





מטא (פייסבוק) ממשיכה להתקדם במחקרי הבינה המלאכותית שלה ומציגה (שוב) סדרה חדשה של כלים מחקריים בקוד פתוח. בחברה מאמינים מאוד במודלים פתוחים וסדרת שחרורים זו מהווה שלב נוסף במאמצי צוות Meta FAIR לקדם בינה מלאכותית מתקדמת (AMI) תוך עידוד מדע פתוח ושיתוף נתונים ומשחררים אוסף של חידושים בבלוג שלהם. אז בשביל שיהיה לכולנו נוח, במאמר הזה נסקור בזריזות את כלל החידושים האחרונים, הסקירה הזו מיועדת לכל מי שעוסק בפיתוח בינה מלאכותית, אבטחת מידע או מחקר חומרים. בין אם אתם חוקרים, מפתחים או חלק מקהילת הקוד הפתוח, החידושים האחרונים האלה הם משהו שאתם צריכים להכיר.
מודל SAM 2.1 (Segment Anything Model) הוא כלי שמסייע לזהות ולסווג אובייקטים בתמונות ובווידאו בצורה אוטומטית, ללא צורך בתיוג ידני. הוא מאפשר לחוקרים ולמפתחים לבצע סגמנטציה של אובייקטים באופן מהיר ומדויק. הגרסה החדשה של המודל כוללת שיפורים משמעותיים לעומת הגרסה הקודמת. מאז שחרור SAM 2 לקהילת הקוד הפתוח, הוא הורד יותר מ-700,000 פעמים ונעשה בו שימוש במדעים שונים, כמו רפואה ומטאורולוגיה.
Credit: sam2.metademolab.com
בגרסה החדשה, SAM 2.1 מתמודד טוב יותר עם אובייקטים דומים וקטנים, בזכות שיפורי אלגוריתם ושיטות חדשות של אוגמנטציה (הרחבת נתונים). המודל מאומן על רצפים ארוכים יותר של פריימים ומציג ביצועים טובים יותר במקומות שהיו בעייתיים בעבר. מטא גם פרסמה את קוד המקור של ה-SAM Developer Suite, שמאפשר למפתחים להתאים את המודל לצרכים שלהם, לשנות את אופן האימון, ואף להשתמש בגרסה האינטרנטית שלו.

אחד החידושים הבולטים במוצרי Meta הוא Meta Spirit LM, מודל שפה מולטימודלי שמאפשר לשלב בין דיבור לטקסט. המודל מחליף את הצורך בטכנולוגיות שמבצעות המרת דיבור לטקסט וחזרה לדיבור. הוא גם שומר על האיכויות המילוליות והרגשיות של הדיבור האנושי. Meta Spirit LM מגיע בשתי גרסאות:
Spirit LM Base: משתמש בשיטות פונטיות ליצירת דיבור.
Spirit LM Expressive: כולל טוקנים של פיץ’ (Pitch) וסגנון כדי לשמר את הטון הרגשי של הדובר, כולל רגשות כמו כעס, הפתעה או שמחה.
המודל מאפשר משימות כמו זיהוי דיבור אוטומטי (ASR) והמרת טקסט לדיבור (TTS), וכל זאת תוך שמירה על האקספרסיביות של הדיבור. המודל שוחרר כמובן כקוד פתוח עם רישיון מחקרי לא מסחרי, כדי לאפשר לחוקרים לפתח את התחום ולבנות כלים חדשים שמנצלים את היכולות האלו.
מודלים גדולים בתעשייה ובאקדמיה דורשים משאבים רבים של זמן ואנרגיה. כדי להתמודד עם האתגר הזה, Meta פיתחה את Layer Skip, כלי שמאיץ את זמני הריצה של מודלים גדולים בלי צורך בחומרה או תוכנה מיוחדת. Layer Skip מאפשר לדלג על שכבות במהלך הריצה ולהשתמש בשכבות מאוחרות יותר לאימות ותיקון.

“לייר סקיפ” משפר את ביצועי המודל תוך שמירה על דיוק, ומאפשר שיפור של עד פי 1.7 בזמני הריצה. Meta שחררה את הקוד ואת המודלים שעברו אימון עם Layer Skip, כולל Llama 3, Llama 2 ו-Code Llama.
עולם הקריפטוגרפיה מתמודד עם אתגרים גדולים, ובעידן הקוונטי יש צורך לבחון שיטות הצפנה חדשות. כלי SALSA שפותח על ידי Meta נועד לאפשר לחוקרים לבדוק את החוסן של שיטות הצפנה מבוססות קריפטוגרפיה קוונטית. הכלי משתמש בבינה מלאכותית כדי לתקוף הצפנות ולחשוף פגיעויות חדשות. בעזרת הכלי, החוקרים יוכלו לגלות נקודות תורפה ולבנות מערכות מאובטחות יותר.
Meta פיתחה את Meta Lingua, פלטפורמה קלה לשימוש שנועדה לאפשר לחוקרים לאמן מודלים לשוניים גדולים בצורה יעילה ופשוטה. הפלטפורמה מותאמת לצרכים מחקריים, וכוללת קוד מקור מודולרי שניתן לשלב בפרויקטים קיימים כדי להאיץ את תהליכי האימון של המודלים. שיתוף הכלי מאפשר לחוקרים לבדוק רעיונות חדשים ולבצע ניסויים במינימום מאמץ טכני.
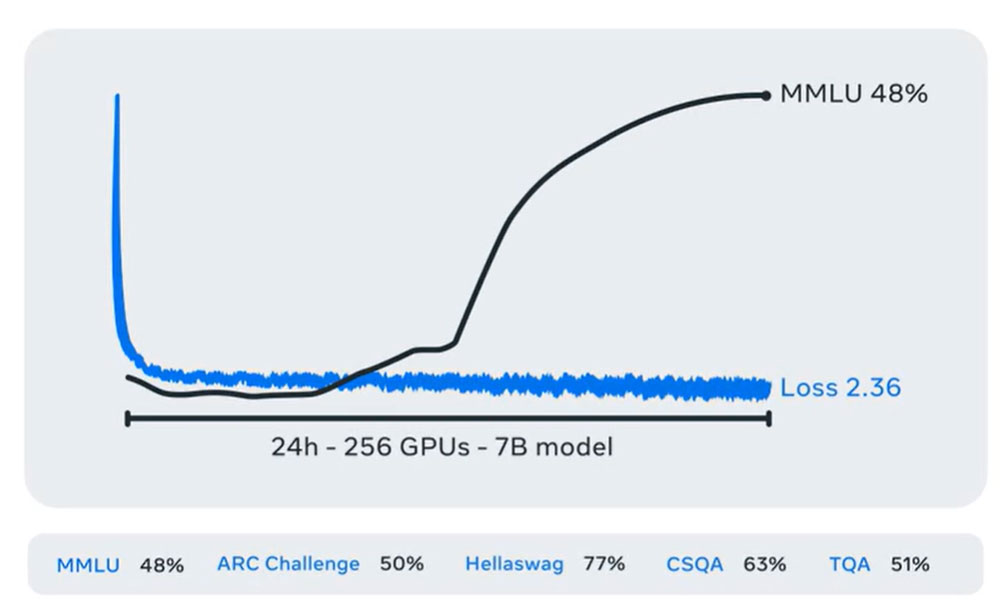
הביצועים של Meta Lingua במבחנים | Credit: Meta
התמונה מתארת את ביצועי המודל של Meta Lingua, עם גרף המציג את הירידה ב-Loss (הפסד) ואת העלייה בביצועים של המודל. המודל השיג תוצאה של 48% במבחן MMLU. נתון זה מתייחס למודל בעל 7 מיליארד פרמטרים, שהתאמן במשך 24 שעות תוך שימוש ב-256 GPUs.
בנוסף לכך, תוצאות הביצועים מוצגות במספר מבחני הערכה נוספים, בהם המודל השיג תוצאות מרשימות: 50% ב-ARC Challenge, 77% ב-HellaSwag, 63% ב-CSQA ו-51% ב-TQA. תוצאות אלה מדגישות את היכולות המחקריות הגבוהות של Meta Lingua, המספקת פלטפורמה יעילה ונגישה למחקר בתחום הבינה המלאכותית.
מעבר לדיוק ולביצועים, Meta Lingua עושה שימוש מיטבי בחומרה מתקדמת כמו כרטיס ה-H100, ומצליחה לעבד 9,600 טוקנים לשנייה עם נצילות חישובית של 45% מה-FLOPs של המודל. שילוב זה של מהירות עיבוד, דיוק וניצול יעיל של משאבים חישוביים מדגיש את מחויבותה של הפלטפורמה למודולריות, פשטות ושימוש חוזר, אשר מקדמים מחקר בינה מלאכותית במגוון רחב של יישומים ומאפשרים לבצע ניסויים בצורה מהירה וידידותית למשתמשים
גילוי חומרים חדשים הוא תהליך שיכול לקחת שנים רבות, אך בינה מלאכותית עשויה לקצר את הזמן הזה משמעותית. Meta משחררת את Meta Open Materials 2024, אחת ממערכות הנתונים הגדולות ביותר לגילוי חומרים חדשים. המערכת כוללת מאגר נתונים של 100 מיליון דוגמאות, ומטרתה לספק אפשרויות חדשות בגילוי חומרים אנאורגניים.
Meta מציגה גם את MEXMA, מקודד משפטים חדש שמבוסס על אובייקטים ברמת המשפט והטוקן. גישה זו מאפשרת עיבוד מדויק יותר של משפטים במודלים רב-לשוניים ומשפרת את הדיוק במשימות כמו סיווג משפטים.
מטא פיתחה את מודל Self-Taught Evaluator, שמייצר נתונים סינתטיים לצורך אימון מודלים, בלי צורך בהערות אנושיות. המודל מבצע אופטימיזציה ישירה ומשמש כמערכת להערכת מודלים אחרים בצורה מהירה ויעילה, ומוביל לשיפורים משמעותיים בביצועי המודלים שנבדקים. בסופו של דבר, Meta ממשיכה להוביל בתחומי הבינה המלאכותית עם הכלים החדשים הללו. כלים אלו מעניקים גישה לטכנולוגיה מתקדמת, ופותחים את הדלת בפני מפתחים וחוקרים ליצירת חדשנות מדעית.
אין ספק שכל יום יש משהו חדש ולפחות מהצד של מטא, לא נראה שזה הולך לעצור בזמן הקרוב. החברה ממשיכה לפתח טכנולוגיות ומודלי AI, ודוגלת בשיטת קוד פתוח והנגשת ידע וכלים להמונים ולמפתחים. זה לא ברור מאליו וזה בהחלט ראוי להערכה!









