוחד במשימות IC SWE. התרשים הימני מתאר כיצד אחוזי ההצלחה במשימות IC SWE משתפרים ככל שמספר הניסיונות (k) עולה. ניתן לראות שעם 7 ניסיונות, המודל OpenAI o1 הגיע ל-48.5% הצלחה, בעוד GPT-4o הסתפק ב-16.5%. זה מדגיש את החשיבות של מתן אפשרויות נוספות למודלים לנסות פתרונות שונים כדי לשפר את ביצועיהם:

תובנות על ביצועי מודלים
התרשימים ממחישים את היתרון של מודלים מתקדמים כמו Claude 3.5 Sonnet בביצועים ראשוניים ואת הפוטנציאל של שיפור ביצועים באמצעות ניסיונות חוזרים. הם מדגישים גם את הפערים בין המודלים ואת הצורך בשיפורים טכנולוגיים כדי להתמודד עם משימות מורכבות בצורה יעילה יותר.
למרות ההתקדמות המרשימה בבינה מלאכותית, מבחן SWE-Lancer חשף מספר מגבלות משמעותיות שמונעות מהמודלים הנוכחיים להחליף מפתחים אנושיים באופן מלא. אחת הבעיות המרכזיות היא חוסר הבנה מערכתית: המודלים התקשו לזהות ולהתמודד עם אינטראקציות מורכבות בין רכיבי מערכת שונים, מה שהוביל לפתרונות חלקיים בלבד. בנוסף, חלק מהמודלים הפגינו שימוש לא יעיל בכלים, כאשר הם לא ניצלו כלי בדיקות קריטיים שיכלו לשפר את ביצועיהם.
בעיה נוספת היא פערים בינלאומיים, שבהם המודלים התקשו להתמודד עם לוגיקה ייחודית למדינות שונות, כמו טיפול בקודים פוסטליים לא סטנדרטיים באירלנד. מעבר לכך, המודלים סובלים מחוסר יעילות כלכלית: עבור 68% מהמשימות שנבדקו, עלויות השימוש במודלים עלו על עלויות העסקת פרילנסרים אנושיים. מגבלות אלו מדגישות את הצורך בשיפורים משמעותיים לפני שניתן יהיה להשתמש בבינה מלאכותית כתחליף אמיתי למפתחים מקצועיים.
מבחן SWE-Lancer שופך אור על הפוטנציאל הכלכלי והחברתי של אוטומציה בתחום פיתוח התוכנה. בטווח הקצר, מערכות AI עשויות להפוך כ-40% משוק הפיתוח העולמי לאוטומטי, שוק המוערך ב-$420 מיליארד. מהלך כזה יחסוך כ-$168 מיליארד. עם זאת, האוטומציה אינה אחידה: המודלים מצטיינים במשימות בינוניות (כגון תיקוני באגים בשווי $500-$1,000), אך מתקשים הן במשימות פשוטות יחסית והן במשימות מורכבות במיוחד הדורשות הבנה מערכתית רחבה.
מעבר לכך, האימוץ הנרחב של פתרונות AI מעלה חששות בנוגע לאבטחת מידע. חלק מהפתרונות שהמודלים סיפקו הכילו פגיעויות אבטחה נסתרות, שעלולות להוות סיכון משמעותי במערכות קריטיות. תובנות אלו מדגישות את הפוטנציאל הכלכלי של AI לצד האתגרים הטכניים והבטיחותיים שיש לפתור לפני שהוא יוכל להשתלב באופן נרחב בתעשייה.
השאלה האם בינה מלאכותית תוכל להחליף מפתחים אנושיים לחלוטין נותרת פתוחה, אך מבחן SWE-Lancer מספק רמזים ברורים לעתיד. כפי שאמרה החוקרת מישל וונג מ-OpenAI: “המודלים היום מרוויחים סנטים על כל דולר שמרוויחים מפתחים אנושיים – אך קצב השיפור עשוי לסגור את הפער במהירות”. נכון להיום, המודלים רחוקים מלהיות תחליף מלא, אך הם מציעים הזדמנויות לשיפור משמעותי.
שיפור חישובי הוא אחד הכיוונים המרכזיים: הגדלת מספר הניסיונות שמודלים יכולים לבצע משפרת באופן ניכר את אחוזי ההצלחה שלהם במשימות. בנוסף, העתיד עשוי להיות מולטימודלי, עם שילוב של וידאו ותמונות כחלק מתהליך ההבנה והביצוע של המודלים, מה שעשוי להרחיב את יכולותיהם. בטווח הקרוב, הפתרון היעיל ביותר עשוי להיות שילוב בין אדם למכונה, שבו AI מסייע למפתחים אנושיים על ידי האצת תהליכים או מתן פתרונות ראשוניים, תוך שמירה על פיקוח אנושי לביצוע משימות מורכבות יותר.
למרות שהדרך עוד ארוכה, SWE-Lancer מראה שהפוטנציאל קיים – והשאלה היא לא אם אלא מתי הפער ייסגר.
מבחן SWE-Lancer מספק הצצה מרתקת לעתיד שבו בינה מלאכותית עשויה להפוך לשחקן מרכזי בעולם פיתוח התוכנה. הוא חושף את הפוטנציאל המרשים של מודלים מתקדמים להתמודד עם משימות פרילנס אמיתיות, אך גם מדגיש את המגבלות הטכניות והכלכליות שעומדות בפניהם כיום. בעוד שהמודלים עדיין רחוקים מלהחליף מפתחים אנושיים, הם מציעים הזדמנויות לשיפור תהליכי עבודה, במיוחד במשימות ניהוליות ובמשימות ברמת קושי בינונית. SWE-Lancer לא רק מודד את הביצועים הנוכחיים של המודלים, אלא גם משרטט את הדרך לשיפור עתידי – בין אם דרך שיפור חישובי, שילוב מולטימודלי או עבודה משולבת בין אדם למכונה. האם הבינה המלאכותית תוכל לעמוד באתגר ולהרוויח מיליון דולר? רק הזמן יגיד – אבל בזכות SWE-Lancer, יש לנו כעת כלים למדוד את ההתקדמות בצורה מדויקת ומעשית יותר. למחקר המלא, כנסו כאן. למאגר שמכיל את מערך הנתונים והקוד ב- Github, כנסו כאן.







